Text Classifier
Implementing a decision tree data type for text classification.
Online abuse and harassment stops people from engaging in conversation. One area of focus is the study of negative online behaviors, such as toxic comments: user-written comments that are rude, disrespectful or otherwise likely to make someone leave a discussion. Platforms struggle to effectively facilitate conversations, leading many communities to limit or completely shut down user comments. In 2018, the Conversation AI team, a research initiative founded by Jigsaw and Google (both part of Alphabet), organized a public competition called the Toxic Comment Classification Challenge to build better machine learning systems for detecting different types of of toxicity like threats, obscenity, insults, and identity-based hate.
- Warning
Machine learning models are trained on human-selected and human-generated datasets. Such models reproduce the bias inherent in the data. The included data representation algorithms also encode overly-simplistic assumptions about natural language by treating each occurrence of a word as independent from all other words in the text. Any usage of a word, no matter the context, is considered equally toxic. Don’t use this in a real system!
When the Conversation AI team first built toxicity models, they found that the models incorrectly learned to associate the names of frequently attacked identities with toxicity. In 2019, the Conversation AI team ran another competition about Unintended Bias in Toxicity Classification, focusing on building models that detect toxicity across a range of diverse conversations.
The provided datasets contain text that may be considered profane, vulgar, or offensive.
Text Classifier
- Nov 9
- Binary Trees
- BJP 17.1, 17.2
- Run pre-order, in-order, and post-order traversals on a binary tree.
- Define methods that recursively traverse binary trees.
- Define methods that recursively modify binary tree node data values.
- Nov 10
- SectionBinary Trees
- Nov 11
- Holiday
- Nov 12
- SectionMore Binary Trees
- Nov 13
- Binary Search Trees
- BJP 17.3, 17.4
- Apply the binary search tree invariant to search for values and add new values.
- Apply the
x = change(x)pattern to recursively change binary tree references. - Explain why binary search trees would be preferred over binary search on arrays.
Toxic comment classification is a special case of a more general problem in machine learning known as text classification. Discussion forums use text classification to determine whether comments should be flagged as inappropriate. Email software uses text classification to determine whether incoming mail is sent to the inbox or filtered into the spam folder.1
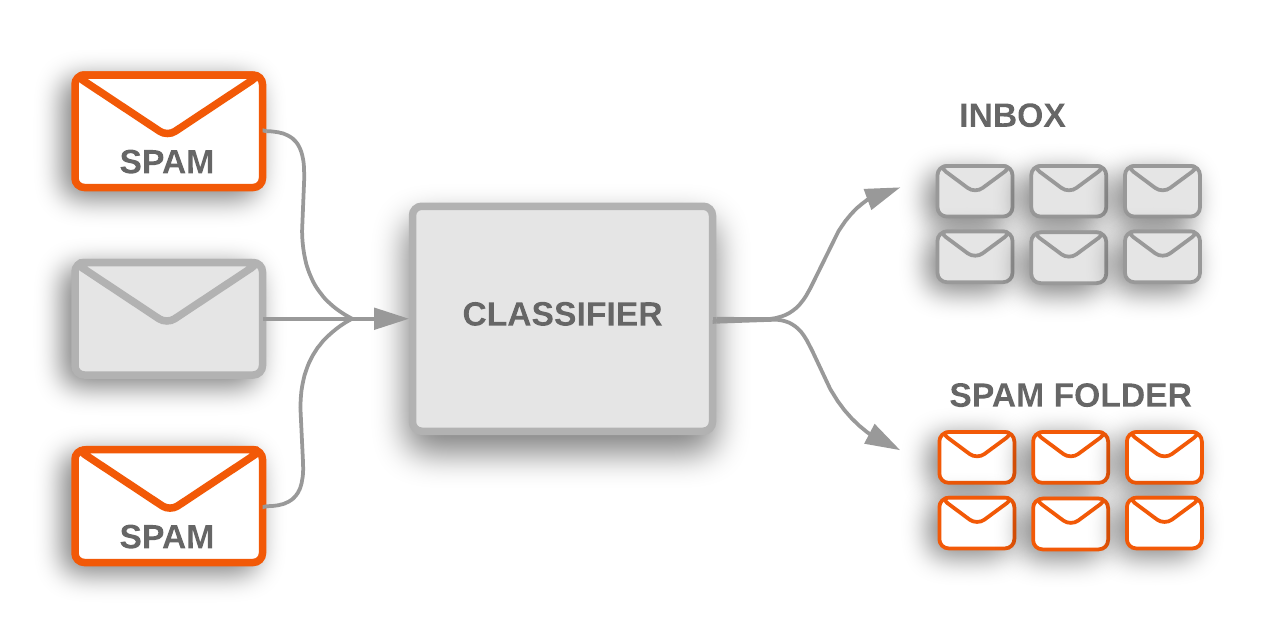
Specification
Implement a TextClassifier data type, a binary decision tree for classifying text documents.
TextClassifier(Vectorizer vectorizer, Splitter splitter)- Constructs a new
TextClassifiergiven a fittedvectorizerfor transforming data points and asplitterfor determining the splits in the tree. boolean classify(String text)- Returns a boolean representing the predicted label for the given
textby recursively traversing the tree. void print()- Prints a Java code representation of this decision tree in if/else statement format without braces and with 1 additional indentation space per level in the decision tree. Leaf nodes should print “return true;” or “return false;” depending on the label value.
if (vector[318] <= 5.273602694890837) if (vector[1116] <= 5.093549034038833) return false; else return false; else if (vector[893] <= 5.313808994135437) return false; else return false; void prune(int depth)- Prunes this tree to the given
depth. Each pruned subtree is replaced with a new node representing the subtree’s majority label. For example, pruning the above decision tree to depth 1 would result in the following structure.if (vector[318] <= 5.273602694890837) return false; else return false;
Modify and run the Main class to debug your TextClassifier. Several classes and interfaces are included to handle the machine learning components of the TextClassifier. The most useful methods are described below.
Vectorizer
The Vectorizer interface defines algorithms for transforming English text into a double[][] design matrix for the Splitter interface. A design matrix consists of an array of double[] vectors, where each vector represents a single example text from the dataset (such as a comment or an email). The choice of BM25Vectorizer or LSAVectorizer algorithm determines how the English text is converted into a numeric representation.
double[][] transform(String... texts)- Returns the design matrix for the given texts.
When implementing the classify method, given a single text, vectorizer.transform(text)[0] evaluates to a vector that can be passed to Split.goLeft.
Splitter
The Splitter interface provides a split method for dividing the given data points into left and right. The RandomSplitter is provided for debugging and visualization purposes while the GiniSplitter computes the optimal split based on information theory.
Splitter.Result split()- Returns the best split and the left and right splitters, or null if no good split exists. The
Splitter.Resultclass represents the left and right splitters that result from applying a split. boolean label()- Returns the majority label for this splitter.
When constructing a TextClassifier, call split() and use the Splitter.Result to determine the decision rules. Since the decision tree is a recursive data structure, this process will continue until split() returns null, in which case the program should construct a new leaf node containing only the majority label.
Split
The Split class represents a decision rule for splitting vector data.
boolean goLeft(double[] vector)- Returns true if and only if the given vector lies to the left of this decision rule.
String toString()- Returns a string representation of this decision rule,
vector[index] <= threshold.
Web app
To launch the web app, Open Terminal , paste the following command, and press Enter.
javac -cp ".:/course/lib/*" Server.java && java -cp ".:/course/lib/*" Server toxic.tsv; rm *.class
Then, open the Network dropdown and select host 0.0.0.0:8000.
Grading
Mark the program to submit it for grading. In addition to the automated tests, the final submission will also undergo code review for internal correctness on comments, variable names, indentation, data fields, and code quality.
- Data structure errors
- Not using
x = change(x)when appropriate to simplify code.
Google Developers. Oct 1, 2018. Text classification. In Machine Learning Guides. https://developers.google.com/machine-learning/guides/text-classification ↩