
|

CSE 461: Introduction to Computer Communication Networks, Winter 2017
|
|
|
|
 |
|
Project 2: HTTP Proxy
Out: Sunday, January 22nd
Due: Sunday, Feb 12nd, 11 PM
Turnin: Online
Teams: Teams of 2
Project Overview.
|
|
In this project, you will write an HTTP proxy that passes requests and data between multiple web clients and web servers, concurrently. The HTTP proxy is capable of both relaying HTTP requests and HTTP CONNECT tunneling. You'll point a browser at your proxy, so that it sends all page requests to your code instead of directly to the page's origin server.
-
For non-CONNECT HTTP requests, you'll slightly edit the HTTP
request header and send it and any payload the request might carry
to the origin server, and then slightly edit the HTTP response
header and send it and any response payload back to the browser.
-
For CONNECT HTTP requests, you'll establish a TCP connection to
the server named in the request, send an HTTP success response to
the browser, and then simply pass through any data sent by the
browser or the remote server to the other end of the communication.
-
Your proxy should be capable of handling the traffic caused by
real user browsing. A small portion of that traffic is generated
by the user's typing URLs or clicking on links. Much of the
traffic is caused by the contents of the pages the user has asked
for - both elements embedded in those pages (e.g., images) and
Javascript loaded with it can result in many additional HTTP
transactions.
|
Background.
|
Hypertext Transfer Protocol (HTTP)
|
|
The Hypertext Transfer Protocol (HTTP) is the protocol used for
communication on this web: it defines how your web browser requests
resources from a web server and how the server responds. For
simplicity, in this assignment, we will be dealing only with version
1.0 of the HTTP protocol, defined in detail in
RFC 1945. You may
refer to that RFC while completing this assignment, but our instructions
should be self-contained.
HTTP communications happen in the form of transactions; a transaction
consists of a client sending a request to a server and then reading
the response. Request and response messages share a common basic format:
- An initial line (a request or response line, as defined below)
- Zero or more header lines
- A blank line (CRLF)
- An optional message body.
The initial line and header lines are each followed by a
"carriage-return line-feed" (\r\n) signifying the end-of-line.
For most common HTTP transactions, the protocol boils down to a
relatively simple series of steps (important sections of
RFC 1945 are in
parenthesis):
- A client creates a connection to the server.
-
The client issues a request by sending a line of text to the
server. This request line consists of a HTTP method (most often
GET, but POST, PUT, and others are possible), a request URI (like
a URL), and the protocol version that the client wants to use
(HTTP/1.0). The request line is followed by one or more header
lines. The message body of the initial request is typically empty.
(5.1-5.2, 8.1-8.3, 10, D.1)
-
The server sends a response message, with its initial line
consisting of a status line, indicating if the request was
successful. The status line consists of the HTTP version
(HTTP/1.0), a response status code (a numerical value that
indicates whether or not the request was completed successfully),
and a reason phrase, an English-language message providing
description of the status code. Just as with the the request
message, there can be as many or as few header fields in the
response as the server wants to return. Following the CRLF field
separator, the message body contains the data requested by the
client in the event of a successful request. (6.1-6.2, 9.1-9.5, 10).
-
Once the server has returned the response to the client, it closes
the connection.
It's fairly easy to see this process in action without using a web browser. From a Linux prompt, type:
telnet www.washington.edu 80
This opens a TCP connection to the server at www.google.com listening on port 80 (the default HTTP port). You should see something like this:
|
Trying 128.95.155.198...
Connected to www.washington.edu (128.95.155.198).
Escape character is '^]'.
|
|
type the following:
GET http://www.washington.edu/ HTTP/1.0
and hit enter twice. You should see something like the following:
|
HTTP/1.1 200 OK
Date: Mon, 19 Oct 2015 22:30:09 GMT
Server: Apache/2.2.24 (Unix) mod_ssl/2.2.24 OpenSSL/1.0.1e-fips PHP/5.6.11 mod_pubcookie/3.3.4a mod_uwa/3.2.1
Last-Modified: Mon, 19 Oct 2015 22:26:09 GMT
ETag: "6e7597-a941-5227ca1c6c240"
Accept-Ranges: bytes
Content-Length: 43329
Connection: close
Content-Type: text/html
UW Homepage
(More HTML follows)
|
|
There may be some additional pieces of header information as well-
setting cookies, instructions to the browser or proxy on caching
behavior, etc. What you are seeing is exactly what your web browser
sees when it goes to the washington home page: the HTTP status line,
the header fields, and finally the HTTP message body- consisting of
the HTML that your browser interprets to create a web page. You may
notice here that the server responds with HTTP 1.1 even though you
requested 1.0. Some web servers refuse to serve HTTP 1.0 content.
|
HTTP Proxy
|
|
HTTP is the protocol used to transfer information between browsers and
web servers. HTTP is transmitted using TCP as the transport protocol.
An HTTP proxy is a program that can accept and reply to requests that
would normally be directed to some web server. Proxies are an example
of the use of "interposition" - placing something between two things
that communicate using a well-defined interface - as shown in the
figure below. Interposition is a generally useful technique. When
possible, it allows new functionality to be injected into existing
code with little or no modification to that code. For example, an HTTP
proxy might be used for monitoring or debugging (by capturing a log of
browser requests and server responses), to improve performance by
maintaining a cache of web pages, or to enforce some policy about
which sites can be accessed.
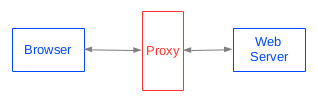
|
Assignment Details.
|
Non-CONNECT HTTP requests.
|
|
The requirements for our proxy are very modest: it merely prints out
(at least the initial portion of) the first line of each HTTP request
it receives from the browser, then fetches the requested page from the
origin web server and returns it to the browser. This means that, for
the most part, you don't have to know anything about HTTP; you simply
read what the browser sends, print out (only) the first line, and pass
that and all subsequent lines on to the web server. On the other side,
you read everything the web server sends and pass it back to the
browser. You keep forwarding data in this way, in each direction,
until you detect that the source has closed the connection.
While that's the basic operation, there are two details that require a
bit of processing of the HTTP stream. To make what follows more
concrete, here's an example of what Firefox sent when I requested the
page www.my.example.page.com. (I obtained this by running
nc -l 46103 to set it listening for TCP connections on port
46103, and then configuring Firefox to use a proxy located at
localhost:46103.)
|
$ nc -l 46103
GET http://www.my.example.page.com/ HTTP/1.1
Host: www.my.example.page.com
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:26.0) Gecko/20100101 Firefox/26.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
|
|
Determining the web server's address
When the browser sends an HTTP request to your proxy, you need to
forward it on to the origin web server. You determine the web server
by recognizing the Host line in the HTTP header. In the
example above, the host is www.my.example.page.com. You
should be insensitive to the case of the keyword Host, and
you should be tolerant of white space anywhere it might plausibly
appear. In general, the host name may be given as
hostname:port or ip:port. If no port is specified,
you should look for one in the URI given on the request line (the
first line of the header). If there is no port there either, you
should use 80 if the transport on the request line is either missing
or is (case-insensitive) 'http://' and 443 if the transport is
'https://'.
The HTTP specification says that lines of the header are terminated by
CRLF:
|
CR = <US-ASCII CR, carriage return (13)>
LF = <US-ASCII LF, linefeed (10)>
|
|
You should be lenient in interpreting this, though. For instance, you
might see headers where the lines are terminated by a single LF.
HTTP does not require any particular ordering for the lines of the
header, except that the request line (which is always of the general
form shown in the example above) must be first.
The HTTP 1.1 specification requires that a Host line be
provided in an HTTP request (but not in a reply). Your code does not
have to work with HTTP 1.0, which doesn't require these lines. (But,
I'd guess you'd have a hard time finding a browser that wanted to
speak HTTP 1.0 in any case.)
Turning off keep-alive
The HTTP Connection: keep-alive line can be used to indicate
that the browser (or server) wants to keep the TCP connection open
even after the current HTTP request has been fully satisfied. This is
a performance optimization: if the browser issues additional requests
to the same server within a short time, the overhead of closing the
current TCP connection and opening a new one is avoided.
Supporting keep-alive greatly complicates the proxy, because
it needs to do enough HTTP parsing to understand where one HTTP
request ends and the subsequent one begins (and similarly for
responses coming from the server). HTTP doesn't have a simple framing
mechanism for marking these boundaries. To avoid that, you should
filter the request and response streams, removing any Connection:
keep-alive, inserting a Connection: close, and
converting any Proxy-connection: keep-alive to
Proxy-connection: close. That should cause the browser and
web server to close the TCP connection after each request. Each HTTP
request now starts with the creation of a new TCP connection and ends
with TCP close, making things simpler for the proxy.
The Tranformed Request Header
The final change we make is to lower the HTTP version of the request
to HTTP 1.0. This is probably unnecessary, but the more discouragement
to using persistent connections we can provide the better.
With that change, the header sent on to www.my.example.page.co
is this:
|
$ nc -l 46103
GET http://www.my.example.page.com/ HTTP/1.0
Host: www.my.example.page.com
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:26.0) Gecko/20100101 Firefox/26.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
|
HTTP CONNECT Tunneling.
|
|
The HTTP request method CONNECT is used to establish a two-hop TCP
connection between the client and some server. HTTP is used only to
convey the CONNECT request between the client and the proxy, and to
convey a success/failure response from the proxy back to the client.
When the proxy receives the request, it determines the destination
server (using the technique described above) and tries to open a TCP
connection to it. If it succeeds, it returns an HTTP 200 OK response
to the client. If the proxy fails to resolve the server address or
connect to the server, it sends an HTTP 502 Bad Gateway response to
the client and closes the connection.
At this point, nothing has yet been sent to the server, all that's
happened is that a TCP connection has been established with it (in the
success case). None of the HTTP request headers are ever sent to the
server. Instead, the proxy simply forwards to the server any bytes it
receives after the request header on its connection with the client,
and forwards to the client any bytes it receives on its connection
with the server. The client may send anything at all it wants on that
TCP connection - it could be HTTP messages, or it could be something
else completely. HTTPS uses this technique to allow TLS to negotiate a
session key between the client and the server. The proxy is simply a
conduit for a binary data exchange, and the client and server exchange
the same messages over the tunnel as they would over a direct TCP
connection with each other.
|
Solution Restrictions
|
As usual, our goal isn't to have dozens of HTTP proxy implementations,
but rather to provide you with a reasonably specific development
experience. For that reason, your implementation must conform
to these restrictions:
-
We'd like you to build your proxy directly on TCP sockets. The
language (or libraries available for the language) you use may offer
you much higher level functionality - some form of HTTP server is
often available, for instance - but you should not use it.
-
Your code may buffer entire HTTP headers, in either direction, before
sending any portion of the (edited) header on to its destination, but
you must not try to buffer the entire request or response. This means
your code must stream at least the payload portion of the
request and response - send it on as you receive it, rather than
accumulate it until you have it all.
-
You are free to use any implementation approach you'd like (e.g.,
threads or event-loop). However, your implementation must be
sufficiently concurrent that the handling of any single client request
cannot substantially delay the handling of other, concurrent requests.
(Additionally, it would be nice if your proxy didn't completely
collapse if the face of a temporary, very high request rate, but that
isn't required.)
|
Testing.
|
|
We show here some sample output. The output is basically a trace of
the HTTP request methods and URIs issued by the browser when fetching
some page. It is very likely that two requests for the same page will
result in different request streams. For one thing, the order of the
requests is somewhat random. For another, the components of the page,
and so the things fetched, can vary from one page fetch to another. On
the other hand, some things must appear in each request trace, for
instance, the request for the page itself. The result of this is that
it's hard to say exactly what part of these traces your output must
include.
The output follows a format that your code also must follow: each HTTP
request line output must be preceded by '>>> ' (and your code should
print that only for such output, except in the odd case that you're
printing some data and the data includes it). Note the trailing space
after the '>>>' characters, before the HTTP request line starts. You
must print at least the HTTP method and URI given on the request line,
but you can also print the entire request line (which additionally
includes the HTTP version) if that's easier. The sample output prints
only the method and URI.
Finally, you may print anything you want before the '>>> ' tag, and
you may print any additional lines you want so long as they don't
contain the '>>> ' tag. For example, you may want to print error
messages, or even debugging information.
|
Configuring Firefox
|
|
To use the proxy we must configure the browser to send all its
requests to the proxy, instead of directly to the web servers. In
Firefox you do this using Preferences, then the Advanced icon, then
the Network tab, then the Settings button for "Connection." Configure
the proxy manually, giving the host and port your proxy is running
on. You should, eventually, allow all types of traffic to pass through
your proxy (although we care only about HTTP and HTTPS (SSL)), so you
should check the "Use this proxy server for all protocols" check box.
It might be easier during initial test to leave it unchecked, though,
in which case your proxy will see only http:// requests.
|
Turnin.
|
run Script
|
|
To help us test your code, provide a run script that will
build and invoke your proxy. The script should take a single argument:
the port number the proxy's server socket should bind to, for example:
$ ./run 1234
Execution is terminated by end-of-file on stdin or by ctrl-C.
|
Files
|
When you're ready to turn in your assignment, do the following:
-
The files you submit should be placed in a directory named
project2. There should be no other files in that
directory.
-
Create a README.txt file that contains the names and UW netid
of the member(s) of your team.
-
The readme must also contain all the instructions necessary to
compile and run your code.
-
Put the README.txt file, your HTTP proxy solution source code, and
your run script in the project2 directory.
-
Archive all the materials (project2 folder and everything in it)
in a single .tar file named
partner1netid_partner2netid.tar.
-
Submit the partner1netid_partner2netid.tar file to the
course dropbox.
|
|
 |
Computer Science & Engineering
University of Washington
Box 352350
Seattle, WA 98195-2350
(206) 543-1695 voice, (206) 543-2969 fax
[comments
to kheimerl
at cs.washington.edu]
|
|
{kind=link}
{kind=link}