
| CSE 378: Machine Organization & Assembly LanguageWinter 1999[home] |
|
| CSE 378: Machine Organization & Assembly LanguageWinter 1999[home] |
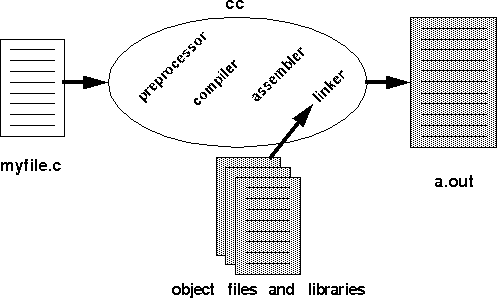
Figure 1: The internals of cc.
The compiler effectively translates preprocessed C code into assembly code, performing various optimizations along the way as well as register allocation. Since a compiler generates assembly code specific to a particular architecture, you cannot use the assembly output of cc from an Intel Pentium machine on one of the instructional machines (Digital Alpha machines). Compilers are very interesting which is one of the reasons why the department offers an entire course on compilers (CSE 401). To see the assembly code produced by the compiler, use cc -S.
The assembly code generated by the compilation step is then passed to the assembler which translates it into machine code; the resulting file is called an object file. On the instructional machines, both cc and gcc use the native assembler as that is provided by UNIX. You could write an assembly language program and pass it directly to as and even to cc (this is what we do in project 2 with sys.s). An object file is a binary representation of your program. The assembler gives a memory location to each variable and instruction; we will see later that these memory locations are actually represented symbolically or via offsets. It also make a lists of all the unresolved references that presumably will be defined in other object file or libraries, e.g. printf. A typical object file contains the program text (instructions) and data (constants and strings), information about instructions and data that depend on absolute addresses, a symbol table of unresolved references, and possibly some debugging information. The UNIX command nm allows you to look at the symbols (both defined and unresolved) in an object file.
Since an object file will be linked with other object files and libraries to produce a program, the assembler cannot assign absolute memory locations to all the instructions and data in a file. Rather, it writes some notes in the object file about how it assumed things were layed out. It is the job of the linker to use these notes to assign absolute memory locations to everything and resolve any unresolved references. Again, both cc and gcc on the instructional machines use the native linker, ld. Some compilers chose to have their own linkers, so that optimizations can be performed at link time; one such optimization is that of aligning procedures on page boundaries. The linker produces a binary executable that can be run from the command interface.
Notice that you could invoke each of the above steps by hand. Since it is an annoyance to call each part separately as well as pass the correct flags and files, cc does this for you. For example, you could run the entire process by hand by invoking /lib/cpp and then cc -S and then /bin/as and finally ld. If you think this is easy, try compiling a simple program in this way.
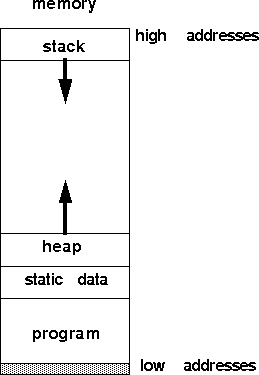
Figure 2: Memory layout.
A typical calling convention involves action on the part of the caller and the callee. The caller places the arguments to the callee in some agreed upon place; this place is usually a few registers and the extras are passed on the stack (the stack pointer may need to be updated). Then the caller saves the value of any registers it will need after the call and jumps to the callee's first instruction. The callee then allocates memory for its stack frame and saves any registers who's values are guaranteed to be unaltered through a procedure call, e.g. return address. When the callee is ready to return, it places the return value, if any, in a special register and restores the callee-saved registers. It then pops the stack frame and jumps to the return address.