The superblock keeps file system-level information, things like how many inodes are on disk, where they're located, and the like. Each inode keeps file meta-data (e.g, who the owner is, what the permissions are, how big it is) and a index that can be used to locate the disk blocks containing the file contents. Each directory entry contains a fixed-length name field and an inode number. (The named file is described by the inode in the entry, and so if you want that files contents you should go to that inode and use its data block index to figure out where on disk it is.)
The two maps (inode and data block) are simply bit strings. There is one bit for each inode (data block). If bit n is 0 it means inode (data block) n is free; otherwise, it's in use.
Here is the disk layout used by cse451fs:
![]()
boot is the boot block, and is unused.
The disk block labeled superblock is actually two things, the file system superblock and the inode map. It contains a struct cse451_super_block, which is defined in file cse451fs.h in the main directory when you untar the skeleton code. Because that structure is much smaller than a full block (which is 1KB), whoever designed this file system decided to stuff the inode map in as whatever bits are left in that block.
data map is one or more blocks that together are the data map - a bit string indicating which blocks from "data blocks" are in use. The number of blocks used depends on the number of data blocks (we need one bit in the data map for each data block), which is itself decided by the mkfs.cse451fs program which is used to initialize a raw disk partition with all the things shown above, set up to represent a file system containing only a root directory ("/") with entries "." and "..".
inode blocks is one or more blocks, each of which contains multiple inodes, which are defined as struct cse451_inode in cse451fs.h. There can at most as many inodes as there are bits in the inode map.
data blocks is the space available for storing the contents of files, including directories.
Not shown is the format of directory files. A directory is just a file (so it has an inode describing which data blocks it is stored in). It consists of two or more directory entries, all of which have identical structure: an unsigned, 16-bit inode number followed by the filename as a string of length at most 30. (So, a directory entry is 32 bytes, which conveniently divides a block (1024 bytes).) Directory entries are described by struct cse451_dir_entry.
You might reasonably expect that the code for the implementation of cse451fs would consist of a lot of disk reads and writes. To handle an open system call, for instance, you might expect to find code that read the inode for the current working directory, used that to find the data blocks for that directory, then searched that directory for the file named in the open call, then read the disk block containing the inode for that file, and so on. This is roughly what is happening, but the implementation is a little more complicated, as described next.
Linux provides a "virtual file system" called vfs. It's not really a file system at all, but rather a layer between concrete file systems (ones that actually store data on disk) and user level programs. System calls that affect files are handled by vfs, which in turn calls a concrete file system (like cse451fs) to deal with the fact that vfs has no idea what the disk layout is for a particular file system.
Here's a picture of the setup, stolen from The Linux Kernel:
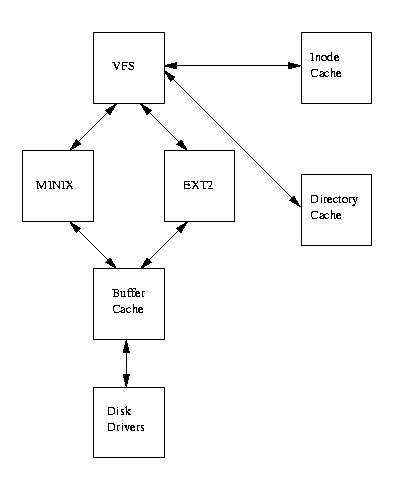
It isn't shown, but above vfs lie the user programs. When they make the file system calls defined by the Linux API (e.g., open, read, write, and close) those calls are first handled by vfs, which then invokes the concrete file system below it to actually figure out where on disk any required data might be. How does vfs know which routine to call in a particular concrete file system? The file system registers routines for a pre-defined set of events by giving vfs a table of function pointers (or, actually, a number of such tables). These events are things like "read super block" or "find directory entry". The concrete file system can register routines to be called for events of this type that it needs to know about (because it needs to either make a decision about a disk location or else simply wants to update some in-memory data structure it is maintaining). It can also register NULL for the events, in which case vfs either handles them itselfs or crashses on a null pointer exception, depending (on whether or not vfs is prepared for the underlying file system to ignore the event).
vfs also defines a set of "file system data structures" - a superblock, inodes, directory entries. These are abstractions that allow vfs to present a single interface up, to the user programs, no matter what specific concrete file system is actually below it. The abstract file system data structures live only in memory. For the most part, filling in particular values is up to the underlying concrete file system, using data from the real (file system specific) data structures on disk. Once that's done, however, vfs can do a lot of things on its own. One major function it provides is in-memory caching. For instance, the inode cache keeps information about recently used inodes, so that they don't have to be repeatedly fetched from disk.You can find most of the definitions for the vfs structures in linux/include/linux/fs.h
Below the concrete file system are the "drivers" that can actually perform disk IO (on "block devices", those that read/write fixed-sized blocks of data at a time). The buffer cache you see there is just that - it caches raw disk blocks, so that they don't need to be moved between memory and disk on each use.
The major structure used by the buffer cache is struct buffer_head, also located in linux/include/linux/fs.h. Despite it's name, it's really a single block of disk data, cached in memory.
These caches take most direct disk IO out of the hands of the concrete file system - you won't find many calls that actually try to do a disk IO. Instead, it's more typical for vfs to ask the underlying file system something like "get me inode 22", for the underlying file system to figure out which block that is, and then to call the buffer cache layer asking for a specific disk block.
So, how is it decided when to do an actual read or write, and when it's safe to through things out of caches? The cached entities contain status fields that let the caching software decide what to do. For instance, a cached block has a dirty bit that can be set, indicating that the block needs to be written back to disk before the cache entry can be discarded. It also contains a reference count - an integer counting how many pointers to it have been cached in in-memory data structures maintained by the concrete file system. The block cannot be discarded until that count is zero.
You can find the implementation of vfs (the .c files) in linux/fs/*.c.
The file system allows concurrent operations, and also has the possibility of blocking (because disk IO must happen sometime). You'll find in the code some artifacts of dealing with race conditions. Some of these are locks, for mutual exclusion. There is also the use of "atomic procedures," ones that perform some simple operation safely in the face of concurrency when called (e..g, atomic_inc). These should all be at least somewhat familiar to you from past assignments.
You'll also find that the code often rechecks some condition it has just checked recently. This is needed because the state of data structures can shift out from under you between checking and using - you check that a block is free, but then you block and when you come back things may have changed.
This code is much more concurrent than the other pieces we have worked on. Problems could definitely arise under heavy load that you see no sign of under light load.