Project 2 CSE 473 Fall 2009: Flesh Finding
|
|
|
|


Due: Monday December 14 11:59pm
The purpose of this assignment is to try out the Information Gain technique for constructing decision trees in the context of trying to identify skin pixels in color images. There are two parts to the assignment: the computer vision part and the decision tree part.
I Computer Vision
In the computer vision part, you will read color images (RGB) into three two-dimensional arrays and extract feature vectors from some of the pixels. The training image set consists of 15 color images of people. Each of these has a corresponding mask image in which the pixels of the skin are 1's and the rest 0's. You will choose from each training image a subset of the skin pixels and a subset of the nonskin pixels for use in training.
Suppose you have a color image stored in three 2D arrays R, G, and B. Suppose that you have identified pixel [i,j] as either a skin pixel or a nonskin pixel and want to add it to the training vector set. You will construct a feature vector with 11 components. Ten are features, which we will later refer to as F1 to F10, and the last one is the class. The vector will be:
[R, G, B, r, g, b, H, S, V, T, C]
- R, G, and B are the original values R[i,j], G[i,j], B[i,j].
- r, g, and b are the normalized color values
- r = R / (R+G+B)
- g = G / (R+G+B)
- b = B / (R+G+B)
- H, S, and V form another color space in which H is the hue, S is the saturation, and V stands for value and is related to intensity. We will give you the code for computing them.
- T is the texture feature. It is a count of how many edge pixels there are in a 5 X 5 neighborhood around pixel [i,j]. To produce it, you first calculate an edge image from the original image using the Sobel edge operator. Then, for pixel[i,j] you merely count how many of the pixels in its 5 X 5 neighborhood are edge pixels in the edge image. Pixels in homogeneous areas should get close to zero for T, while pixels in busy areas should have higher values.
- C is the known classification: 1 for skin and 0 for not skin
The final set of training vectors should come from all 15 face images, which are of people from several different races. All of the skin pixels and all of the nonskin pixels are too much. You should select 50000 skin pixels and 50000 nonskin pixels from the whole set of training images as your training set (less if you are short on space). As you create the training vectors, write them to disk, so you can then use the data set to work on creating the decision tree without running the computer vision part over and over again. You probably also want to examine some of the training vectors yourself, to make sure they make sense. Do this on a small subset.
II Decision Tree
The second part of the assignment is to use the training vectors to construct a decision tree classifier and use it to label the pixels of the test set of images as skin and not skin. Then you will display the results with code we provide. You should use the Information Gain method of constructing the classifier, which is in the lecture notes and book. Here are some details.
- The decision tree training method is a recursive procedure that starts at the root of the tree to choose which feature (F1, F2, ..., or F10) has the greatest information gain over the entire training set S. The 10 features are in different spaces, so we will assume here they have all been normalized to lie between 0 and 1 (or select your own method). Given that space, it makes sense to use 10 equal-sized bins. But when you split a node into children based on values of a certain feature (say R), the children will have only a subset of the R values that the parent had. So if you split later on with the same feature R (which often happens), the 10 bins should only span the values of R actually present at that time. You'll need to work out how to do this.
- You will compute the information gain for each feature Fj.
- First compute Entropy(S) for the training set S at this node. At the root, this will be the whole training set, but when called recursively, it will have a subset of S.
- Next construct 10 bins: S1 to S10 for the 10 branches out of this node. Si = {s | Fj(s) lies in the range of values for bin i} Each training vector will belong to exactly one bin. The weight Wi of bin Si is the number of vectors in Si divided by the number of vectors in S. In other words, it is the percentage of vectors that fall into bin Si.
- Now that the 10 subsets S1 to S10 have been constructed, compute the entropy of each subset: Entropy(Si).
- Then the information gain for feature Fj is IG(Fj) = Entropy(S) - the sum for i = 1 to 10 of Wi * Entropy(Si).
- Select the feature Fj that has the highest value of IG. Put this feature's index (j) into the current node. Reconstruct (if not saved) the subsets Si for each of the 10 bins. Construct 10 children of the current node, one for each subset. Call the procedure recursively for each of the 10 children.
- So far, this is infinite. Although we would like to stop when the entropy of a newly created node is zero (pure node), this will rarely happen. Instead, use a threshold T (such as T=0.6). When the Entropy of a newly created node is less than T, make that node a leaf node, and assign it the label of its majority class, which will be a 1 (skin) or a 0 (no skin). You can experiment with different thresholds or depths.
Here is an example using just the features R and G:
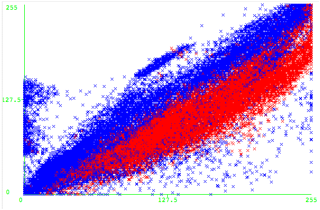
The plot above shows the values of R vs G in deciding the type of a pixel. The horizontal axis is R and the vertical axis is G. The red spots are skin and the blue spots are not skin. The following is a handcrafted decision tree that can classify pixels as skin.
Decision tree using two features: R and G:
R <= 56
| G <= 38
| | R <= 42
| | | G <= 27
| | | G > 27
| | R > 42
| | | G <= 20: 0 (171.0/43.0)
| | | G > 20
| G > 38: 0 (8356.0/174.0)
R > 56
| G <= 168
| | R <= 96
| | | G <= 78
| | | G > 78
| | R > 96
| | | G <= 109
| | | G > 109
| G > 168
| | R <= 198
| | | R <= 191: 0 (3133.0/99.0)
| | | R > 191
| | R > 198
| | | G <= 198
| | | G > 198
Data Sets (download together with skeleton code)
- Training Data Color Images.
- Training Data Binary Masks.
- Testing Data Color Images.
- Testing Data Binary Masks. (Click to download) THIS GIVES YOU THE CAPABILITY OF COMPUTING STATISTICS ON THE TESTING DATA SET. THANKS TO GREG FOR PROVIDING.
Skeleton Code and Your part
In the project, we provide skeleton code that consists of a file "face.java" and a file "decisionTree.java" (Click to download) (New Version of face.java with overlay capability) . The face class contains steps for reading and writing image files, as well as extracting image features. In "decisionTree.java", you will need to fill in code for the "decisionTree" class, including class members that store the data structure of the decision tree, as well as the "Train" and "Test" functions of the class. You will need to use some of the computer vision code here to produce the results. You can also add other functions in the class. The Java Imaging (JAI) Library needed for running the code is here.
In the main file, training is performed by calling on the method "decisionTree.Train(int dataN, float[][] feature, boolean[] label)" in "face.java", where "dataN" is the number of training data, "feature" is a 2-D array with size "dataN*10" which stores the feature vectors for all training data, "label" is an array which stores the labels of all training data (true represents face pixel and false represents non-face pixel).
To test whether a pixel is a face pixel or not, the main file calls "decisionTree.Test(float[] feature)" in "face.java", where "feature" is an array of length 10, representing the feature vector of the current pixel. The returned value is a boolean type, either true (representing face pixel) or false (representing non-face pixel).
Testing the Classifier
You will test the classifier on both the training set and the testing set of color images. For the training set, you know which pixels are skin and which are not from the binary masks. Thus for each training image, you can compute the following statistics:
- TP = percentage of true skin pixels the classifier labeled as skin
- FP = percentage of nonskin pixels the classifier labeled as skin
- TN = perecentage of nonskin pixels the classifier labeled as not skin
- FN = percentage of true skin pixels the classifier labeled as not skin
Use the average over all training images of these statistics to produce a confusion matrix for the results of classifying the training set. For the testing set, we don't have the masks, so you will only be able to show the results as images using code we provide.
Report
Write a report for your project that describes any important details of your program and shows the results. For the training set, you will show for each training image, its 4 test statistics and the original image with classified skin pixels overlayed. Also show the confusion matrix for the whole training set. For the testing set, you will show for each testing image the original image with classified skin pixels overlayed. Discuss your results: how well the classifier worked and how you think it could be improved. In summary, for each set of experiments you will show
- the 4 statistics for each training image
- the confusion matrix for the training image set
- the skin pixels overlaid on the training image set
- the skin pixels overlaid on the testing image set
Two Experiments
Run the following two experiments for both the training set and the testing set, and write the results in the report.
- Classify image pixels using only two features: r and g. (Feel free to try other subsets such as R and G or H and S.)
- Classify image pixels using all ten features.
Discuss your results: how well the classifier worked and how you think it could be improved.
Turn-in Details
- Turn in both program and report (Here).
- Include all files needed to compile your program. Also include any additional data (files) you tested your program on.
- Please comment each method separately, describing its arguments, return value (if any), and, most importantly, its purpose. Also comment any important regions of code within a method; important loops or calculations that require explanation.
- Please include, in a text file with the code, a description of how to compile and use it.