CSE 163, Winter 2021: Assessment 4: Python Classes and Search Engines
Overview
At a high-level, a search-engine is an algorithm that accepts a query from the user, and computes how relevant a given document is to that query. The search engine can then rank documents according to their relevance.
In this assignment you will implement your own search engine by defining two classes, Documentand SearchEngine. The Document class represents a single file in the search engine, and the SearchEngine class handles the functionality of querying the collection of stored Documents. The SearchEngine will use the TF-IDF (term frequency - inverse document frequency) algorithm to compute the relevance of a document to a given term.
The purpose of this assignment is to introduce you to writing cohesive python classes. This will include public methods, private methods, and data structures stored as fields. Additionally, you will work with common indexing algorithms, and consider efficient ways to store data that will be frequently accessed by the TF-IDF algorithm.
You will probably find that this is the most challenging assignment of the whole quarter. The remaining assignments won't be as complex as this one so it's okay to feel a bit lost the first time you read over this spec. There are a lot of instructions and it gives guidance on how to develop this assignment in parts to this complexity.
This assignment is surely more complex than the others, so you will probably want to have a notesheet for you to gameplan with. At a high level there are three things you need to write for this project:
Documentclass indocument.py: See Part 0.SearchEngineclass insearch_engine.py: See Part 1 first and then implement Part 2.- Your testing program in
hw4_test.py: See Part 3.
Learning Objectives
This assessment will show students have mastery in the following skills:
- Write a complete Python class from scratch.
- This will include writing two classes which interact with each other.
- Implement basic Python classes to represent Documents and SearchEngines.
- Identify appropriate data structures to store/access term indexes efficiently.
- Understand fundamental document and term ranking algorithms to implement a basic search engine.
- Specifically the TF-IDF algorithm which computes term-frequency and inverse document frequency.
Expectations
Here are some baseline expectations we expect you to meet:
Follow the course collaboration policies
Files
The files included are:
main.py: A python file which will allow a user to run a new search engine at the command line. More information about this file is included later in the specification.small-wiki: This directory contains a smaller number of wikipedia files, and yourSearchEnginecan be used to query and rank the files.wikipedia: This directory contains a number of wikipedia files, and yourSearchEnginecan be used to query and rank the files. This directory is too large for Ed so it is only provided locally for you to try out for fun.hw4_test.py: The file you should put your tests fordocument.pyandsearch_engine.pyin.cse163_utils.py: A file where we will store utility functions for helping you write tests.
If you are working locally, you should download the starter code hw4.zip and open it as the project in Visual Studio Code.
If you are developing on Ed, you don't need to download anything. An important thing to note, is that on Ed the small-wiki directory is stored at the path /course/small-wiki.
The Algorithm
To implement the document ranking algorithm you will use the TF-IDF (term frequency- inverse document frequency) algorithm. This is just a fancy way of weighting documents based on their relevance to a search term. TF-IDF is one of the most popular term-weighting schemes - the vast-majority of text-based recommender systems use TF-IDF (Beel et al 2016).
The TF-IDF algorithm consists of two main computations. The following information describes these computations at a high-level, and the exact equations will be included later in the spec.
Term Frequency
The term frequency is computed on a document level, and it represents how often a search term appears in a specific document.
Inverse Document Frequency
Because filler words such as “the” are so common, term frequency tends to incorrectly weight documents that use the word “the” often. The inverse document frequency is a measure of how often the word appears in the entire set of documents. We then use this value to diminish the weight of terms that occur very frequently.
Optional: TF-IDF
You are only required to understand the information about the algorithm covered in the spec. For those interested, more information about TF-IDF can be found here.
Part 0: The Document Class
The Document class represents a single file in the SearchEngine, and will include functionality to compute the term frequency of a term in the document. Your Document class should have the following methods:
- An initializer that takes a path to a document (described in "Constructing a Document").
- A function named
get_paththat returns the path of the file thisDocumentrepresents. - A function named
term_frequencythat returns the term frequency of a given term (described in "Term Frequencies"). - A function named
get_wordsthat returns the list of the unique words in the document (described in "Getting the Words").
Part 0 Expectations
- You should create and implement a python file called
document.py - For this part of the assignment, you may import and use the
remodule (the use ofrewill be described later in the spec), but you may not use any other imports. - Your field(s) in this class should be private.
Constructing a Document
The initializer for the Document class should take a single file name as an argument. A new Document should be created to represent the document at the given path and to manage the terms in the original file. If the given file is empty, the Document that is constructed should represent an empty file. You may assume the given string represents a valid file.
Precomputing
Computing the information described in the following sections (e.g., term_frequency) for a document is a relatively inefficient process. We must iterate over the entire document to calculate the frequency of a single word. To make this process more efficient we should pre-compute the term frequencies of a document. The initializer should construct a dictionary which maps from terms (string) to their frequency in the document (floats). This will make sense after reading about the other methods you need to implement.
When you are constructing your dictionary of terms, all terms should be case insensitive and ignore punctuation. This means that “corgi”, “CoRgi”, and “corgi!!” are all considered the same term. You can use the following regular expression to remove punctuation from a string: token = re.sub(r'\W+', '', token) This will remove all punctuation from the string stored in token. You must import the re module to use this regular expression. There is a lot more to regular expressions that we don't need to talk about, so all you need to know is to use this function call if you want to remove punctuation from a string.
Term Frequencies
The term frequency of a term in a document is defined as:
\( TF(t, D) = \frac{\text{number of occurences of term } t \text{ in document} D}{\text{number of words in document} D} \)Therefore, if we had a document
the cutest cutest dogThen the frequencies for the given document would be
"the" : 0.25 # 1 / 4
"cutest" : 0.5 # 2 / 4
"dog" : 0.25 # 1 / 4Write a function called term_frequency that takes a term as a parameter and returns the term-frequency of the given term in the document. This function should not do any actual computation, but instead use the pre-computed dictionary from the initializer. If the given term does not exist in the document, the function should return 0. If using the example above, doc.term_frequency('dog') should return 0.25.
The term_frequency function should be case-insensitive, and remove punctation from the given word, using the regular expressions defined in the initializer.
Getting the Words
Write a function get_words which returns a list of all the words in this document. If there are duplicate words in the document they should only appear in the list once. The words returned should be
the words in the file after our pre-processing described in the spec (lowercase and stripped of punctuation).
Note: You should not re-read the file in this method to compute the words list.
Testing
Thinking forward to Part 3, you can now start thinking about testing your Document class to gain confidence your solution is correct. This is a good idea to start now so you can identify any bugs here, rather than trying to find them when implementing the SearchEngine.
At this point, your Document is fully completed. This means you should be able to compute some term-frequencies for small files you create and test any behaviors of this class described here. A very common frustration from previous students was running into bugs in their Document implementation while trying to implement the next part. Make sure you are fully testing your Document to make sure you are confident it works before moving on.
Part 1: The SearchEngine Class (single word queries)
The SearchEngine class will manage a collection of Documents, and handle computing the relevance of a Documents to a given term. To do this, the SearchEngine will compute the TF-IDF of a given term for each Document which contains the term.
Part of the development strategy for implementing search_engine.py is building the solution up in parts. In Part 1, you will implement a search_engine.py that supports only single-word queries. In Part 2, you will extend this to support multi-word queries.
Part 1 Expectations
- You should create and implement a python file called
search_engine.py - For this part of the assignment, you may import and use the
math,os, andremodules as well as thedocumentmodule you wrote for Part 0, but you may not use any other imports. - Your field(s) in this class should be private.
Important Note
We highly recommend reading the entire search_engine.py (single word query) spec, and understanding the algorithm for ranking documents before implementing. It will be challenging to implement the necessary data structures without understanding the context for how they will be used in the search function.
Constructing a SearchEngine
The SearchEngine initializer should take a directory name (string), and construct an inverse index representing all documents in the given directory. You may assume that the given string represents a valid directory, and that the directory contains only valid files. Your SearchEngine should not reimplement any behavior that is already implemented in the Document class.
Iterating over a Directory
The os.listdir() function will return a list of all the files and directories in a given directory.
import os
for file_name in os.listdir(directory_name):
print(file_name)
# Output
# file1.txt
# file2.txt
# file3.txtYou will use something very similar in your SearchEngine initializer. Each file that is returned by the os.listdir() is represented as only the file name. However, when you pass the file name into the Document initializer, it will try to open the file based on its name. Since the file is in a different directory, the Document will not be able to open the file. To avoid this, we must pass the path of the file to the Document initializer. Since the directory containing the file will be in the same directory as the Document class, we can pass the directory_name + '/' + file_name to the Document initializer. The directory_name is just the string passed to the SearchEngine initializer.
For Mac Users
Macs sometimes create hidden files named .DS_Store that can cause your code to break since they aren't valid text files. One option is to make sure to delete this file. Another option is you are allowed to put a special condition in your code to ignore any files that start with a '.'. You may assume no valid file starts with a '.'. For example, you could write something like:
if not file_name.startswith('.')Inverse Index
When you implement the search function it will be necessary to find all documents which contain the given search term. It is inefficient to iterate over each document in the SearchEngine and check if it contains a given word. Instead, the initializer for SearchEngine should pre-compute an inverse index. An inverse index is just a fancy term for a dictionary which maps from a term (string) to a list of Documents which contain that term. The visualization below describes what the inverse index should look like for a few example documents.
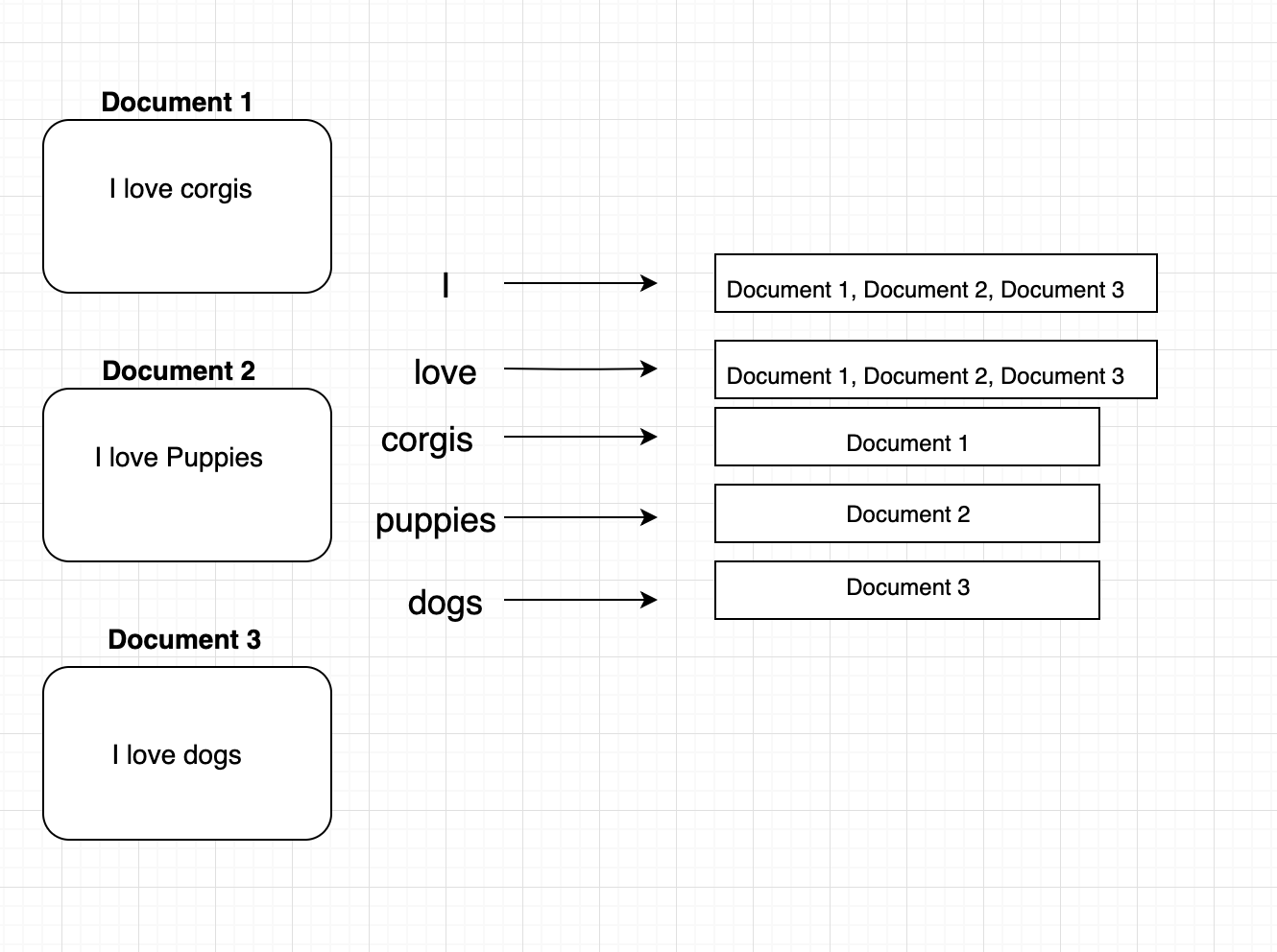
When you are constructing the inverse index in SearchEngine, you should avoid re-implementing any behavior that the Document can provide for you.
Calculating the IDF
Write a function _calculate_idf which takes a term as a string argument and returns the score for that term over all documents managed by the SearchEngine. The IDF represents the inverse document frequency, and is the inverse of the proportion of documents in the SearchEngine that contain the given term. The IDF should be calculated as follows:
Where \( ln \) is the natural logarithm. This can be computed using the log function in the math module.
Note: _calculate_idf is a private function, which will not be used directly by the client. Because it's defined in the SearchEngine class, you should use it to help you implement the search function. We will expect that you have this private function with the behavior described so that we can test your code. As mentioned in lecture, it's generally a bad practice for clients to look at private functions, but we are making an exception for our tests so we can better test your code.
The Search Function
Write a function search which takes a string as an argument and returns a list of document names. The documents should be sorted in descending order of TF-IDF. If no document in your SearchEngine contains the term, the function should return None. The search function should be case-insensitive, and ignore any punctuation in the given term.
The TF-IDF for term t on document D is defined as
\( TFIDF(t, D) = TF(t, D) \cdot IDF(t) \)The Algorithm
To generate a ranked list of documents
- Compute the TF-IDF score for each document that contains the given term. You will probably want to store these scores in a list of tuples each containing the name of the document and its score.
- Sort the documents in descending order of TF-IDF.
- Return the document names as a list.
Search Example 1
It will help to understand a full-example of what the search algorithm should return for an example corpus. Consider we had the following three files in a directory test-files (shown as file name: content). Notice these documents are slightly different than the last part.
test-files/doc1.txt:Dogs are the greatest pets.test-files/doc2.txt:Cats seem pretty okay.test-files/doc3.txt:I love dogs!
A client program that wants to earch this corpus (e.g., maybe your test program), would construct a SearchEngine and search for "dogs" using the following code
search_engine = SearchEngine('test-files')
search_engine.search('dogs') # Returns: ['test-files/doc3.txt', 'test-files/doc1.txt']To figure out why it returns this result, we walk through all of the steps in the search computation below.
- Find all the documents that contain the word
'dogs'. In this case, the relevant files aretest-files/doc1.txtandtest-files/doc3.txt. - Compute the TF-IDF score for each relevant document:
- Compute TF-IDF for
'dogs'intest-files/doc1.txt, which in this example is0.081. This is because the IDF of the term'dogs'in the corpus ismath.log(3/2)and the TF of the term'dogs'intest-files/doc1.txtis1/5. - Compute TF-IDF for
'dogs'intest-files/doc3.txt, which in this example is0.135. This is because the IDF of the term'dogs'in the corpus ismath.log(3/2)and the TF of the term'dogs'intest-files/doc3.txtis1/3.
- Compute TF-IDF for
- We recommend storing this in a list of tuples so we can sort it in the next step. In this example, this list would look like
[('test-files/doc1.txt', 0.081), ('test-files/doc3.txt', 0.135)]. - Then we sort the tuples so they are sorted by TF-IDF in descending order. In this example, this sorted list would look like
[('test-files/doc3.txt', 0.135), ('test-files/doc1.txt', 0.081)]. - Then we can return the result
['test-files/doc3.txt', 'test-files/doc1.txt'].
Note: You should not round your answers in your solution, but we round in the spec so it's easier to read.
Testing
Thinking forward to Part 3, you can now start thinking about testing your SearchEngine class to gain confidence your solution is correct. This is a good idea to start now so you can identify any bugs here, rather than trying to find them when implementing the multi-word queries in SearchEngine.
At this point, your SearchEngine is complete enough to run a query with a single term in it. It is hard to make a test on the entire wikipedia dataset (since you don't know what the expected answer is), so making a test-case for the example shown above would be a great starting point!
Part 2: The SearchEngine Class (multi-word queries)
Now that you have implemented the SearchEngine, we want to extend the search function to support multi-word queries. Note that you should only need to change the search function of your SearchEngine class implemented in Part 1.
Multi-Word Queries
To compute the TF-IDF of a multi-word query, we compute the TF-IDF for each individual term in the query and then sum these terms to compute the total TF-IDF.
For example, if the query was “a cute dog”, the TF-IDF of the query for document D would be
Similar to part 1, we compute the TF-IDF for each document that contains a term in the query and sort the documents by descending order of TF-IDF.
Finding Relevant Documents
However, finding the relevant documents for a multi-word query is a bit more challenging. Instead of looking at a single entry in the dictionary, we must look at all Documents which contain at least one word in the query. This means if the query is “a cute dog” the TF-IDF should be computed for all documents in the SearchEngine that contain the word “a”, all documents that contain the word “cute”, and all documents that contain the word “dog”. Even if a document only contains the word “a”, it should still be included in the ranking - its ranking will just be lower because its TF-IDF score for “cute” and “dog” will be 0.
Search Example 2
It will help to understand a full-example of what the search algorithm should return for an example corpus. Consider we had the following three files in a directory test-files (shown as file name: content).
test-files/doc1.txt:Dogs are the greatest pets.test-files/doc2.txt:Cats seem pretty okaytest-files/doc3.txt:I love dogs!
A client program that wants to earch this corpus (e.g., maybe your test program), would construct a SearchEngine and search for "love dogs" using the following code:
search_engine = SearchEngine('test-files')
search_enginge.search('love dogs') # Returns: ['test-files/doc3.txt', 'test-files/doc1.txt']To figure out why it returns this result, we walk through all of the steps in the search computation below.
- Find all the documents that contain the word
'love'or'dogs'. Documents 3 contain the word'love'and Documents 1 and 3 contain the word'dogs'. Therefore in this example, the relevant documents aretest-files/doc1.txtandtest-files/doc3.txt. - Compute the TF-IDF score for each relevant document for the given query:
- Compute TF-IDF for
'love dogs'intest-files/doc1.txt:- Compute TF-IDF for
'love'intest-files/doc1.txt. In this case it should be0since'love'doesn't appear in Document 1. - Compute TF-IDF for
'dogs'intest-files/doc1.txt. In this case it should be0.081just like in Example 1. In fact, all the calculations for single word queries are just like Example 1, so we just state what the answers should be, but do ask if you don't understand why a number is the way it is! - To compute the overall TF-IDF of the multi-word query
'love dogs'intest-files/doc1.txt, add the TF-IDFs of the individual words to get0.081.
- Compute TF-IDF for
- Compute TF-IDF for
'love dogs'intest-files/doc3.txt:- Compute TF-IDF for
'love'intest-files/doc3.txt. In this case it should be0.366. - Compute TF-IDF for
'dogs'intest-files/doc3.txt. In this case it should be0.135. - To compute the overall TF-IDF of the multi-word query
'love dogs'intest-files/doc3.txt, add the TF-IDFs of the individual words to get0.501.
- Compute TF-IDF for
- Compute TF-IDF for
- We recommend storing this in a list of tuples so we can sort it in the next step. In this example, this list would look like
[('test-files/doc1.txt', 0.081), ('test-files/doc3.txt', 0.501)]. - Then we sort the tuples so they are sorted by TF-IDF in descending order. In this example, this sorted list would look like
[('test-files/doc3.txt', 0.501), ('test-files/doc1.txt', 0.081)]. - Then we can return the result
['test-files/doc3.txt', 'test-files/doc1.txt'].
Note: You should not round your answers in your solution, but we round in the spec so it's easier to read.
Note that is just a coincidence that this was the same result as the first example. If instead, we searched for 'cats dogs' with the documents above, your search engine would return ['test-files/doc2.txt', 'test-files/doc3.txt', 'test-files/doc1.txt'] since all 3 documents are relevant for that query, and they have overall score 0.275, 0.135, and 0.081 respectively (in decreasing TF-IDF order).
Part 3: Testing and Running the Search Engine
Now that you have implemented a SearchEngine that supports multi-word queries, you can use it to query directories full of text documents!
Running the Search Engine Locally
main.py is a program for running your SearchEngine that we have implemented for you. It can be run in VS Code just like any other python program (Right-click -> “Run Python File in Terminal”). When run, main.py will output a series of prompts to the console, which allow the user to input the directory to be searched, and then enter search terms.
We have included a directory called wikipedia in hw4.zip which contains a large number of HTML wikipedia pages. You can run main.py and enter wikipedia as the directory. Note that it will take a few minutes for the SearchEngine to be constructed because there are so many files. You can also use small-wiki as a smaller example.
You can now query terms over Wikipedia files! Note how fast the ranking is for terms you have searched. Even though the number of documents is HUGE. Since you precomputed all of the values, computing a document ranking is very fast.
Running the Search Engine on Ed
You can run the search engine with the Run button. The wikipedia directory included for the people running locally is too large for Ed. Instead, you should use small-wiki. The directory for small-wiki can be found at /course/small-wiki.
You can now query terms over Wikipedia files! Note how fast the ranking is for terms you have searched. Even though the number of documents is HUGE. Since you precomputed all of the values, computing a document ranking is very fast.
To run your own tests, you will have to open the terminal and run python hw4_test.py.
Testing
You will also need to test your document.py and search_engine.py classes. We have included a file called hw4_test.py where you should write your tests. As a reminder, we are only showing you some of the tests we have for your assessment.
You should write at least three tests for document.py and three tests for search_engine.py. Each call to assert_equals counts as a single test. Testing these classes will require you to create your own test corpus since it would be too much work for you to find the expected output to use for the wikipedia dataset. To test each class you can construct a new instance of the class and pass in your own custom documents. Then you can call the functions of the class and verify that the returned value matches what you expected.
Since the SearchEngine reads documents from a folder, to test it you will likely need to create your own directories containing files in your hw4 directory. You should include these test document directories in your submission so we can run your tests.
Recall on Ed, you will need to specify the paths to these directories with an absolute path (e.g./home/test-dirif you uploadedtest-dir).
As in previous assessments, we have provided a function called assert_equals that takes an expected value and the value returned by your function, and compares them: if they don't match, the function will crash the program and tell you what was wrong. You can see more instructions an example for tests from the Assessment 1 - Part 1 to see examples of how to call the tests.
Similar to the previous assessments, the assert_equals lives in a file called cse163_utils.py.
Part 3 Expectations
For full credit, your hw4_test.py must satisfy all of the following conditions:
- Use your own test data files just like in HW2. Make sure to turn them in as well!
- Should be written with good programming style. This means your code should satisfy the requirements within the CSE 163 Code Quality Guide.
- Has functions to separate the tests for
Documentand the tests forSearchEngine. - Each of these test functions should have a descriptive name that indicates which function is being tested (e.g.
test_funky_sum)
Evaluation
Your submission will be evaluated on the following dimensions
- Your solution correctly implements the described behaviors. While you will have access to all the tests when turning Marking your assignment, you will find them very difficult to debug just using the mark output. You will need to create your own test cases to debug your solution. All behavior we test is completely described by the problem specification or shown in an example.
- When we run your code, it should produce no errors or warnings.
- You should remove any debug print statements. Some students report Ed crashing when they try to print the whole dataset; remove those extra print statements to prevent excessive output.
- Your code meets our style requirements:
- All code files submitted pass
flake8. - All program files should be written with good programming style. This means your code should satisfy the requirements within the CSE 163 Code Quality Guide.We recommend you pay extra attention to the classes and objects section in the style guide.
- Any expectations in the subsections listed above are met.
- All code files submitted pass
A note on allowed material
A lot of students have been asking questions like "Can I use this method or can I use this language feature in this class?". The general answer to this question is it depends on what you want to use, what the problem is asking you to do and if there are any restrictions that problem places on your solution.
There is no automatic deduction for using some advanced feature or using material that we have not covered in class yet, but if it violates the restrictions of the assignment, it is possible you will lose points. It's not possible for us to list out every possible thing you can't use on the assignment, but we can say for sure that you are safe to use anything we have covered in class so far as long as it meets what the specification asks and you are appropriately using it as we showed in class.
For example, some things that are probably okay to use even though we didn't cover them:
- Using the
updatemethod on thesetclass even though I didn't show it in lecture. It was clear we talked about sets and that you are allowed to use them on future assignments and if you found a method on them that does what you need, it's probably fine as long as it isn't violating some explicit restriction on that assignment. - Using something like a ternary operator in Python. This doesn't make a problem any easier, it's just syntax.
For example, some things that are probably not okay to use:
- Importing some random library that can solve the problem we ask you to solve in one line.
- If the problem says "don't use a loop" to solve it, it would not be appropriate to use some advanced programming concept like recursion to "get around" that restriction.
These are not allowed because they might make the problem trivially easy or violate what the learning objective of the problem is.
You should think about what the spec is asking you to do and as long as you are meeting those requirements, we will award credit. If you are concerned that an advanced feature you want to use falls in that second category above and might cost you points, then you should just not use it! These problems are designed to be solvable with the material we have learned so far so it's entirely not necessary to go look up a bunch of advanced material to solve them.
tl;dr; We will not be answering every question of "Can I use X" or "Will I lose points if I use Y" because the general answer is "You are not forbidden from using anything as long as it meets the spec requirements. If you're unsure if it violates a spec restriction, don't use it and just stick to what we learned before the assignment was released."
Submission
This assignment is due by Thursday, February 11 at .
You should submit your finished
document.py,
search_engine.py,
and hw4_test.py
on Ed.
DO NOT submit the wikipedia dataset. You may submit your assignment as many times as you want until the deadline for the initial submission. Recall on Ed, you submit by pressing the "Mark" button. Work after the due date will not be accepted for an initial submission. Please see the syllabus for the policies on initial submissions and resubmissions.