Please submit both code and writeup online by 6:30pm PST on Friday, May 6, 2016. Please provide all code (sufficiently commented) so that we can run it ourselves. Submit your writeup as a PDF and limit to four pages with reasonable fonts and margins.
1.0 Read the paper Empirical Analysis of Predictive Algorithms for Collaborative Filtering. You need to read up to Section 2.1, and are encouraged to read further if you have time.
1.1 The dataset we will be using is a subset of the movie ratings data from the Netflix Prize. You can download it here. It contains a training set, a test set, a movies file, a dataset description file, and a README file. The training and test sets are both subsets of the Netflix training data. You will use the ratings provided in the training set to predict those in the test set. You will compare your predictions with the actual ratings provided in the test set. The evaluation metrics you need to measure are the Mean Absolute Error and the Root Mean Squared Error. The dataset description file further describes the dataset, and will help you get started. The README file is from the original set of Netflix files, and has been included to comply with the terms of use for this data.
1.2 Implement the collaborative filtering algorithm described in Section 2.1 of the paper (Equations 1 and 2; ignore Section 2.1.2) for making the predictions.
Extra-credit Add yourself as a new user to the training set. To do this, you will need to create a new user ID for yourself. Select some movies that you have seen among those in the training set, and add your ratings for them to the training set. Extend your system to output predictions for the movies you haven't rated, ranked in order of decreasing ratings. Do you agree with the predictions of your system? Check out some of the top ranked movies that you haven't seen (but only after you have finished work on the project).
Problem writeup:
2.1 It is Year 2020- humanoid Robots live in the cities just like humans and they are not distinguishable from humans by their appearance however they have slightly different taste and preferences than humans! You work in a drive thru espresso shack where you serve three types of espresso drinks: Latte, Machiatto and Americano. You want to distinguish Robots from humans because you then would use fake chemical milk in Robots coffee which is much cheaper than natural milk! A real human customer would order Machiatto with probability 0.25, Latte with probability 0.5 and Americano with probability 0.25 while Robots are equally likely to select any of the 3 coffee drinks. Based on the statistics revealed in the news 80% of the population are humans while 20% are robots.
a. You see a customer orders Americano, what is the probability that the customer is human?
You decide to install a camera to read the plate number of customers car. Humans are observed to have their plate number starting with 'H' 80% of the times, while robots plate number starts with 'H' only in 20% of the times.
b. What is the probability that a customer is Robot given that he/she orders a Machiatto and is observed that his plate number is started with ‘H’? (Hint: To solve this problem, start by drawing a Bays net with variables R(customer is Robot), C(the type of coffee a customer orders) and H(plate starting with ‘H’) and write down the conditional probability tables.)
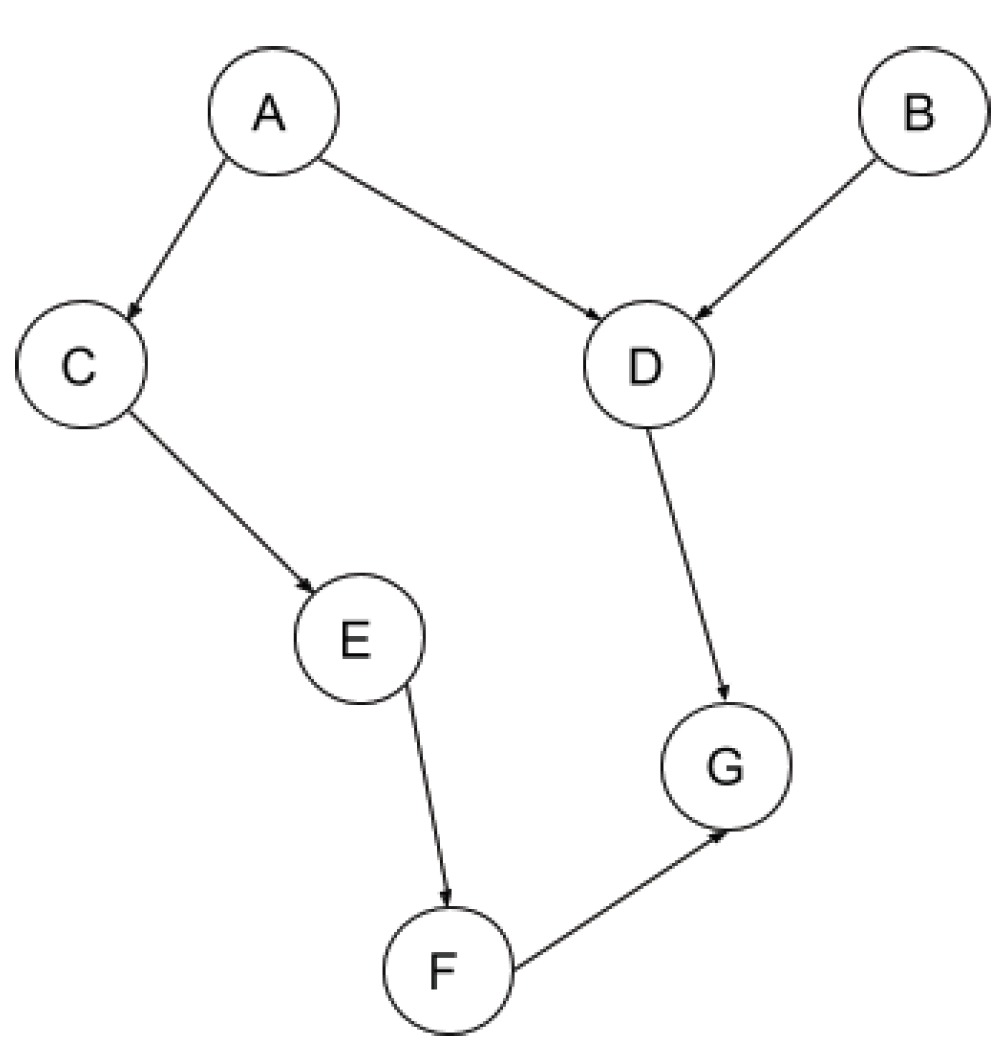
2.2 Consider the following Bayesian network:
Which of the followings are guaranteed to be true without making any additional conditional independence assumptions, other than those implied by the graph? (Mark all true statements)
2.3 Consider the following Bayesian network:
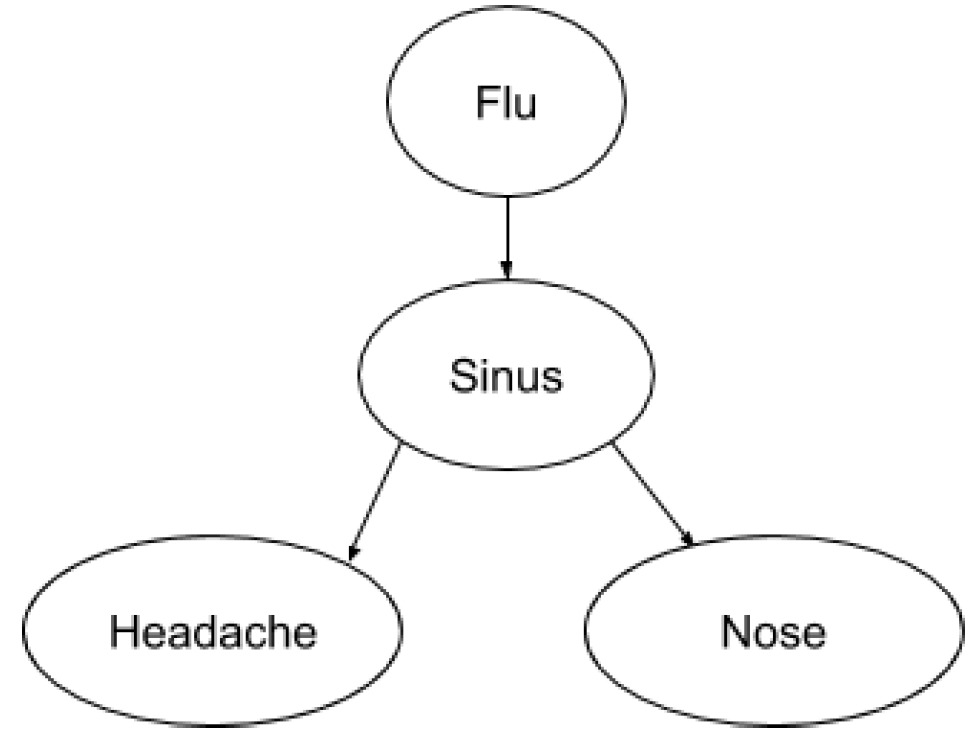
Any of the “Flue (F)”, “Sinus(S)”, “Headache(H)” and “Nose(N)” are Boolean nodes. Suppose you have a training set composed of the following examples in the form (F,S,H,N), with "?" indicating a missing value: (0,1,1,1), (1,1,0,0), (1,0,0,0), (1,0,1,1), (1,?,0,1). Show the first iteration of EM algorithm (initial parameters, E-step, M-step), assuming the parameters are initialized ignoring missing values.