EE/CSE 576 Spring '17 Homework 3: Content-Based Image Retrieval
Date Released: May 1, 2017
Date Due: May 13, 2017 (Saturday) 11:59 P.M.
Late Date: May 15, 2017 (Monday) 11:59 P.M. (Late Policy: 10% off per day)
Required files
Download the zip file here.
The zip file contains 4 folders. The 'Code' folder contains the code files, the 'Database' folder contain the database images in .ppm format (You can use IrfanView to view such images), the 'ImageView' folder contain the same images as in the Database folder but in .jpg format and the 'Thumbnails' folder contains the thumbnails of the database images to be used to display the results. The images in 'ImageView' are just for your viewing, code is written so as to read the .ppm images and display the thumbnail images in the application window after executing the code. For this project, significant parts of mainwindow.cpp and mainwindow.h files have been changed, so you may want to take a look at these apart from the Project3.cpp file which you need to edit. Please read all the comments in Project3.cpp file carefully before you start writing code. If you want to scale up your application window for better viewing, refer to the 2 commented lines in the main.cpp file.
(1) After opening the project file in Qt, make sure that 'Projects' tab -> 'Build Settings' -> 'Shadow build' checkbox is unchecked, otherwise the project will not build. (2) Under 'Projects' tab -> 'Run Settings' (Click 'Run' under 'Build and Run' in the left pane), select the 'Code' folder as the current 'Working directory'. (3) This homework deals with images in QImage format.
Description
In this assignment, you will develop a content-based image retrieval system that retrieves database images based on the similarity between their regions and those of a query image.
 |
 |
| mountain image |
segmented by color |
 |
 |
| another mountain image |
segmented by color |
What To Do
The main idea is to represent each image (the database images and the query image) by a set of regions obtained from color clustering and connected components and extract the region attributes. Then, come up with a distance function between two images in this representation, and use this distance function to find the images most similar to a query image.
- For each image in the database the following procedure should be performed:
- Run your K-means color clustering on it to obtain a labeled cluster image. The RandomSeedImage clustering code is provided in the starter code. You are free to tune its parameters or use a better clustering algorithm from Homework 1. Note: The Clustering() function uses QImage format of the input image and returns an image with each pixel value replaced by the cluster number (not the mean RGB values of the cluster) the pixel belongs to.
- Run connected components on it to obtain a labeled segmentation image. The code for this step is given in the starter code and ideally you don't need to change it.
- Perform some noise cleaning/region merging operations to improve the regions. Don't vary any parameters between images. You can define a threshold to retain only those regions exceeding a minimum size (number of pixels in the region) so as to avoid spurious regions. No starter code is provided for this step.
- For each final region, compute at least the following attributes:
- size (given in starter code)
- mean color, in RGB or whatever space you like (RGB space given in starter code)
- at least the following co-occurrence texture features (no starter code; use spatial relationship d = (1,1) and use grayscale version of the image):
- energy
- entropy
- contrast
- centroid - mean row and column values of the pixels in the region (no starter code)
- bounding box or other representation of where the region is - e.g. x and y co-ordinates of the corners, area of the rectangle etc. (no starter code)
- Store the attributes in the given data structure (see starter code). We'll refer to the feature vector for image I as F(I)
- Develop a distance measure that will compute the distance Dist(I1,I2) between F(I1) and F(I2) for any two images I1 and I2. To do this, you need to find a correspondence between the regions of I1 (query image) and the regions of I2. Compute this correspondence greedily. That is, for each region in I1, find its closest match in I2, and so on. The mapping need not be one-to-one. If you like and have time, you can also compute the optimal correspondence. You can do this with an exponential search procedure, since the number of regions will be small. Graph distances are discussed in S&S 11.6.
Once you have the correspondence (starter code provided but not optimal; you may need to change), the distance between I1 and I2 should be some function of:
- difference in attributes of corresponding regions
- difference in number of regions
We would like you to experiment with at least 2 different distance measures and tell us what they were and which one worked best and is used for your final results. Distance measures can vary in what attributes you used and also in the kind of metric you use to compare 2 vectors. Euclidean distance is only one such metric.
Build and compile the project. In the application window, click the 'Load database' button to load the database. This will take each database image as input and extract and store its feature. Then click the 'Open Query Image' button and select the image you want to use as the query from the 'Database' folder. This will load the query image and extract its feature. You can click 'Load database' first and then 'Open Query Image' or vice versa. Finally, click the 'Query database' button. This will compute the distance between the query feature and each of the features of all 40 images in the database, sort the distances in ascending order and display the corresponding database images accordingly. The query image will have distance zero (or close to zero since random clustering results in different features for the same image when loaded as query and when loaded as part of the database) to itself, and similar images will have smaller distances than dissimilar ones. The starter code automatically sorts the distances and displays the thumbnails of the images and the corresponding distances in the desired order. You just need to write the distance functions. To use distance function 2, check the box above 'Query database' button in the window. The 'Progress' textbox shows the progress of the steps being executed. You can click the 'Reset' button to start a new application window, erasing the previous one. You can check these out with the starter code to see how the buttons function and what to expect from your code. The code takes some time to execute, so don't lose patience as long as no error is thrown. Most probably, you will see something coming up in the 'Progress' textbox soon. Useful tip: To debug through your feature extraction code, just perform 'Open Query Image'. 'Load database' essentially performs the same operation as 'Open Query Image' but on all 40 images instead of one. So if your code works fine on one, you are good to go. If you want to check your implemented features individually, just comment out the others and use one at a time.
In order to test your system, use the following images as the query image:
- beach_2
- boat_5
- cherry_3
- crater_3
- pond_2
- stHelens_2
- sunset1_2
- sunset2_2
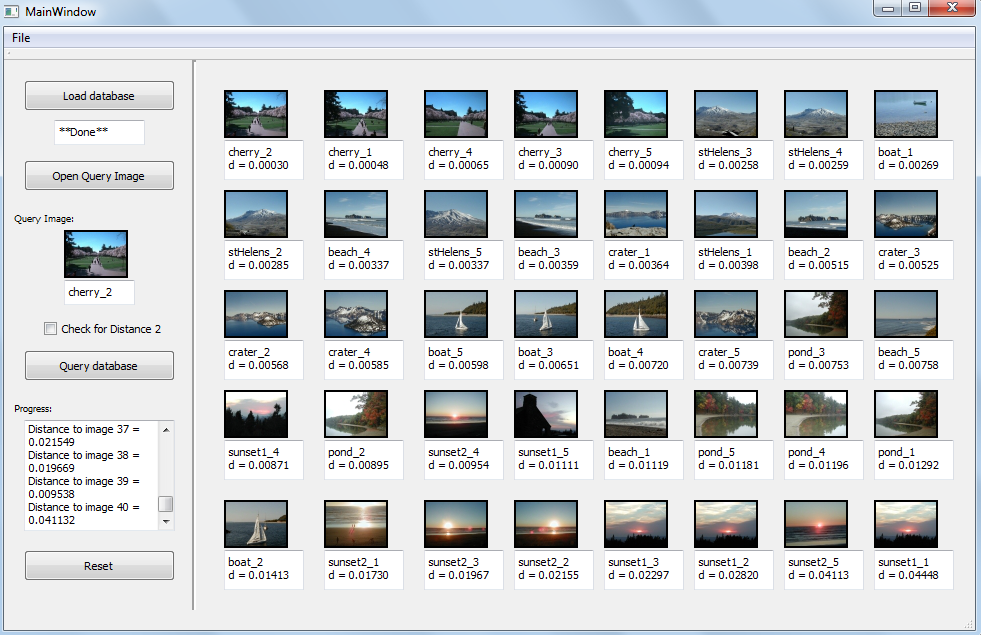
Example Query Results for cherry_2 (screenshot of application window; you should submit similar screenshots) (Note: The result is obtained with the starter code + Euclidean distance measure. This is kind of an ideal result where all cherry images are the top retrieved images and similar images are also positioned together)
What to turn in
You should turn in the 'Project3.cpp' file and a report in PDF format (with name report.pdf). The report should describe:
the attributes you implemented - with some details
the distance measures you tried, which one works best and why
16 screenshots, with 2 screenshots using 2 distance measures placed side by side for each of the 8 query images
Proper comments about the results to show your understanding
Your code should be well-structured and well-commented. In case you edit any other file, submit that as well, or you can submit the entire 'Code' folder in that case. Upload the necessary files HERE. This is a one-person assignment. You may discuss it, but please turn in your own individual work. Plan your work early.
Evaluation (Total points: 25, Extra credit: 10)
- Working implementation of all the required parts: 10 points
- Region attributes: 5 points
- Distance measure: 5 points (3 points for trying different distance measures + 2 points for discussing which worked best and why)
Quality of results: 7 points
Completion, quality and organization of report: 5 points
Quality of code including code structure, comments and documentation: 3 points
Extra credit:
- Experiment with other features: 1-5 points, depending on your work
- RAG construction and related distance: 5 points