Convolutions for Images¶
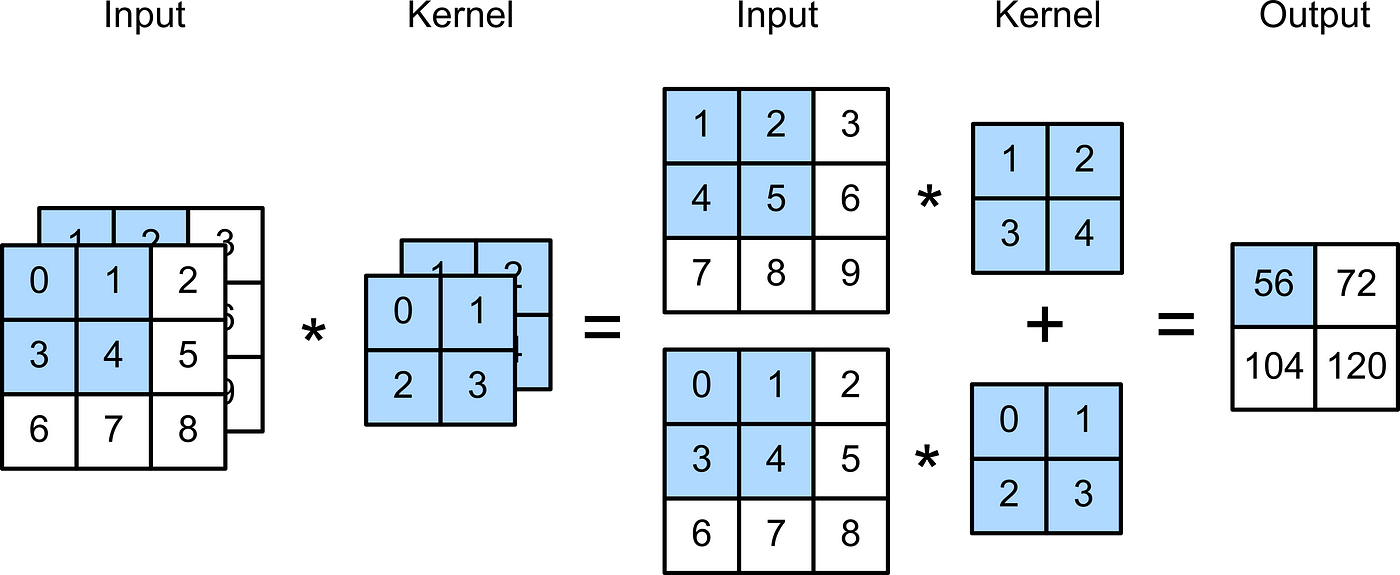
Convolutional layers are actually a misnomer, since the operations they express are more accurately described as cross-correlations. Here, we'll look at what the convolution (cross-correlation) operation looks like for a 2x2 convolutional kernel, shown below.
Here, we show a fixed kernel; however, it's important to remember that when training a neural network, these kernels are learned via SGD (or another optimization method).

Notice how the output is smaller than the input. This means that, over several successive layers of convolution operations, our tensors can shrink to size zero if we don't monitor their size or combat the shrinkage with pooling (see below).
One of the most common applications for convolutional layers and convolutional networks as a whole is when dealing with image data. Typically our data is represented as 3 separate channels (RGB) each of which can be thought of as an array of pixel values. To help us uncover relationships between pixel values and extract various image features, we can use a 3 dimensional kernel to convolve over the various channels. Here is an example of a basic 2x2x2 convolutional kernel acting upon some input data.