|
|
|

|
|
Project 3 - User-Level Threads
Updates
- 05/11/2004: The "free blank context" bug has been addressed in the
ctx-free patch. The file is also available on spinlock and coredump in the /cse451/projects directory. To patch your code, do the following:
1. Download and extract the file to your top-level simplethreads directory.
2. Run patch -p0 < ctx-free.patch
Outline
Out: Thursday, April 29th
Parts 1, 2, and 3 Due: Wednesday, May 12th at 11:00 am
Parts 4 and 5 Due: Monday, May 17th at 11:00 am
For this project, you will be working in groups of 2.
Please select a partner by Friday afternoon and e-mail Ilya with both members' names (one e-mail per group please).
Tasks:
- Implement a user-level thread manager.
- Add a set of common synchronization primitives to your thread package.
- Implement several "famous" problems in concurrent programming using two distinct thread libraries - your package from parts 1 & 2 and Java Threads.
- Implement a multithreaded web-server to test your thread package.
- Analyze your design and test results in a report.
Assignment Goals
- To gain understanding of how thread packages are implemented,
including data structures used, the interface provided, and common
problems they face.
- To make use of common synchronization primitives such as locks and
condition variables.
- To an gain understanding of and to practice concurrent programming, using classic problems of thread synchronization.
- To understand some of the problems with user-level threads.
- To interact with the instructor and TAs.
- To understand the concept of overlapping I/O and computation.
- To practice discussion and analysis of your designs.
Background
In the beginning (well, the relative beginning), there was UNIX. UNIX supported
multiprogramming; that is, there could be multiple independent processes each
running with a single thread of control.
As new applications were developed, programmers increasingly desired multiple
threads of control within a single process so they could all access common
data. For example, databases might be able to process several queries at the
same time, all using the same data. Sometimes, they used multiple processes to
get this effect, but it was difficult to share data between processes (which is
typically viewed as advantage, since it provides isolation, but here it was a
problem).
What they wanted was multithreading support: the ability to run several threads
of control within a single address space, all able to access the same memory
(because they all have the same mapping function). The programmers realized
that they could implement this entirely in the user-level, without modifying
the kernel at all, if they were clever.
As you'll discover in the last part of this assignment, there were some
problems with this approach, which motivated kernel developers to include
thread support in the kernel itself (and motivated researchers to do it better;
see Scheduler Activations).
Simplethreads
You will be using the simplethreads package for this assignment. It is
available on spinlock/coredump in
/cse451/projects/simplethreads-1.X.tar.gz or
for download.
(Where X is the release number, which may be updated. Use the latest
version. Please watch for updates as the project progresses.)
This project, since it does not involve modifying the kernel, does not
require VMWare. The simplethreads package has been tested on:
- RedHat 7.3/i386 (linux 2.4.21) (e.g. spinlock and
coredump)
- Debian 3.0/i386 (linux 2.4.21)
- Mac OS X 10.3.2 and later
- FreeBSD 4.9/i386
Please do not use attu.
To begin, copy the tar.gz file to your work directory (/cse451/LOGIN) and
run
tar -xvzf simplethreads-1.X.tar.gz
to expand it (if you are working on a different machine, see scp(1)).
Simplethreads contains a lot of files, but most are safe to ignore. Pay
attention to:
|
Dir/File | Contents |
| lib/ |
The simplethreads thread library itself. |
| lib/sthread_user.c |
Your part 1 and part 2 implementations go here. |
| lib/sthread_ctx.{c,h} |
Support for creating new stacks and switching between them. |
| lib/sthread_switch_{powerpc,i386}.h |
Assembly functions for saving registers and switching stacks. |
| lib/sthread_queue.h |
A simple queue that you may find useful. |
| include/ |
Contains sthread.h, the public API to the library
(the functions available for apps using the library). |
| test/ |
Test programs for the library. |
| web/ |
The webserver for part 3. |
Like many UNIX programs, simplethreads uses a configure script to determine
parameters of the machine needed for compilation (in fact, you'll find many
UNIX packages follow exactly the same build steps as simplethreads).
In the simplethreads-1.X directory, run ./configure
to generate an appropriately configured Makefile.
Finally, build the package by typing make. You can also build an
individual part, such as the library, by running make in a
subdirectory. Or, if you just want to compile one file, run make myfile.o
(from within the directory containing myfile.c).
Note that, as you make changes, it is only necessary to repeat the last step (make).
One interesting feature of simplethreads is that applications built using it
can use either the native, kernel-provided threads or the user-level threads
that you'll implement. Because both provide the same interface (once
you've completed parts 1 and 2, anyway), the applications don't even
know which version is running. The
configure script will accept a --with-pthreads
argument to select the version in use (the default is user
threads). To switch back and forth, re-run configure and then
run make clean.
In summary, the steps are:
- Copy the tar.gz source to your directory.
- tar -xvzf simplethreads-1.X.tar.gz
- cd simplethreads-1.X
- ./configure [--with-pthreads]
- make
- make check (Run the programs in test/)
To Add a Source File
If you add a new source file, do the following:
-
Edit the Makefile.am in the directory containing the new file, adding
it to the _SOURCES for the library/executable the file is a part of.
E.g., to add a new file in the lib/ directory that will become part of
the sthread library, add it to the libsthread_la_SOURCES
line.
-
The edited Makefile.am has to be processed by the
automake tool before it can be used by make. From
within the top-level directory:
- On spinlock/coredump: run
/cse451/projects/tools/bin/autoreconf
- On Mac OS X 10.3 machines: run aclocal && automake && autoconf
-
Also from the top-level directory, run ./configure.
-
Your file is now added; run make as usual to build it.
To Add a New Test Program
-
Edit test/Makefile.am. Add your program to the list bin_PROGRAMS.
Create new variables prog_SOURCES and prog_LDADD following
the examples of the programs already there. For example, if the new program is
named test-silly, add:
test_silly_SOURCES = test-silly.c
other sources here
test_silly_LDADD = $(ldadd)
- Follow steps 2-4 above.
To Add a New Arbitrary File
-
Edit the Makefile.am in the directory containing your file.
Add your file to the list EXTRA_DIST (see top-level
Makefile.am for an example).
- Follow steps 2-4 above.
The Assignment
| Part 1: Implement Thread Scheduling
|
For part 1, we give you:
-
An implementation of a simple queue (sthread_queue.h).
-
A context-switch function that, given a new stack pointer, will switch contexts
(sthread_ctx.h).
-
A new-stack function that will create and initialize a new stack such that it
is ready to run.
-
Skeleton routines for a user-level thread system (sthread_user.c).
It is your job to complete the thread system, implementing:
-
Data structures to represent threads (struct _sthread in sthread_user.c).
-
A thread creation routine (sthread_user_create()).
-
A thread destruction routine (sthread_user_exit()).
-
A simple non-preemptive thread scheduler.
-
A mechanism for a thread to voluntarily yield, allowing another thread to run (sthread_user_yield()).
-
A routine to initialize your data structures (sthread_user_init()).
The routines in sthread_ctx.h do all of the stack manipulation, PC
changing, register storing, and nasty stuff like that. Rather than focusing on
that, this assignment focuses on managing the thread contexts. Viewed as a
layered system, you need to implement the grey box below:
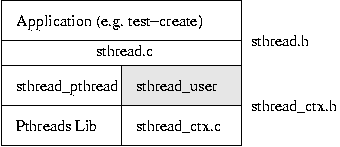
At the top layer, applications will use the sthread package (through the API
defined in sthread.h). sthread.c will then call either the
routines in sthread_pthread.c or your routines in sthread_user.c
(it chooses based on the value passed to sthread_init()). Your sthread_user.c,
in turn, builds on the sthread_ctx functions (as described in sthread_ctx.h).
Applications (the top-layer) may not use any routines except those listed in sthread.h.
They must not know how the threads are implemented; they simply request threads
be created (after initializing the library), and maybe request yields/exits.
For example, they have no access to sthread_queue. Nor do they keep
lists of running threads around; that is the job of the grey box.
Similarly, your grey box - sthread_user.c - should not need to know
how sthread_ctx is implemented. Do not attempt to modify the sthread_ctx_t
directly; use the routines declared in sthread_ctx.h.
Recommended Procedure
-
Figure out what each function you need to implement does. Look at some of the
test programs to see usage examples.
-
Examine the supporting routines we've provided (primarily in sthread_queue.h
and sthread_ctx.h).
-
Design your threading algorithm: When are threads put on the ready queue? When
are threads removed? Where is sthread_switch
called?
-
Figure out how to start a new thread and what to do about the initial thread
(the one that calls sthread_user_init).
-
Talk to your fellow students and the TAs about your design.
-
Implement it.
-
Test it. The test programs provided are not adequate; for full confidence in
your implementation, you'll need to create some of your own.
Hints
-
sthread_create
should not immediately run the new thread.
-
Use the provided routines in sthread_ctx.h. You don't need to
write any assembly or try to directly manipulate registers for this assignment,
nor is an understanding of the exact layout of the stack required.
-
If the routine passed to sthread_create() finishes (returns), you need
to make sure the thread's resources are cleaned up (i.e. sthread_exit()
is called).
-
The start routine passed to sthread_new_ctx does not take any
arguments (unlike the routine that your sthread_user_create
is passed). So you can't create a new stack directly with the user-supplied
routine; you need to supply a routine that takes no arguments but somehow winds
up invoking the user's routine with the user's argument.
-
You should free any resources allocated when a thread exits (whether it exits
explicitly, by calling sthread_exit(), or implicitly, because the
start routine returns). However, you should not attempt to free the stack of a
running thread (note: to free a stack, use shread_free_ctx()).
This requires a few tricks.
-
Dealing with the initial thread is tricky. You need to make sure that an sthread_t
struct is created for it at some point, so it can be scheduled like the other
threads. However, it wasn't created by your sthread_user_create() function.
Remember that, while a thread is running, the state stored in the sthread_t
is garbage (though it is probably important that you have an sthread_t, so
you've got some place to put the state when you want to stop the thread).
-
Be very careful using any local variables after calling sthread_switch()
as their values are quite likely different from what they were before (you're
on a different stack).
-
While globals are bad in general, there will be places in this assignment where
they are necessary.
-
When debugging with gdb(1), you may see messages like
[New Thread 1024 (LWP 18771)]. These messages refer to
kernel threads.
| Part 2: Implement Mutexes and Condition Variables
|
For part 2, you'll use the thread system you wrote in part 1, extending it to
provide support for mutexs (a.k.a. locks) and condition variables. Skeleton
functions are again provided in lib/sthread_user.c. You need to:
-
Design data structures for mutexs (struct _sthread_mutex) and
condition variables (struct _sthread_cond).
-
Implement the mutex operations (sthread_user_mutex_*()).
-
Implement the condition variable operations (sthread_user_cond_*()).
The non-preemptive nature of this assignment aids you greatly in your tasks
(since it gives you atomic critical sections). However, you should think about
what you would need to do if your threads were preemptive; add comments to the
routines indicating precisely where the critical sections are and what
appropriate protection might be applicable (e.g. how you would use a spinlock
or other atomic operation).
Hints
- Figure out how to block a thread, making it wait on some queue. How do you get
the calling thread? How do you switch out of it? How will you wind up back in
it?
- Locks do not immediately switch threads when unlocked.
| Part 3: Classic Problems of Synchronization
|
There are several famous synchronization problems in Computer Science. For Part 3, your job is to implement two of the following three problems. Each problem needs to be implemented twice - once in C using your user-level thread library, and once in Java using Java Threads. The implementations need to clearly demonstrate the behavior and interaction of the concurrently executing threads, but the details are left up to you.
- The Sleeping Barber Problem. A barbershop consists of a waiting room with n chairs, the barber room containing the barber chair, and of course the barber himself. If there are no customers to be served, the barber goes to sleep. If a customer enters the barbershop and all chairs are occupied, then the customer leaves. If the barber is busy with a customer but some waiting chairs are available, then the customer sits in one of the free waiting chairs. If the barber is asleep when a customer enters the barbershop, the customer wakes up the barber and sits in the barber chair. When the barber finishes with a customer, he goes to sleep if there are no waiting customers, and gets the longest-waiting customer otherwise.
Write a deadlock- and starvation-free program which simulates the barber shop. The customers should show up at semi-random intervals, and each customer's hair cut should take a semi-random amount of time.
- The Readers-Writers Problem. The second readers-writers problem is stated as follows: a data object is shared among several threads/processes. Some have read-only access to the object (The Readers), while others have read-write access to the object (The Writers). Writers have priority over Readers (that is, no Readers may start reading the object if a Writer is waiting). Any number of Readers can access the data object concurrently. Only a single Writer can access the object at one time.
Write a deadlock-free program that simulates the readers-writers problem. You must have more than 1 reader and more than 1 writer. The threads should attempt to access the data object at semi-random intervals. For the C/sthreads implementation, use the hash table you wrote in homework 1 as the data object. Note that the second Readers-Writers Problem is not starvation free because readers have to yield to writers.
- The Dining Philosophers Problem. This problem was invented by E. W. Dijkstra in 1965. It's stated as follows: there are five philosophers, five bowls of rice, and five chopsticks around a table. The philosophers spend their whole life thinking and eating. They have no use for chopsticks while they are thinking. From time to time a philosopher gets hungry, in which case she picks up the chopsticks to either side of her, eats until full, and puts the chopsticks back down. However, if a neighbor is using the chopstick, the philosopher must wait until the neighbor puts it down before she can pick it up. You can find a picture and a more detailed description on p.209 of Silberschatz.
Write a deadlock- and starvation-free program which simulates the Dining Philosophers Problem.
Hints
- Chapter 7 of the Silberschatz book will be invaluable in doing this part of the assignment. All three problems are described in this chapter.
- The implementation details will be slightly different between the C and Java programs. This is due to the non-preemptive nature of user-level sthreads. Think about critical points in your code that must contain sthread_yield() calls, as well as ways to simulate an unexpected timer interrupt and context switch (perhaps using randomness and sthread_yield() calls).
- Some of these problems may be easier to implement using monitors. Java has built-in monitors (synchronized keyword), but sthreads does not. You could try implementing a monitor using the lower-level synchronization primitives, and use the monitor to solve the problems.
- Check out the Java Threads tutorial at http://java.sun.com/docs/books/tutorial/essential/threads/.
- To test the correct behavior of your C implementation, you could recompile the streads library to use POSIX threads, and compare the behavior to what you see with your own user threads. Simply run ./configure --with-pthreads from the top-level directory of simplethreads, followed by make clean && make
| Part 4: Implement a Multithreaded Web Server
|
Every web server has the following basic algorithm:
- Web server starts and listens (see listen(2)) for incoming
connections.
- A client (i.e. web browser) opens a connection.
- The server accepts (see accept(2)) the connection.
- The client sends an http request.
- The server services the request by:
- Parsing the request.
- Finding the requested file.
- Reading the file.
- Sending a set of http headers, followed by the contents of the file, to the
client.
- Closing the connection.
- The client displays the file to the user.
The sioux webserver in the web directory implements the
server side of the above algorithm.
For part 4 you will make sioux into a multithreaded web server. It must use a
thread pool approach; it should not create a new thread for each request.
Instead, incoming requests should be distributed to a pool of waiting threads
(this is to eliminate thread creation costs from your experimental data). Make
sure your threads are properly and efficiently synchronized. Use the routines
you implemented in part 2, and the experience you gathered in part 3.
Note that you are implementing an application now. That means the only
interface to the thread system that you should use is that described by sthread.h
(as distributed in the tar.gz). Do not use functions internal to sthreads
directly from sioux.
You should accept a command-line flag indicating how many threads to use.
In testing, you may encounter "Address already in use" errors. TCP connections
require a delay before a given port can be reused, so simply waiting a minute
or two should be sufficient.
Because we have not used asynchronous IO in sioux, it will be very
difficult to obtain good performance using the user-level threads. In
some cases, it may be difficult to even get correct behavior at all
times (e.g., if no new requests are sent, existing requests may not be
serviced at all). We recommend using kernel-level threads for this part.
| Part 5: Analysis and Report
|
Design Discussion
Your report should include a section on the design of your user-level threads,
synchronization primitives, and webserver. Discuss the goals of each, how well
your design meets those goals, and the tradeoffs that were made. Justify your
design decisions as compared with other possible designs. Goals for some
aspects (e.g. synchronization) are discussed in the text; for others, you need
to determine what appropriate goals are. Some goals you
may wish to consider for all systems code are speed, complexity, and usefulness.
Experiment
For your analysis, design an experiment to either:
- Compare the performance of CPU-intensive code in simplethreads
when using user-level threads vs. kernel-level threads. Parameters
you might vary include (but are not limited to) the number of
threads, amount of contention for synchronization primitives (do
threads rarely conflict for locks, or have to wait almost every
time?), and amount of fake preemption (sthread_yield() calls). Make
sure your experiment does no IO during the timing portion (not even
printf). You will need to create a CPU-intensive multi-threaded
application designed to stress the thread package, which could be,
for example, a
parallel computation of matrix multiply, or a simple
system for passing messasges between threads through queues (similar
to what you might create for sioux, but without the IO). Your
goal should be to determine for what workloads the differences
between user and kernel-level threads are important, and to
generalize from the specific benchmark you create.
- Understand one aspect of the performance of your multi-threaded
sioux using kernel-level threads. Parameters include size of your
thread pool, size of files requested, number of simultaneous clients,
and methods for distributing the work to the thread pool. Your
experiment should be focused on how the multi-threadedness of sioux
affects performance, not the base performance of the webserver (which
could certainly be improved).
This experiment should be conducted in the
standard scientific method. It should explore the performance
of the server under a variety of different conditions chosen to
confirm or deny various aspects of your hypothesis. You may want to
go over your experimental design with a TA.
There are several variables to examine in either option. While you
will probably need to vary at least a few parameters to gain a good
understanding of the behavior of your system, keep in mind that a good
experiment only varies one parameter at a time. You should also make
sure to repeat each trial several times, to increase the
confidence in your data.
Include a presentation of your experimental design, data, analysis, and
conclusions in your report.
Conclusions
Discuss conclusions you have reached from this project. What recommendations do
you have for designers of thread systems? Can you recommend user threads or
kernel threads? Why? What other features might be useful?
Timing on the Pentium 4
To help you conduct microbenchmarks, we have provided an example using
the Pentium time stamp counter to obtain cycle-accurate timing
information. The clock speed, in MHz, of a Linux machine can be found
by examining the file /proc/cpuinfo. The sample code can be
found on coredump/spinlock in /cse451/projects/timer.tar.gz or here. (Unfortunately, we do not have sample
code for PowerPC timing.)
Using the Web Benchmark
The WebStone web benchmark tool has been installed on spinlock and
coredump as /cse451/projects/tools/bin/webclient.
It measures the throughput and latency of a webserver under varying loads. It
simulates a number of active clients, all sending requests in parallel (it does
this by forking several times). Each client requests a set of files, possibly
looping through that set multiple times. When the test is complete, each client
outputs the connection delay, response time, bytes transfered, and throughput
it observed (depending on the server, the clients may all observe very similar
results, or the data may vary widely). The tool takes the following arguments:
-
-n CLIENTS
specify the number of parallel clients to simulate.
-
-l LOOPS
specify the number of times each client should fetch the files.
-
-w SERVER
specify the hostname of the webserver (when sioux is started, it prints a URL
including the hostname).
-
-p PORT
specify the port number (when sioux is started, it prints a port number).
-
-u URLLIST specify a file containin a list of URLs to fetch, one per
line, each followed by a weight (e.g. 1).
All of the above parameters are required. The URLLIST file should
contain one relative URL (just the file name) per line followed by a space and then a number (the
number is the weight representing how often to request the file relative to
other files in the list - most likely, 1 is the value you want).
For example, to test a webserver on almond.cs.washington.edu, with two
simulated clients each fetching the index.html file twice, one would
run:
/cse451/projects/tools/bin/webclient -w almond.cs.washington.edu -p 12703 -l 2 -n 2 -u ./urls
Where the file urls would contain the following single line:
/index.html 1
Please turnin one copy of the project per group. It would help us if
you select one group member to execute all turnins (only the last
submission will be graded).
Parts 1, 2, and 3
In your top-level simplethreads directory, run make dist. This will
produce a file named simplethreads-1.X.tar.gz. Make a new directory
called username where username is your
CSE login and move simplethreads-1.X.tar.gz into that directory.
Submit this directory using the turnin(1L) program under project name
project3a by 11:00 am on Wednesday, May 12th. Turnin will not work on
coredump/spinlock, so you'll need to use attu.
Run tar -tzf simplethreads-1.X.tar.gz and check to make sure
all simplethreads files, and any new files you have added, are
listed. (For parts 4 and 5, make sure any files from your experiment
are included.)
All submitted files should be in text format. Word documents should
not be submitted (by turnin or email).
Parts 4 and 5
Follow the same instructions as for parts 1 - 3. Turnin a final version of
your code including any scripts or other files you used in your experiment by
11:00 am on Monday, May 17th. Submit it under the project
name project3b.
Turn in your written report on Monday, May 17th at the beginning of lecture.
|


 CSE Home
CSE Home 