File Systems
File System Basics
- software layer overview
- a map from name to bytes
- abstraction for storage devices but with much richer features
- read and write named data
- create and delete name data pair
- specify and enforce permission on named data
- how do we build such a system on top of storage devices?
- where do we place data on disk?
- how do we track information about data?
- how do we name and organize data?
Where do we place data on disk?
- need to track usage of hundreds of millions of sector/block
- can track multiples of sector/block instead of single sector/block
- use efficient data structures: bitmap (encode info in each bit)
- but... where should this bitmap live? if disk, how do we know where on disk?
- what information do we need to know?
- size, owner, permission, location of data on disk
- all considered metadata, also referred to as inode, file header, file record
- where should metadata live? if disk, how do we know where on disk?
How do we name and organize data?
- one option: just generate random string/bytes for a data, no explicit organization
- another option: use user defined name and a path that encodes organizational info
- file: user defined name for the data
- directory: a way to group and organize files
- implemented as a file where its data tracks files inside the directory
- since directory is just a file, we can have nested directories
- directory entry consists of name of file and the location of its metadata
- how do we locate metadata for directory?
- path:
/separated path consists of all directories leading to the file
/: root directory, metadata lives in a known location- to locate
/home/tom/foo.txt
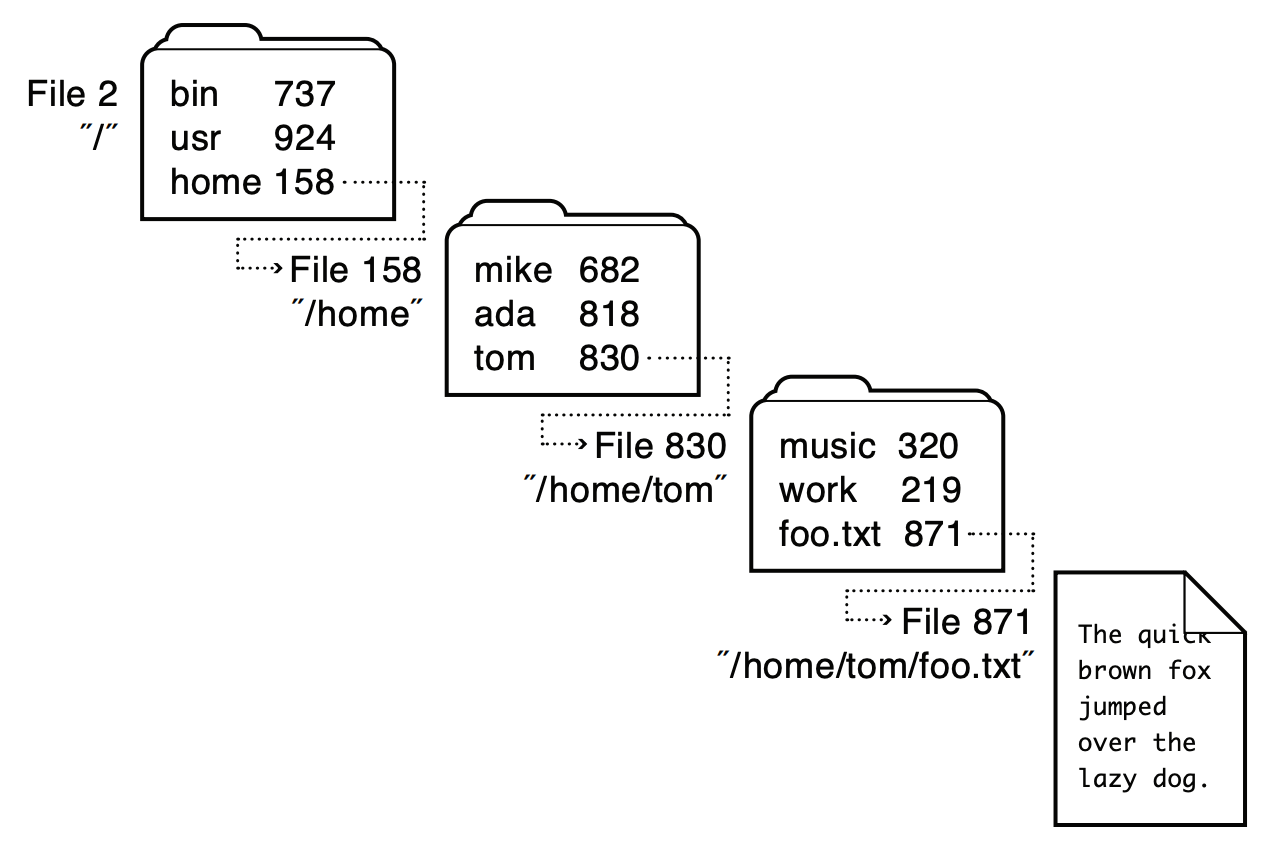
- start at the metadata for root, find its data, locate directory entry for "home"
- use the metadata for "home" to find its data, locate directory entry for "tom"
- use the metadata for "tom" to find its data, locate directory entry for "foo.txt"
- use the metadata for "foo.txt" to find its data
Filesys Deep Dive: Data Layout
- so far we just said metadata track where data is on disk, but how is the data laid out on disk?
- note that we want to support both small and large files
- basic techniques
- contiguous
- allocate consecutive blocks on disk
- metadata tracks the starting block number and the number of blocks
- how do you locate which block contains the ith byte of data?
- linked
- allocate any blocks on disk, each block stores data + a pointer to the next block
- metadata tracks the block number of the first data block
- how do you locate which block contains the ith byte of data?
- option 3: indexed
- use a block to store an array of allocated blocks
- metadata tracks the block number of the index block
- how do you locate which block contains the ith byte of data?
- combined techniques
- extents
- one extent tracks a contiguous section of blocks
- track multiple extents via array and/or linked apporach
- multilevel indexed pointers
- track an array of blocks, some point to the actual data, some to an indexed block, some to a doubly indexed block
Filesystem Design: Fast File System (FFS)
- designed in 1980s, designed for disk
- Linux ext2 (1993-2001) and ext3 (2001-2006) uses this design
- Data Layout: Multilevel Index
- inode stores 15 pointers to track data location
- first 12 are pointers to data blocks
- pointer 13 is a pointer to an indirect block
- pointer 14 is a pointer to a double indirect block
- pointer 15 is a pointer to a triple indirect block
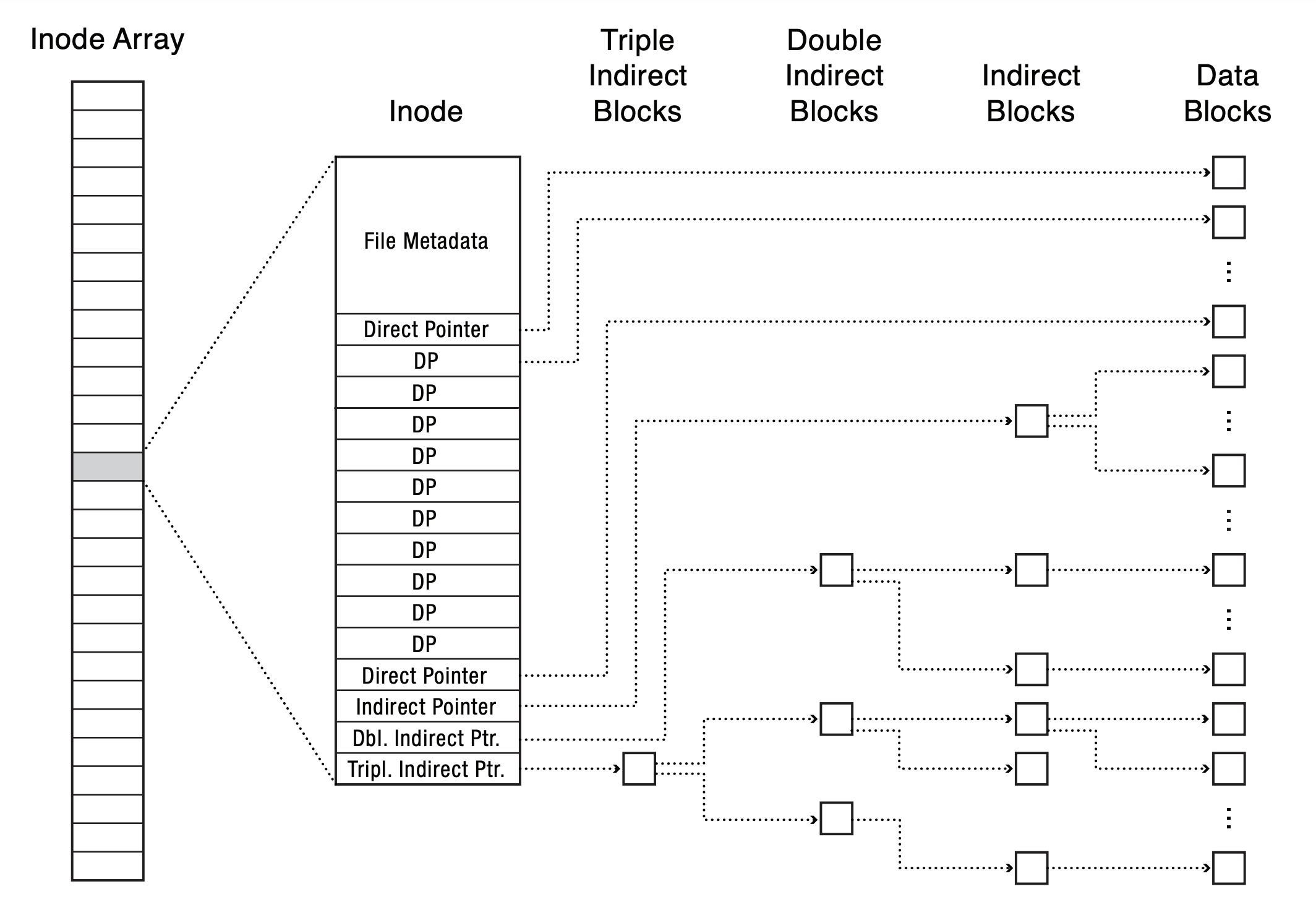
- what's the most and least number of blocks to read to locate a data block?
- what if we do a write at 0, and a write at a large offset (sparse file)?
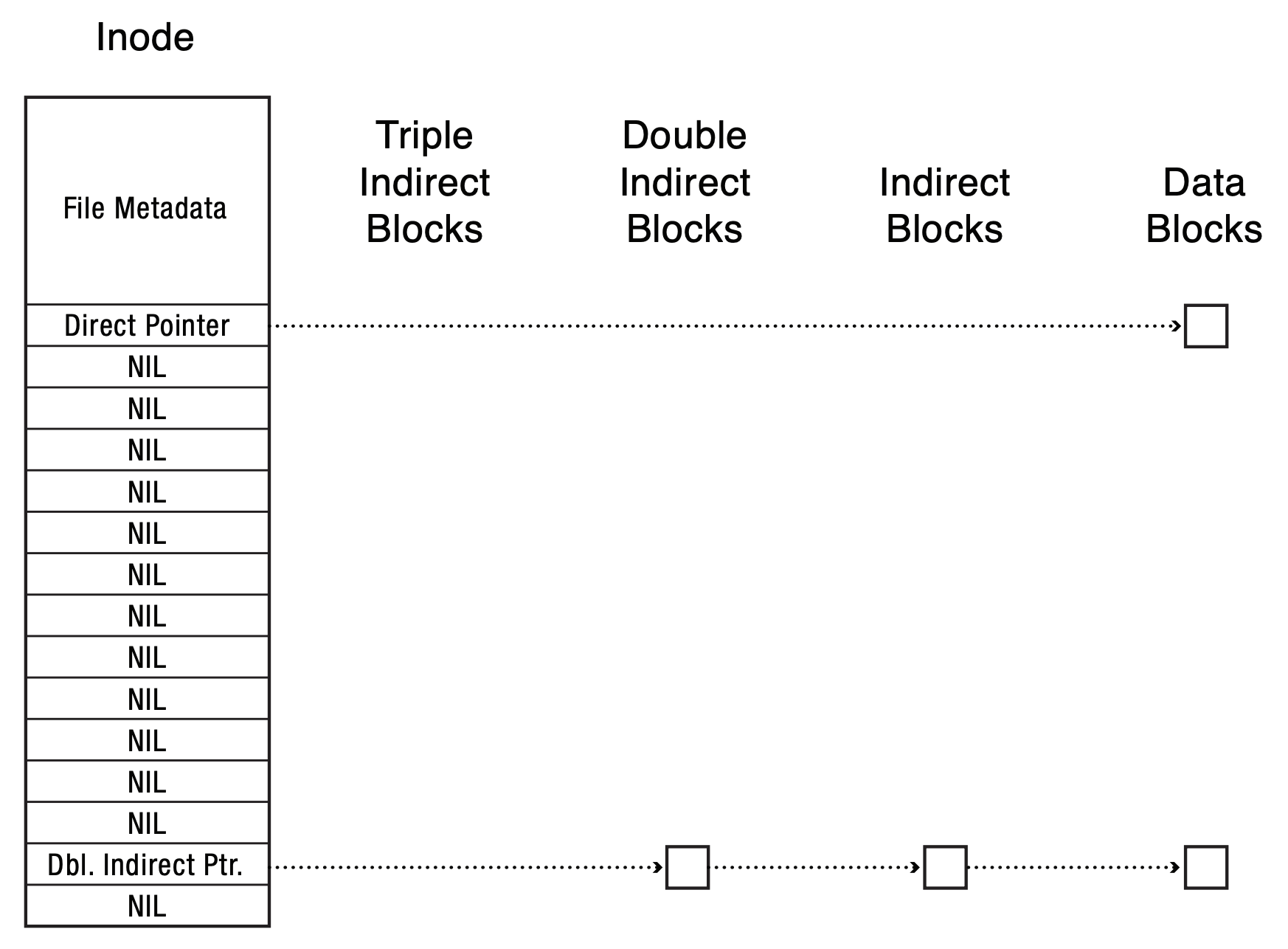
- any limitation for file size with this layout?
- Locality Heuristics
- when allocating blocks, a simple way is to use the first available free blocks using the bitmap
- if we do this, what do we know about our neighboring blocks?
- what is the performance for accessing neighboring blocks?
- what should the neighboring blocks store if we want user to enjoy good performance?
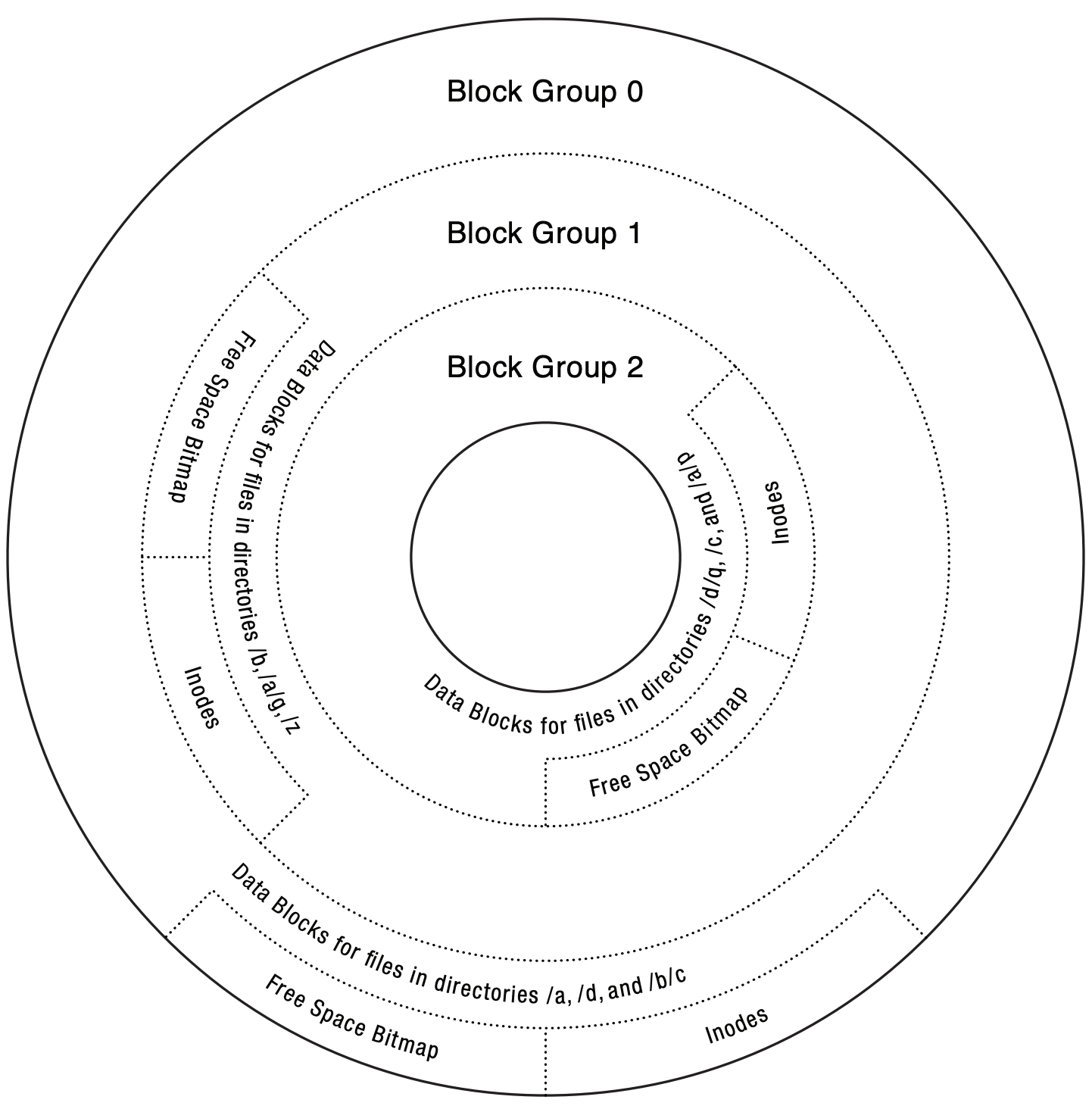
- Block Group Placement
- group nearby tracks into block groups
- each group has its own inode array and bitmaps
- place things in the same block group if they are likely to be accessed together
- data blocks of a file
- data and metadata of a file
- files within the same directory
- this is a design for good performance on disk, what would you do for SSD?
- what if there's not enough space in each block group to carry out the placement policy?
- Free Space Reserve
- if not enough space, data might be scattered among different block groups, bad performance
- kind of a contract: if you don't use up all of disk (reserve some space), you will see good performance
- designer of FFS suggests 10% reserve, if 0 reserve, the throughput tends to be cut in half
Filesystem Design: New Technology File System (NTFS)
- The Windows filesystem (1993-now)
- Data Layout: Master File Table (MFT) & Extents
- MFT: table of records, 1KB record, most of the time one record = one metadata
- record tracks data location, but if data is small enough, store data directly in the record

- if data doesn't fit, record stores an array of extents for data
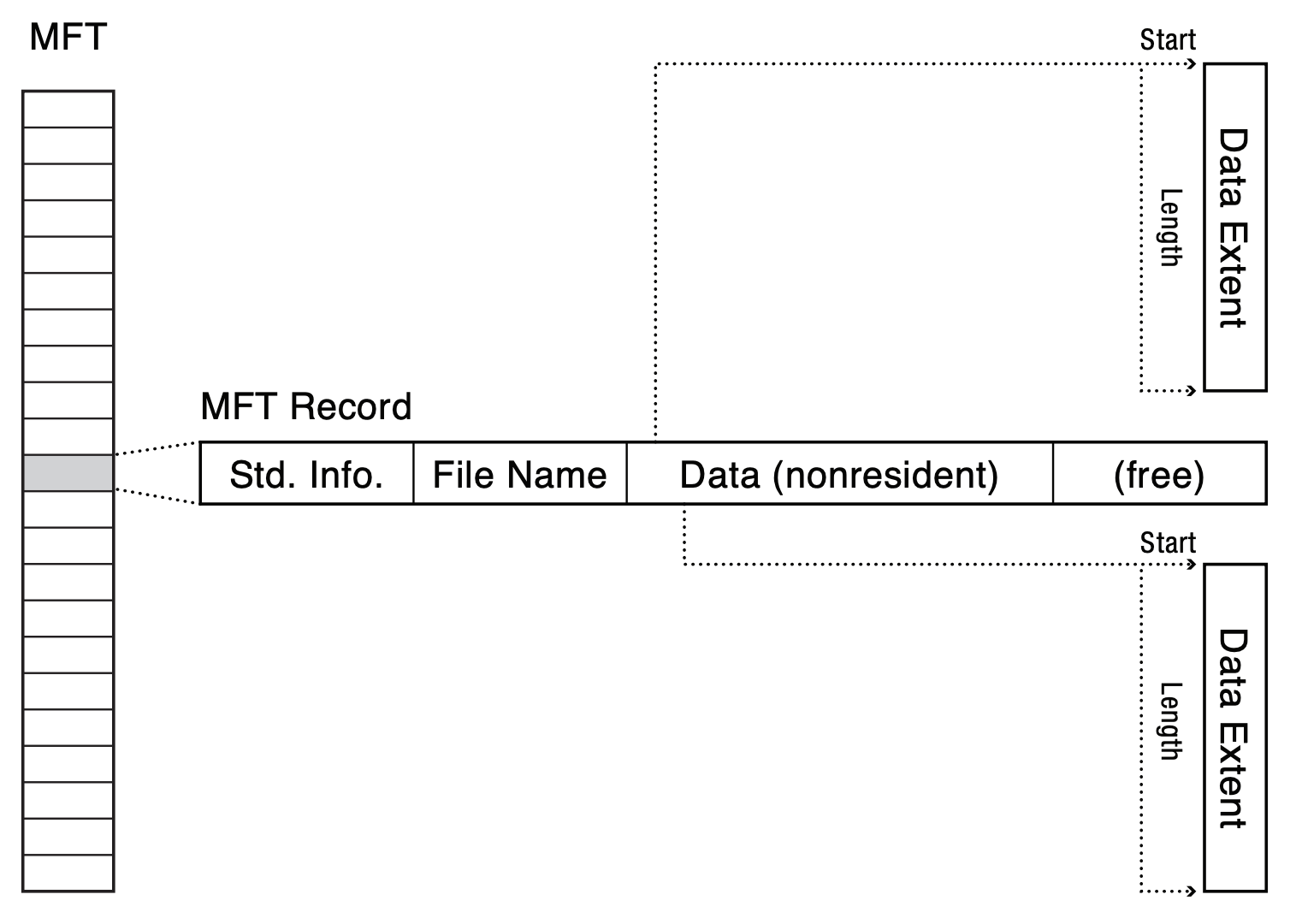
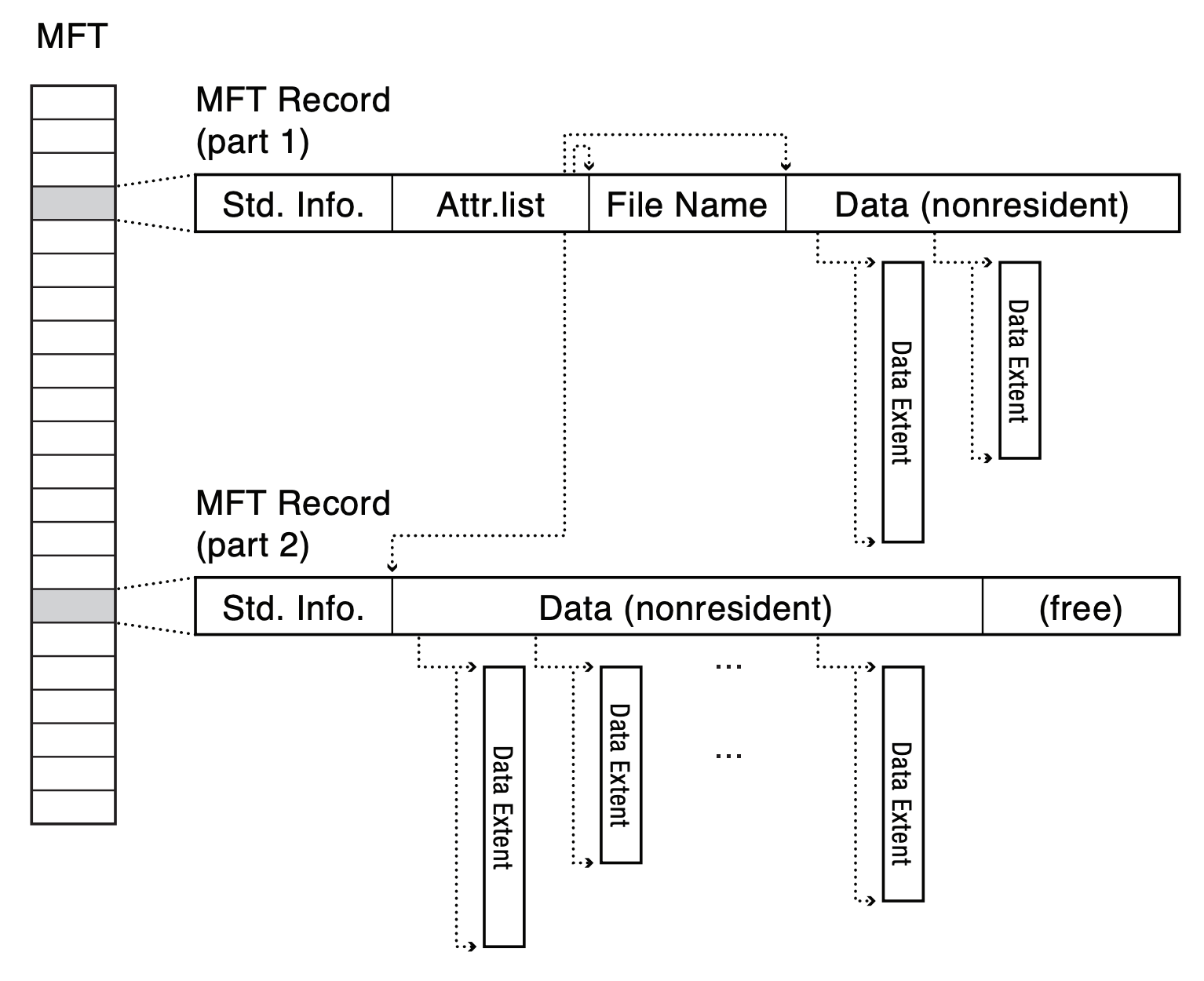
- if the array of extent is full, allocate another record and link to it
- > 1 record, attribute list is used to indicate what can be found in each record
- tells us file range of each record
- if attribute list gets too large, it can be stored in an extent as well
- all things combined:
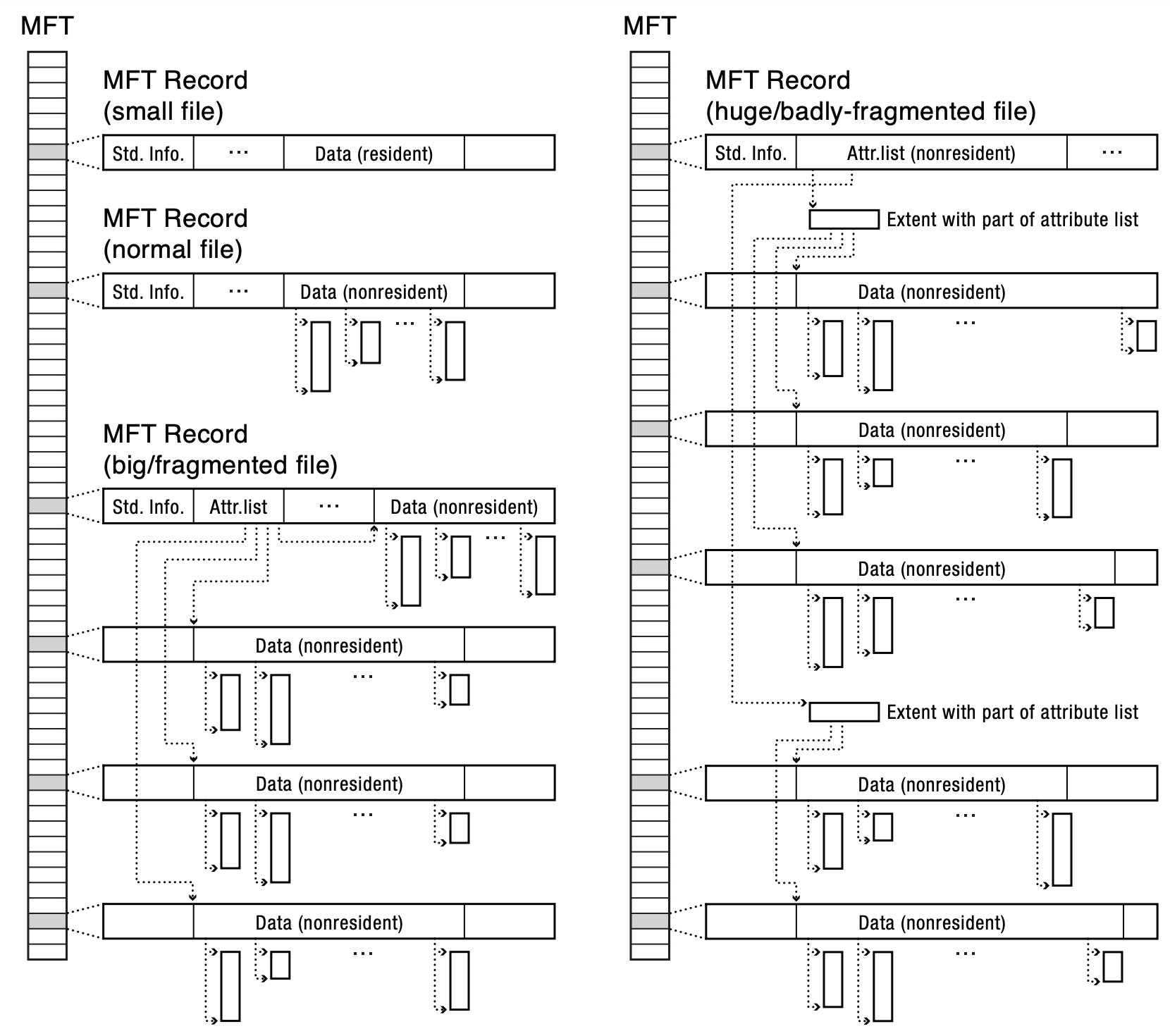
- Locality
- caches a small section of the bitmap for allocation
- neighboring blocks are once written close in time
- reserve space for MFT