|
CSE 415: Introduction to Artificial Intelligence The University of Washington, Seattle, Autumn 2022 Due: Wednesday, November 23, via GradeScope at 11:59 PM. Early Bird Bonus Deadline: Friday, November 18, via GradeScope at 11:59 PM. (updated from Wed. Nov. 16) |
 IntroductionThe perceptron is a basic computational model for a neuron or simple neural network that served as a starting point for the development of techniques such as deep learning. By studying the perceptron, we can gain familiarity with many of the basic concepts of neural networks and ML as well as better understand how such techniques complement those of state-space approaches in AI. 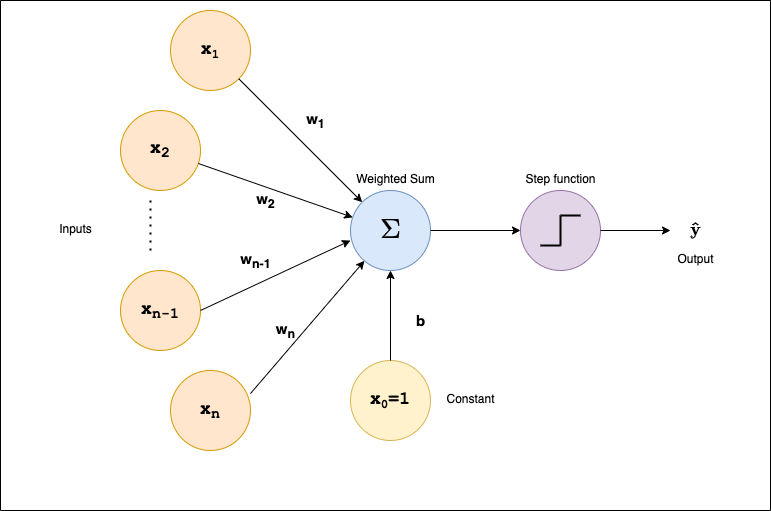 This assignment is about how perceptrons are trained, and it involves training and testing two kinds of perceptrons to perform classification on multi-dimensional data.
We will be primarily using a dataset is derived from the classical Fisher Iris dataset, however we will also be using other datasets. |
Part A: Binary ClassificationBegin by downloading the A6 starter files. In Part A you'll be using only the following subset of these files:A6-Part-A-Report.docx plot_test.py binary_perceptron.py plot_bp.py remapper.py run_2_class_2_feature_iris_data.py iris-lengths-only-2-class-training.csv iris-lengths-only-2-class-testing.csv ring-data.csvNext, run the plot_test.py, and then install the matplotlib module if you
don't have it already. You can typically install it by typing the following on a command line:
pip3 install matplotlibHowever, depending on how your Python is already set up, that might not work and you can try substituting "pip" for the "pip3". However, on some systems, "pip" will only install it for Python 2.7. If you have trouble installing matplotlib, the staff will try to facilitate your setup through posts on ED or in office hours. The file A6-Part-A-Report.docx is a template for your Part A report. It contains ten questions that you should answer. Binary Perceptron
The |
Part B: Multi-Class ClassificationIn this part, you'll use the remaining files from the starter files collection:A6-Part-B-Report.docx ternary_perceptron.py run_3_class_4_feature_iris_data.py plot_tp.py iris-all-features-3-class-training.csv iris-all-features-3-class-testing.csv synthetic_data.csv Ternary PerceptronIn this section we will consider the problem of multi-class classification for datasets with 3 classes. The first dataset we use is the
all-features Iris Dataset with 3 classes. In order to do multi-class classification
of the dataset, you'll first have to implement the ternary perceptron in the file Apart from the Iris dataset, we will also use the ternary perceptron to train on a synthetic dataset One-Vs-All ClassificationInstead of using a ternary classifier to classify the multi-class data, an alternative way to do so would be using the binary classifier itself.In the scenario of One-Vs-All classification, we designate one of the classes as a positive class +1, and the points in all the other classes as belonging to a negative class -1. For example, if we treat all the data points of class 0 as the positive class (+1), then all the points in classes 1 and 2 will be treated as the negative class (-1) Hence, now that we have reduced the data to having only 2 classes, we can train a binary perceptron to separate them. Similarly, you can repeat this process by designating in turn each of the classes as the positive class, with all the remaining classes as the negative class. If there are n classes, then we will end up with n classifiers.Hence, for a new data point, each trained binary classifier will predict whether the data point either belongs to the class, or not. 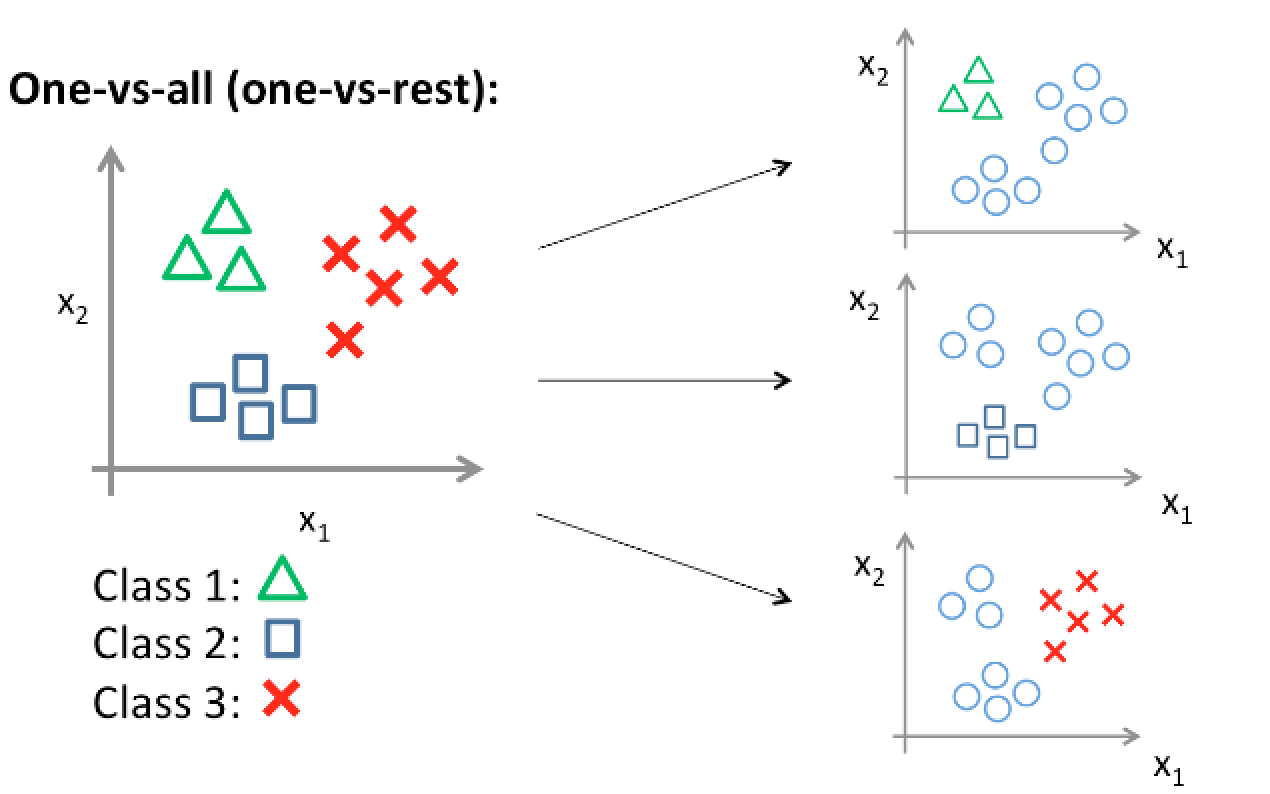 run_synth_data_1_vs_all.py, implement a class called PlotMultiBPOneVsAll that makes use of the functionalities
from plot_bp for binary classification, but adapts it to One-Vs-All classification. Given as input a particular index of the class as positive (implement it as an instance variable POSITIVE),
it should be able to do a One-Vs-All classification and plot a resulting class boundary separating that positive class from the remaining classes. For example, if we consider class 0 as the positive class (+1) i.e. when POSITIVE=0, the plot should look like this: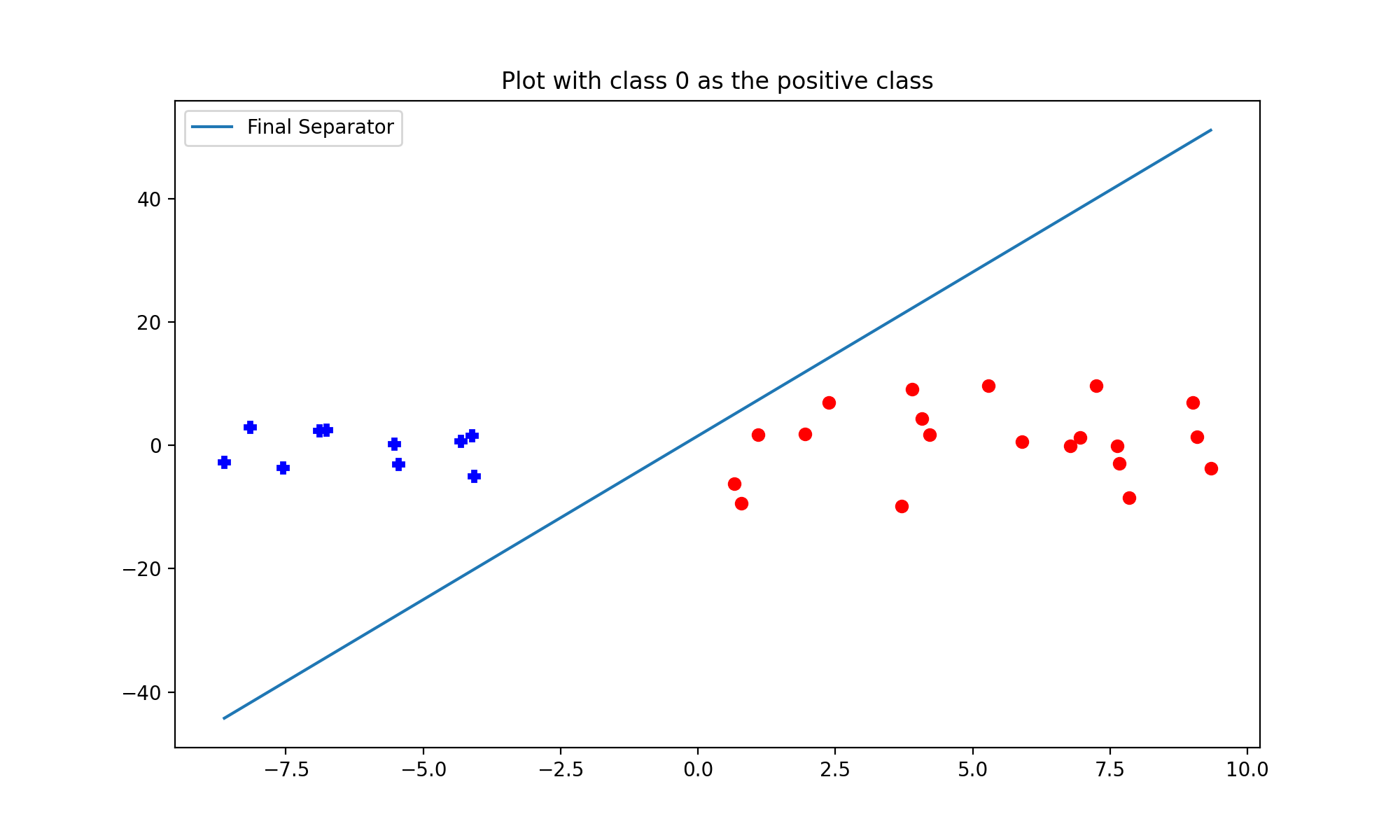 One-Vs-One ClassificationAnother way to do multi-class classification is via the One-Vs-One approach, where we run a separate classifier for every pair of classes. Each classifier only considers the data points of 2 of the classes, and then it learns to differentiate between the two classes, i.e. classifying the data as one of the two classes. We can repeat the process for every pair of classes, so if there aren classes, then we get nC2 such classifiers. So, each classifier predicts one label out of 2 possibilities. Finally, while testing, if we want to know the class of a new data point, we can compile the class predicted by each classifier as votes, and then by majority vote predict the actual class.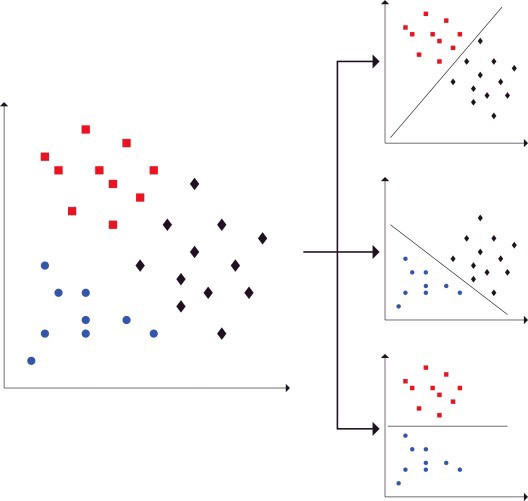 run_synth_data_1_vs_1.py, implement a class called PlotMultiBPOneVsOne that makes use of the functionalities
from plot_bp such that given the indices of a pair of classes it should be able to do a binary classification and plot a resulting class boundary. Make use of an instance variable CLASSES such that if self.CLASSES = (0,1), the class should plot the appropriate boundary separating classes 0 and 1, where it treats 0 as the positive class (+1), and 1 as the negative class (-1). In such a scenario, the plot should look like this: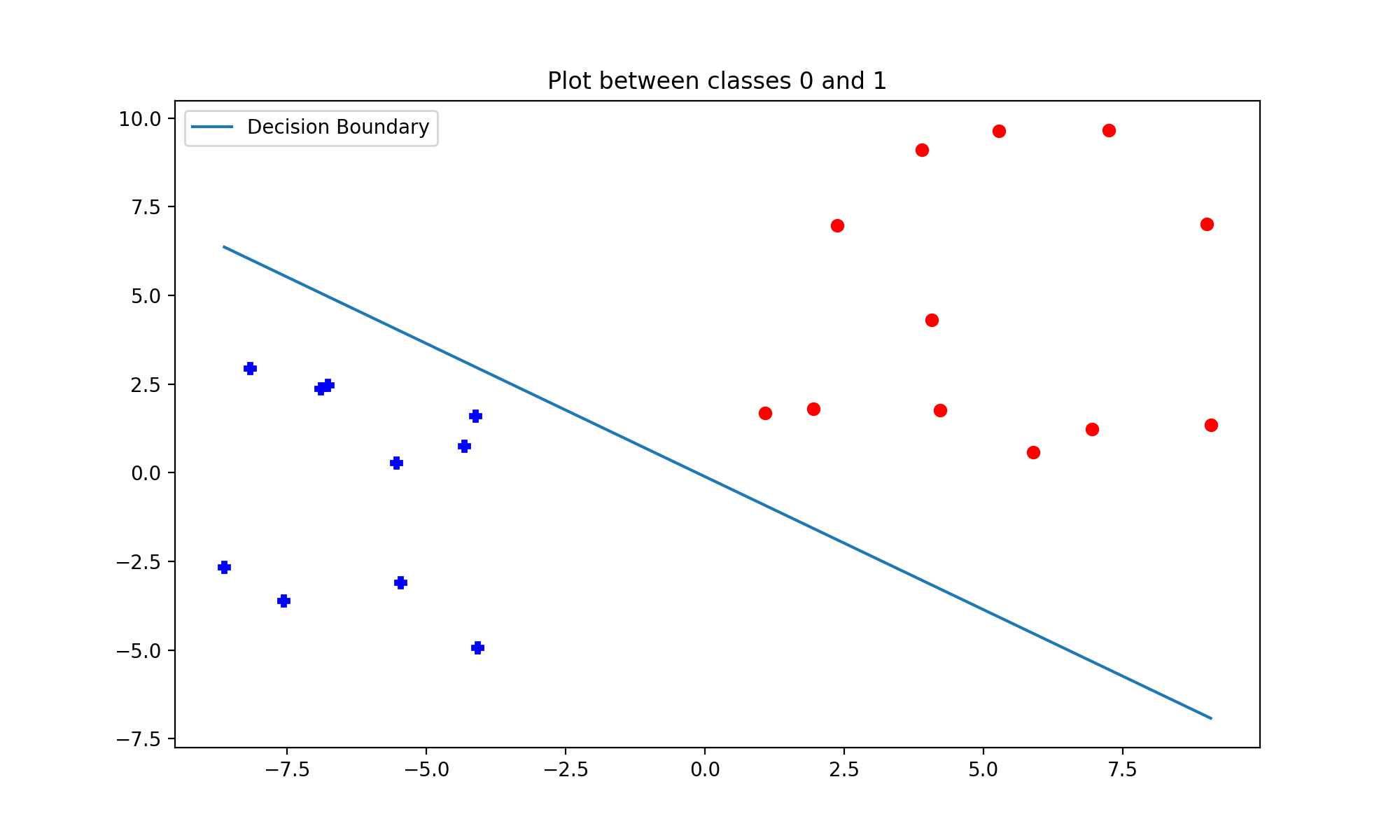 Use all these scripts in answering Part B of the report. |
Turn-In InstructionsTurn-ins for Part B at Gradescope are : A6-Part-B-Report.pdf (the report file as a .pdf) ternary_perceptron.py run_synth_data_ternary.py run_synth_data_1_vs_1.py run_synth_data_1_vs_all.py |
AutograderSome portions of the code you submit (mainly the perceptron) will be graded by an autograder. Please ensure that all the code you write is present in the specified format so that the autograder can evaluate your code correctly.As for the remaining code, you will have a bit more leeway to design your scripts as long as they meet the requirements in the spec. Note that some tests may depend on the prior tests to be correct if there are dependencies between the functions. Also, please note that the autograder tests will not have any outputs as the autograder is built in a way that it cannot securely reveal exactly what a student's error is. So you will need to develop your own tests to figure out what the problem is. However, from the names of the tests, you should be able to easily identify the problematic method. The code may be evaluated for neatness and formatting, and having a clear code will be helpful if partial credit is to be provided. |
Updates and Corrections
If needed, updates and corrections will be posted here, and/or in ED.
|