Reduction Algorithms
Table of contents
- Implementing Dijkstra’s
- Dijkstra’s runtime
- Topological sort
- Topo sort algorithm
- Topo sort demo
- Reduction
- Seam carving
- Dijkstra’s optimizations
- Seam carving reduction
- DAG shortest paths
Implementing Dijkstra’s
Dijkstra’s runtime
Topological sort
Topo sort algorithm
Topo sort demo
Reduction
Problem decomposition refers to the problem-solving process that computer scientists apply to solve a complex problem by breaking it down into parts that can be more easily solved. Oftentimes, this involves modifying algorithm templates and combining multiple algorithm ideas them to solve the problem at hand: all of the design work in the projects have been designed with this process in mind.
However, modifying an algorithm template is just one way that we can solve a problem. An alternative approach is to represent it as a different problem, one that can be solved without modifying an algorithm. Reduction is a problem decomposition approach where an algorithm designed for one problem can be used to solve another problem.
- Modify the input so that it can be framed in terms of another problem.
- Solve the modified input using a standard (unmodified) algorithm.
- Modify the output of the standard algorithm to solve the original problem.
We’ve actually already seen part of a reduction algorithm. In Asymptotic Analysis, we discussed one method for detecting duplicates in an arbitrary (possibly unsorted) array: dup1 considered every pair of items in quadratic time. How might we design a faster approach for detecting duplicates? If we know an approach for detecting duplicates in a sorted array, then detecting duplicates in an unsorted array reduces to sorting that array and then running the much faster dup2 algorithm. In fact, there are many problems that reduce to sorting.
Are there any duplicate keys in an array of
Comparableobjects? How many distinct keys are there in an array? Which value appears most frequently? With sorting, you can answer these questions in linearithmic time [with merge sort]: first sort the array, then make a pass through the sorted array, taking note of duplicate values that appear consecutively in the ordered array.1
Designing a faster sorting algorithm not only helps the problem of sorting, but also every problem that reduces to sorting!
Question 1
True/False: Topological sort reduces to depth-first search.
Explanation
Note the difference between “problems” and “algorithms”.
We’ve introduced 4 graph problems in this course.
- s-t connectivity
- Unweighted shortest paths
- Weighted shortest paths
- Topological sorting
We’ve introduced 3 graph algorithms for solving graph problems.
- Breadth-first search
- Depth-first search
- Dijkstra’s algorithm
When we claim that “topological sort reduces to depth-first search”, we’re saying “problem A reduces to algorithm X.” But the way we’ve defined reduction expects a claim of the form, “problem A reduces to problem B.”
Claiming “problem A reduces to problem B” suggests that any algorithm for solving problem B could be used to solve problem A!
Robert Sedgewick and Kevin Wayne. 2011. Sorting Applications. Algorithms, Fourth Edition. https://algs4.cs.princeton.edu/25applications/ ↩
Seam carving
Dijkstra’s optimizations
Dijkstra’s algorithm computes a weighted shortest paths tree in a graph from a start vertex.
dijkstra(Graph graph, Vertex start) {
Map<Vertex, Double> distTo = new HashMap<>();
Map<Vertex, Vertex> edgeTo = new HashMap<>();
PriorityQueue<Vertex> perimeter = new PriorityQueue<>();
perimeter.add(start);
while (!perimeter.isEmpty()) {
Vertex from = perimeter.removeMin();
for (Edge edge : graph.neighbors(from)) {
Vertex to = edge.to();
double oldDist = distTo.getOrDefault(to, Double.INFINITY);
double newDist = distTo.get(from) + edge.weight();
if (newDist < oldDist) {
distTo.put(to, newDist);
edgeTo.put(to, from);
if (perimeter.contains(to)) {
perimeter.changePriority(to, newDist);
} else {
perimeter.add(to, newDist);
}
}
}
}
}
Question 1
Suppose we design a priority queue implementation where all methods run in worst-case constant time. Which of the following is the most descriptive worst-case runtime for Dijkstra’s algorithm using this priority queue in terms of the number of vertices |V| and the number of edges |E|?
- Θ(|V|)
- Θ(|E|)
- Θ(|V|log |V|)
- Θ(|E|log |E|)
- Θ(|V| + |E|)
- Θ(|V|log |V| + |E|log |V|)
- Θ(|V|log |E| + |E|log |E|)
Question 2
Suppose we wanted to speed-up Dijkstra’s algorithm for real-world routing by computing just a single-pair shortest path from a given start vertex to a given end vertex, rather than the shortest paths tree from the start to every other reachable vertex.
Consider the following implementation of this idea. The main addition is the commented if statement inside of the neighbors loop. Unfortunately, this implementation doesn’t work. Explain why the behavior isn’t correct and suggest a fix.
dijkstra(Graph graph, Vertex start, V end) {
Map<Vertex, Double> distTo = new HashMap<>();
Map<Vertex, Vertex> edgeTo = new HashMap<>();
PriorityQueue<Vertex> perimeter = new PriorityQueue<>();
perimeter.add(start);
while (!perimeter.isEmpty()) {
Vertex from = perimeter.removeMin();
for (Edge edge : graph.neighbors(from)) {
Vertex to = edge.to();
if (end.equals(to)) {
// edgeTo stores the shortest path from start to end
// Wait, but is this really always true?
return;
}
double oldDist = distTo.getOrDefault(to, Double.INFINITY);
double newDist = distTo.get(from) + edge.weight();
if (newDist < oldDist) {
distTo.put(to, newDist);
edgeTo.put(to, from);
if (perimeter.contains(to)) {
perimeter.changePriority(to, newDist);
} else {
perimeter.add(to, newDist);
}
}
}
}
}
Seam carving reduction
Consider the vertical seam carving problem. Each vertex represents a pixel in an image. Edges represent the cost to go from a pixel to its 3 downward neighbors. We want to compute a vertical seam, or a shortest path from any pixel in the top row to any pixel in the bottom row.
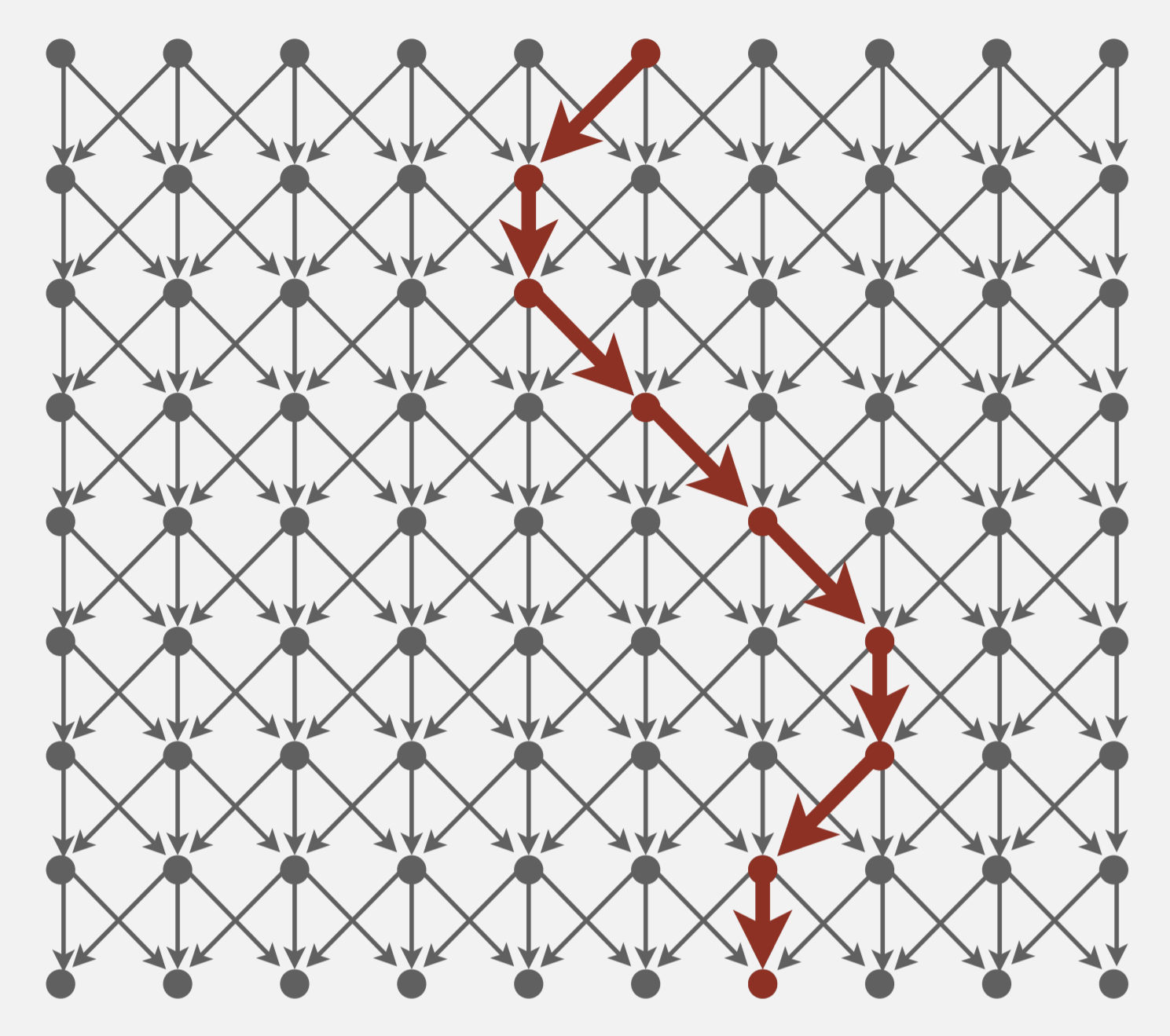
Question 1
In the seam carving pre-class preparation video, it was incorrectly claimed that “Seam carving reduces to Dijkstra’s.” Which of the following options are correct?
- Seam carving reduces to weighted shortest paths in a directed graph
- Seam carving reduces to weighted shortest paths in a DAG
- Weighted shortest paths in a directed graph reduces to seam carving
- Weighted shortest paths in a DAG reduces to seam carving
Question 2
Design a reduction algorithm for seam carving by answering the following 3 questions.
- How should we modify the input graph so that it can be solved with a shortest paths algorithm?
- Run Dijkstra’s shortest paths algorithm on the graph. Start from which node?
- How should we modify the shortest paths tree returned from Dijkstra’s to compute the result?
Dijkstra’s algorithm accepts a single start vertex. But seam carving can start from any pixel in the first row. How might we add a new node and edges to choose between the different starting pixels?
DAG shortest paths
Consider the following directed acyclic graph (DAG) with a negative edge weight. Dijkstra’s algorithm fails to compute the correct shortest path to H because A–B–H is closer to the start than A–D–E.
Question 1
Give a topological sorting for the above graph. (There are many possible answers.)
Question 2
Describe a reduction algorithm from DAG shortest paths to topological sorting. How can we use a topological sorting to compute the shortest path in a DAG, even if it has negative weights? Then, give the worst-case runtime for the algorithm.
Explanation
In Dijkstra’s algorithm, it would commit to B–H before considering the vertex E. In this reduction algorithm, notice how a topological sorting considers all vertices with edges to H before H itself!