File Systems Designs
Data Layout
- contiguous
- allocate consecutive blocks on disk
- metadata tracks the starting block number and the number of blocks
- how do you locate which block contains the ith byte of data?
- linked
- can allocate block anywhere on disk, each block stores data + a pointer to the next block
- metadata tracks the block number of the first data block
- how do you locate which block contains the ith byte of data?
- array
- store an array of block pointers, data blocks can be anywhere on disk
- limited by the size of array
- how do you locate which block contains the ith byte of data?
- extents
- one extent tracks a contiguous section of blocks
- track multiple extents via array and/or linked approach
- indexed/indirection
- instead of storing an array inside the metadata itself, stores it inside a block
- metadata tracks the (index) block holding an array of blocks
- keeps the inode size small, more disk op is needed to find a data block
- how do you locate which block contains the ith byte of data?
- multilevel indexed pointers
- track an array of blocks, some point to the actual data, some to an indexed block, some to a doubly indexed block
Case Study: Fast File System (FFS)
- designed for good disk performance
- linux ext2 (1993-2001) and ext3 (2001-2006) uses this design
- data layout: multilevel index
- inode (metadata) stores 15 pointers to track data location
- first 12 are pointers to data blocks
- pointer 13 is a pointer to an indirect block
- pointer 14 is a pointer to a doubly indirect block
- pointer 15 is a pointer to a triply indirect block
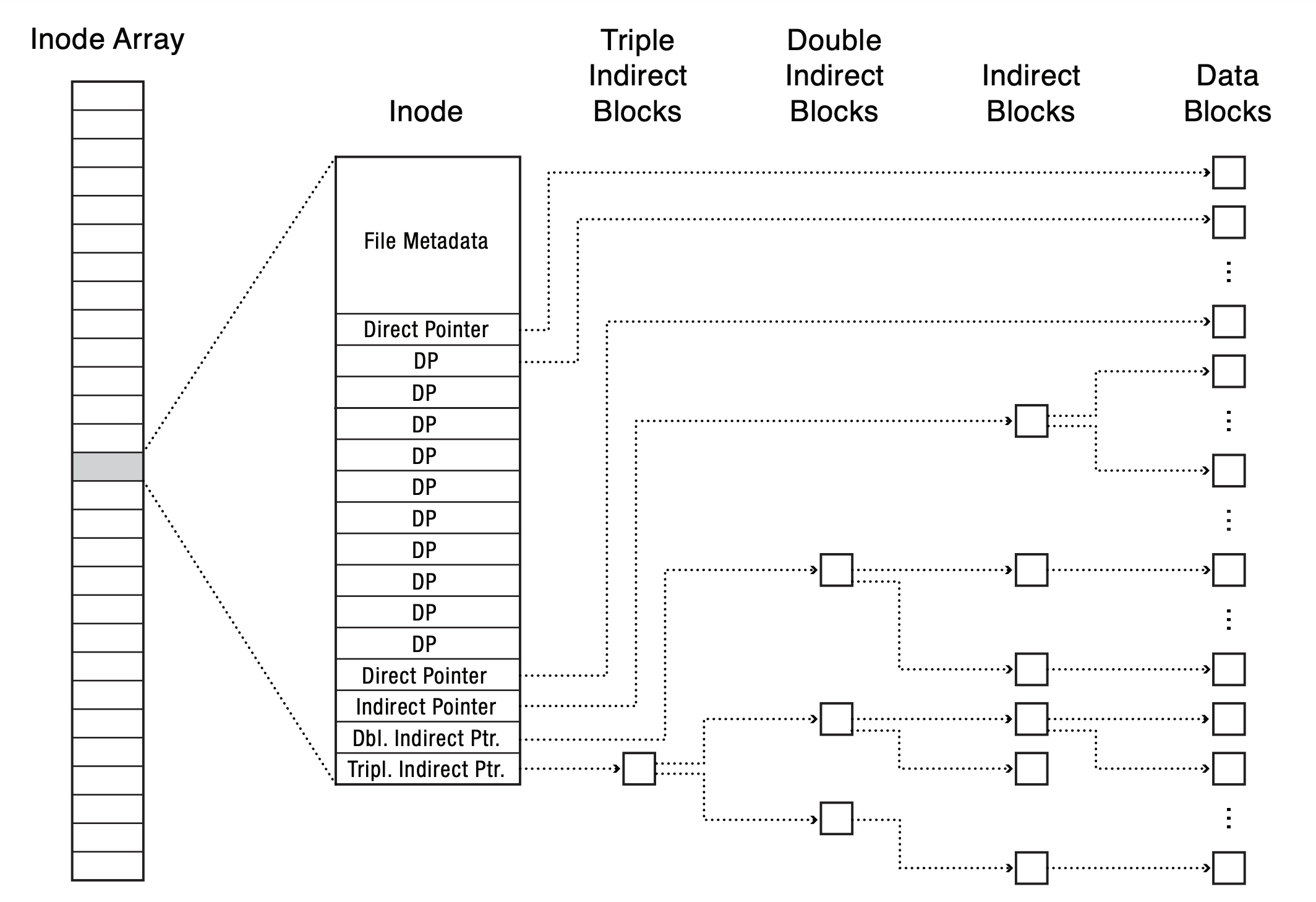
- can locate data for small files quickly while still support large files
- any limitation for file size with this layout?
- what would the inode look like if the file is only 100 bytes?
- what would the inode look like if we do a write at 0, and a write at a large offset (sparse file)?
- normally append happens when we write past end of file
- POSIX also has a
lseek system call that lets a process sets a file offset past its current size
- write at a large offset past end of file can also extend file
- what should happen when user read the gap section?
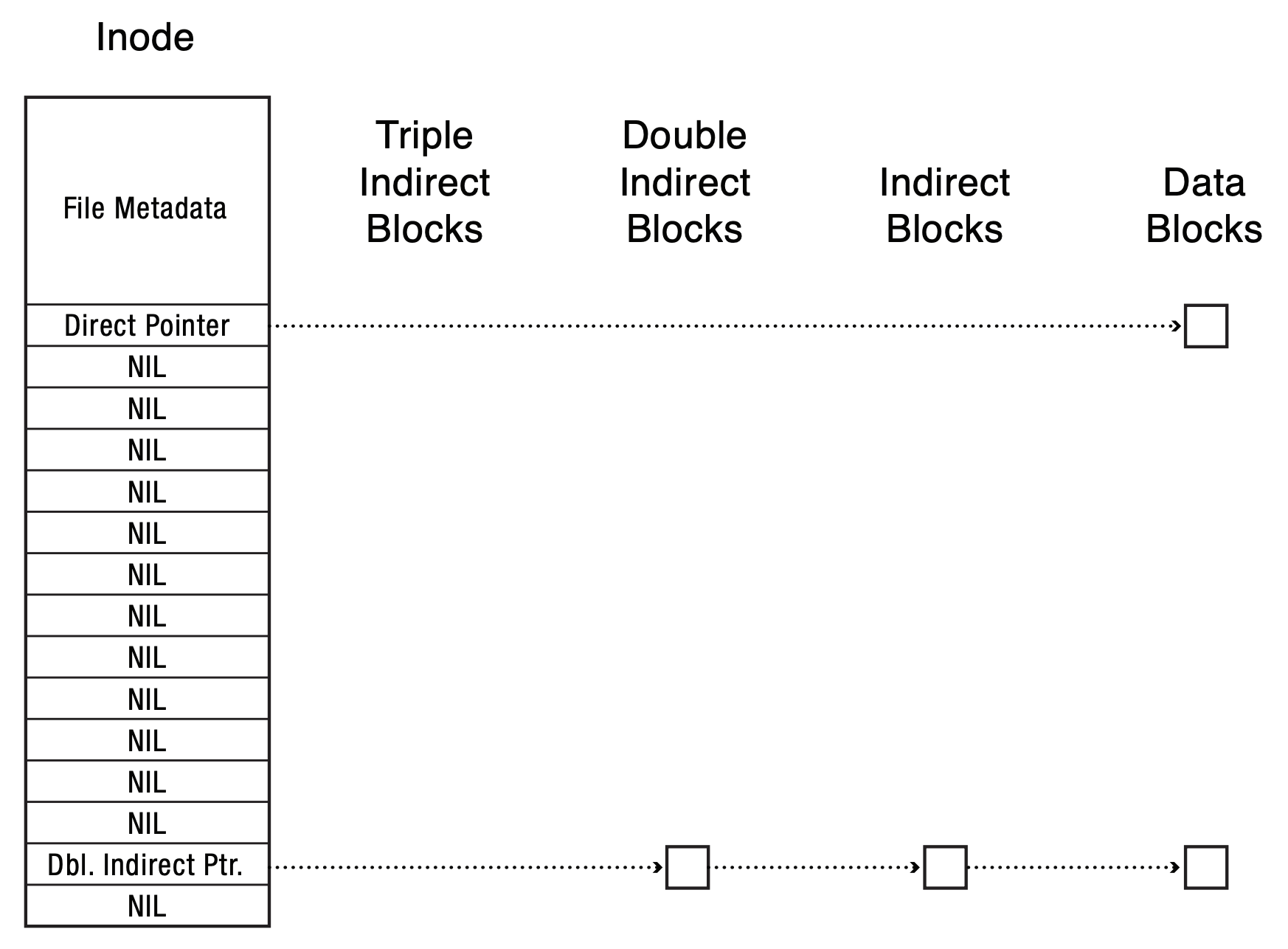
- design for disk: locality heuristics
- access nearby sectors are way faster than access random sectors on disk due to less arm movement
- if we place sectors that are likely referenced together close by, our requests can be served faster
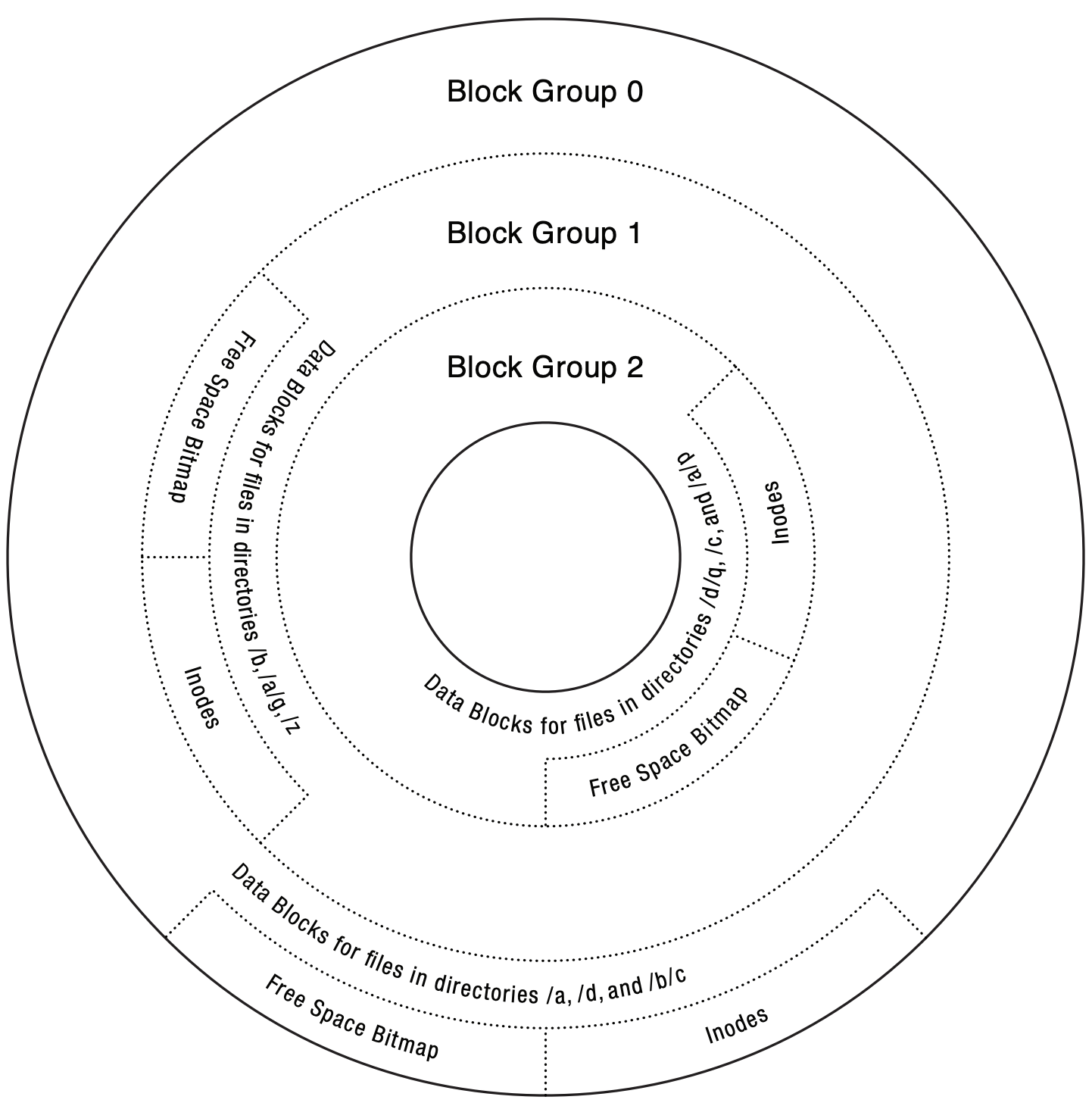
- block group placement
- group nearby tracks on each platter into block groups
- each group has its own inode array, inode bitmap (tracks inode usage info), and data bitmaps
- place related things within the same block group and unrelated things in different ones
- what's related? data and metadata of a file, files within the same directory
- what's unrelated? files in different directories, different directories (are these always unrelated?)
- exceptions for large file: what may happen if we use this approach on large file?
Case Study: New Technology File System (NTFS)
- The Windows filesystem
- Data Layout: Master File Table (MFT) & Extents
- MFT: table of records, 1KB record, most of the time one record = one metadata
- record tracks data location, but if data is small enough, store data directly in the record

- if data doesn't fit, record stores an array of extents for data
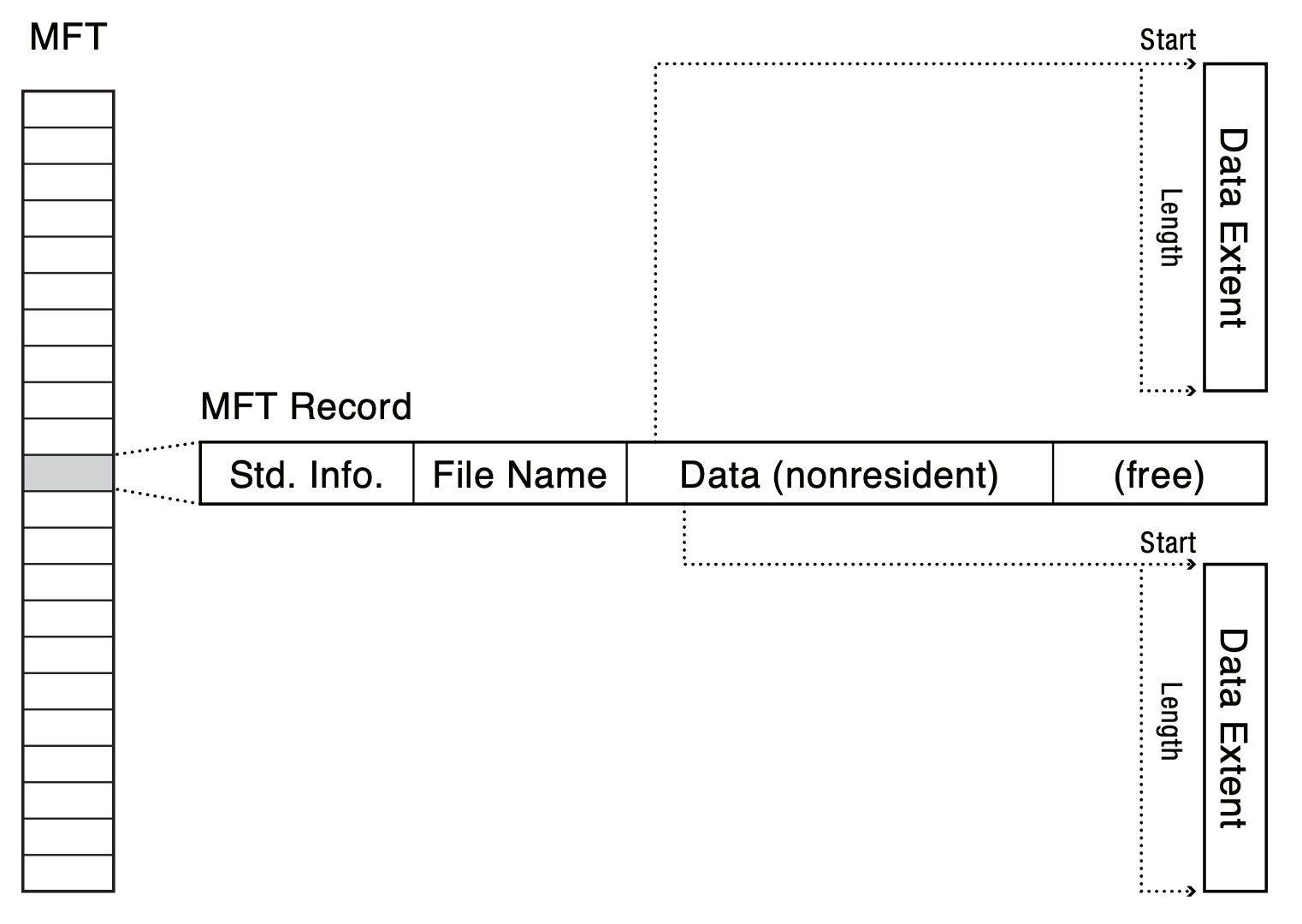
- if the array of extent is full, allocate another record and link to it
- > 1 record, attribute list is used to indicate what can be found in each record
- tells us file range of each record
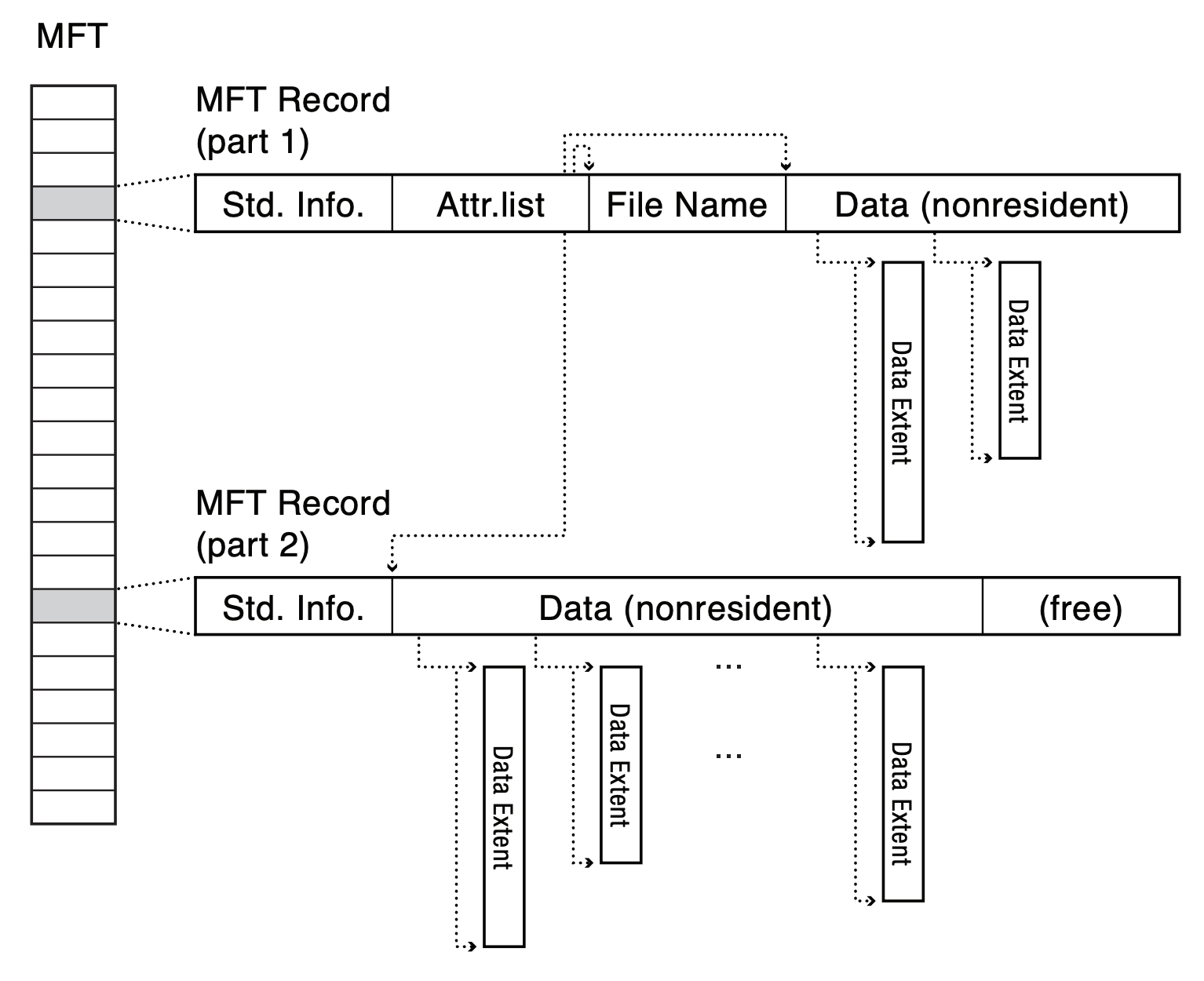
- if attribute list gets too large, it can be stored in an extent as well
- Locality
- caches a small section of the bitmap for allocation
- neighboring blocks are written close in time
- reserve space for MFT