popa patch is available to address problems with
strange x86 calling conventions. It is recommended for all users,
since we will be testing on x86. It can be applied using
patch(3) in the same manner as the antioptimize patch.
The patch file is on coredump/spinlock in
/cse451/projects/popa.patch or
available for download.
The provided tar.gz files have also been updated; the important changes are
in the lib/sthread_switch_i386.h file.
gcc -O2 on PowerPC. It is recommended for all
platforms. It should be applied by coping or downloading the patch file and then
using the patch(1) command
(from within your top-level simplethreads directory):
patch -p0 < antioptimize.patch
Out:
Part 1 and 2 Due:
Part 3 and 4 Due:
For this project, you will be working in groups of 3. Please use the online tool to register your groups.
Tasks:
In the beginning (well, the relative beginning), there was UNIX. UNIX supported multiprogramming; that is, there could be multiple independent processes each running with a single thread of control.
As new applications were developed, programmers increasingly desired multiple threads of control within a single process so they could all access common data. For example, databases might be able to process several queries at the same time, all using the same data. Sometimes, they used multiple processes to get this effect, but it was difficult to share data between processes (which is typically viewed as advantage, since it provides isolation, but here it was a problem).
What they wanted was multithreading support: the ability to run several threads of control within a single address space, all able to access the same memory (because they all have the same mapping function). The programmers realized that they could implement this entirely in the user-level, without modifying the kernel at all, if they were clever.
As you'll discover in the last part of this assignment, there were some problems with this approach, which motivated kernel developers to include thread support in the kernel itself (and motivated researchers to do it better; see Scheduler Activations).
You will be using the simplethreads package for this assignment. It is available on spinlock/coredump in /cse451/projects/simplethreads-1.X.tar.gz or .tar.gz">for download. (Where X is the release number, which may be updated. Use the latest version. Please watch for updates as the project progresses.)
This project, since it does not involve modifying the kernel, does not require VMWare. The simplethreads package has been tested on:
Please do not use attu.
To begin, copy the tar.gz file to your work directory (/cse451/LOGIN) and run
tar -xvzf simplethreads-1.X.tar.gz
to expand it (if you are working on a different machine, see scp(1)).
Simplethreads contains a lot of files, but most are safe to ignore. Pay attention to:
| Dir/File | Contents |
|---|---|
| lib/ | The simplethreads thread library itself. |
| lib/sthread_user.c | Your part 1 and part 2 implementations go here. |
| lib/sthread_ctx.{c,h} | Support for creating new stacks and switching between them. |
| lib/sthread_switch_{powerpc,i386}.h | Assembly functions for saving registers and switching stacks. |
| lib/sthread_queue.h | A simple queue that you may find useful. |
| include/ | Contains sthread.h, the public API to the library (the functions available for apps using the library). |
| test/ | Test programs for the library. |
| web/ | The webserver for part 3. |
Like many UNIX programs, simplethreads uses a configure script to determine parameters of the machine needed for compilation (in fact, you'll find many UNIX packages follow exactly the same build steps as simplethreads). In the simplethreads-1.X directory, run ./configure to generate an appropriately configured Makefile.
Finally, build the package by typing make. You can also build an individual part, such as the library, by running make in a subdirectory. Or, if you just want to compile one file, run make myfile.o (from within the directory containing myfile.c).
Note that, as you make changes, it is only necessary to repeat the last step (make).
One interesting feature of simplethreads is that applications built using it can use either the native, kernel-provided threads or the user-level threads that you'll implement. Because both provide the same interface (once you've completed parts 1 and 2, anyway), the applications don't even know which version is running. The configure script will accept a --with-pthreads argument to select the version in use (the default is user threads). To switch back and forth, re-run configure and then run make clean.
In summary, the steps are:
If you add a new source file, do the following:
test_silly_SOURCES = test-silly.c other sources here
test_silly_LDADD = $(ldadd)
| Part 1: Implement Thread Scheduling |
For part 1, we give you:
It is your job to complete the thread system, implementing:
The routines in sthread_ctx.h do all of the stack manipulation, PC changing, register storing, and nasty stuff like that. Rather than focusing on that, this assignment focuses on managing the thread contexts. Viewed as a layered system, you need to implement the grey box below:
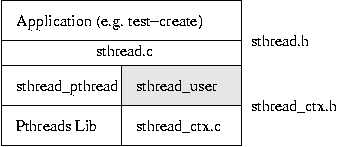
At the top layer, applications will use the sthread package (through the API defined in sthread.h). sthread.c will then call either the routines in sthread_pthread.c or your routines in sthread_user.c (it chooses based on the value passed to sthread_init()). Your sthread_user.c, in turn, builds on the sthread_ctx functions (as described in sthread_ctx.h).
Applications (the top-layer) may not use any routines except those listed in sthread.h. They must not know how the threads are implemented; they simply request threads be created (after initializing the library), and maybe request yields/exits. For example, they have no access to sthread_queue. Nor do they keep lists of running threads around; that is the job of the grey box.
Similarly, your grey box - sthread_user.c - should not need to know how sthread_ctx is implemented. Do not attempt to modify the sthread_ctx_t directly; use the routines declared in sthread_ctx.h.
[New Thread 1024 (LWP 18771)]. These messages refer to
kernel threads.| Part 2: Implement Mutexs and Condition Variables |
For part 2, you'll use the thread system you wrote in part 1, extending it to provide support for mutexs (a.k.a. locks) and condition variables. Skeleton functions are again provided in lib/sthread_user.c. You need to:
The non-preemptive nature of this assignment aids you greatly in your tasks (since it gives you atomic critical sections). However, you should think about what you would need to do if your threads were preemptive; add comments to the routines indicating precisely where the critical sections are and what appropriate protection might be applicable (e.g. how you would use a spinlock or other atomic operation).
| Part 3: Implement a Multithreaded Web Server |
Every web server has the following basic algorithm:
The sioux webserver in the web directory implements the server side of the above algorithm.
For part 3 you will make sioux into a multithreaded web server. It must use a thread pool approach; it should not create a new thread for each request. Instead, incoming requests should be distributed to a pool of waiting threads (this is to eliminate thread creation costs from your experimental data). Make sure your threads are properly and efficiently synchronized. Use the routines you implemented in part 2.
Note that you are implementing an application now. That means the only interface to the thread system that you should use is that described by sthread.h (as distributed in the tar.gz). Do not use functions internal to sthreads directly from sioux.
You should accept a command-line flag indicating how many threads to use.
In testing, you may encounter "Address already in use" errors. TCP connections require a delay before a given port can be reused, so simply waiting a minute or two should be sufficient.
Because we have not used asynchronous IO in sioux, it will be very difficult to obtain good performance using the user-level threads. In some cases, it may be difficult to even get correct behavior at all times (e.g., if no new requests are sent, existing requests may not be serviced at all). We recommend using kernel-level threads for this part.
| Part 4: Analysis and Report |
Your report should include a section on the design of your user-level threads, synchronization primitives, and webserver. Discuss the goals of each, how well your design meets those goals, and the tradeoffs that were made. Justify your design decisions as compared with other possible designs. Goals for some aspects (e.g. synchronization) are discussed in the text; for others, you need to determine what appropriate goals are. Some goals you may wish to consider for all systems code are speed, complexity, and usefulness.
For your analysis, design an experiment to either:
This experiment should be conducted in the standard scientific method. It should explore the performance of the server under a variety of different conditions chosen to confirm or deny various aspects of your hypothesis. You may want to go over your experimental design with a TA.
There are several variables to examine in either option. While you will probably need to vary at least a few parameters to gain a good understanding of the behavior of your system, keep in mind that a good experiment only varies one parameter at a time. You should also make sure to repeat each trial several times, to increase the confidence in your data.
Include a presentation of your experimental design, data, analysis, and conclusions in your report.
Discuss conclusions you have reached from this project. What recommendations do you have for designers of thread systems? Can you recommend user threads or kernel threads? Why? What other features might be useful?
To help you conduct microbenchmarks, we have provided an example using
the Pentium time stamp counter to obtain cycle-accurate timing
information. The clock speed, in MHz, of a Linux machine can be found
by examining the file /proc/cpuinfo. The sample code can be
found on coredump/spinlock in /cse451/projects/timer.tar.gz or here. (Unfortunately, we do not have sample
code for PowerPC timing.)
The WebStone web benchmark tool has been installed on spinlock and coredump as /cse451/projects/tools/bin/webclient. It measures the throughput and latency of a webserver under varying loads. It simulates a number of active clients, all sending requests in parallel (it does this by forking several times). Each client requests a set of files, possibly looping through that set multiple times. When the test is complete, each client outputs the connection delay, response time, bytes transfered, and throughput it observed (depending on the server, the clients may all observe very similar results, or the data may vary widely). The tool takes the following arguments:
All of the above parameters are required. The URLLIST file should contain one relative URL (just the file name) per line followed by a space and then a number (the number is the weight representing how often to request the file relative to other files in the list - most likely, 1 is the value you want).
For example, to test a webserver on almond.cs.washington.edu, with two simulated clients each fetching the index.html file twice, one would run:
/cse451/projects/tools/bin/webclient -w almond.cs.washington.edu -p 12703 -l 2 -n 2 -u ./urls
Where the file urls would contain the following single line:
/index.html 1
| Turnin |
Please turnin one copy of the project per group. It would help us if you select one group member to execute all turnins (only the last submission will be graded).
In your top-level simplethreads directory, run make dist. This will produce a file named simplethreads-1.X.tar.gz. Make a new directory called username where username is your CSE login and move simplethreads-1.X.tar.gz into that directory. Submit this directory using the turnin(1L) program under project name project2a by . Turnin will not work on coredump/spinlock, so you'll need to use attu.
Run tar -tzf simplethreads-1.X.tar.gz and check to make sure all simplethreads files, and any new files you have added, are listed. (For parts 3 and 4, make sure any files from your experiment are included.)
All submitted files should be in text format. Word documents should not be submitted (by turnin or email).
Follow the same instructions as for parts 1 and 2. Turnin a final version of your code including any scripts or other files you used in your experiment by . It should be submitted under the project name project2b.
You should turn in your report on paper in lecture by
![]()