Homework: Debugging C
Due: Monday, October 28, 2024, at 11:59pm
Jump To:
Goals
Synopsis
Set-Up
Tech Requirements
Code Quality
Assessment
Turn-in instructions
Assignment Goal
In this assignment you will practice your debugging skills using gdb
and valgrind. Additionally, you will gain more experience working
with C, using multiple module files, and some common Linux tools.
Synopsis
This assignment asks you to exercise debugging skills. In particular, you will need to finish the implementation of a Dictionary module that can perform look-up operations, and a driver program that uses the module to generate English statistics about a given English text.
For this homework, we will provide you with code that already has most of the desired functionality, but is full of nasty memory errors. Your job is to understand how memory is managed and used in the provided code, identify those errors, and come up with a solution to those errors.
This project should be done independently. If you work with a classmate, make sure you are each editing and working on your own set of files. You should not copy and paste code.
Set-Up
Before you get started, ensure that your set-up is up-to-date and appropriate.
- You should do this assignment using
cancun, includinggcc - You should have already set up your local copy of your personal git repository, and added the upstream repository cse374-materials. If you are having trouble with your repositories, or have not yet completed HW3, please return to HW3 and follow directions for this set-up.
- Ensure that your repository is up-to-date and committed. (You can use
git statusto determine if there are outstanding changes, andgit addandgit commitif you are unsure.) - Use
git pull upstream mainto pull the newest commit from the upstream repository. This will give you access to thehw4folder containing the materials for this assignment. (upstreamspecifies that you want to pull from the upstream repository, andmainspecifies the branch. You may see a text editor open to allow you to edit the merge message. This will likely be Vim, so you can edit it and then save, or just accept the current text and exit using:q!.)
You will do this assignment in your new hw4 folder.
You should get into the habit of committing and pushing code frequently.
Technical Requirements
This homework implements a program that has the basic functionality of checking spelling of English text and outputting relevant statistics on the number of words, paragraphs, typos, etc.. This program is case insensitive, so it will recognize “Hello” in the input text as “hello” in the dictionary.
The flow of the program, in general, goes like this:
- Build a dictionary from a certain file that contains all the words we want in the dictionary.
- The input text is read and examined word by word, updating variables holding statistics and generating output about specific mistyped words along the way.
- Write the human-readable statistics to the output.
The provided code already has most of the functionality, but is full of nasty memory errors. And your job is to understand how memory is managed and used in the provided code, identify those errors, and come up with a solution to those errors.
Goal
In the end, the program needs to satisfy the following requirements:
- The code needs to compile without any warning by running
make. - There should be no memory leaks.
- Your program’s behaviors need to match the behaviors of the
solution_binarygiven to you in the starter code. - There should be no style errors reported by
cpplint.py
Starter Code
Your hw4 folder contains the following files:
SpellChecker.h, contains the declaration of functions in the Dictionary module.SpellChecker.c, contains the implementation of functions in SpellChecker.h.Count_typos.c, the driver program.Utils.h, contains the declaration of utility functions.Utils.c, the implementation of utility functions.
The only files that you’ll need to modify and submit are:
SpellChecker.ccount_typos.c
Although there are only two files that contain the buggy code, you’ll still want to look into the header files to see what each function is supposed to do, and to decide how you may modify the code while satisfying the spec. In C programming header files specify the function signatures and provide information about the interface to their corresponding modules.
In the SpellChecker.h, there is a line typedef char** Dictionary;.
We will talk more about typedef this week, but note that the Dictionary
is of type char**.
Notes about Data Types
This homework involves usage of some types that we’d like to address before you look at the actual code:
size_t: The typesize_tis conventionally used in C standard library functions to store a number big enough to fit the size of any object, as computed by callingsizeofon a variable or type name. You can think of the name as “size type.” On the cancun system (64-bit) this will be a 64-bit unsigned integer.char*,char**, and binary search: As we’re all well aware, the typechar*is a pointer to a null-terminated array of char’s. The naive implementation of our dictionary is simply achar**: pointing to an array ofchar*‘s, each points to a string containing a single word. Ourcheck_spellingoperation is then a grass-root binary search on the array to see if a word exists. As such, all operations on our dictionary requires the user to provide both the dictionary itself and the size of the dictionary; because we wouldn’t know how manychar*‘s the dictionary has or what the bounds of our binary search will be otherwise.int,char(read if you’re interested in understanding Utils.c): Recall thatintis a 32-bit/4-byte signed integer.charmay be considered a specialized type for character, but in reality it is the same asintexcept that it’s shorter with only 8 bits. In fact, they’re completely interchangeable if the value doesn’t go past the bounds of an 8-bit space.
Suppose that we have:int i = 48; char c = '0'; // the ascii value of 0 is decimal 48
The following statements will both print out “48”:printf("%d\n", i); // %d is the placeholder for integer values to be interpreted as decimal numbers printf("%d\n", c); //And the following will both print out “0”:printf("%c\n", i); // %c is the placeholder for ascii characters printf("%c\n", c);The following two statements are identical:int i = '0'; int i = 48;
As are the following:char c = '0'; char c = 48;
And, ultimately, you can even do this:char c = 48, d = 5; c = c + d; // c is now decimal 53, which is the ascii value of '5'
With all of that said, it should be clear thatintandcharare identical in terms of binary representation and it’s up to the programmer how a specific instance of each is interpreted. InUtils.c, we chose to useintto store the current character as we step down along theFILE*stream; this is because we would like to be able to look at the current character and decide if it’sEOF; it just so happens thatEOFis of type int. (Alternatively, we can usefeof()to detectEOFas well).- Debugging is best done iteratively. It is worth fixing compiler warnings first. You will also want to re-test after each fix, since that may affect the way subsequent errors show up.
valgrindis your absolute best friend for this assignment; however, the starter code as it is, makes many and aggressive memory errors that it can causevalgrindto freeze/crash. This means that sometimes you’ll have toctrl-cto terminate it and make use of whatever information that is printed on the screen.valgrindoptions, such as--leak-check=full,--show-leak-kinds=all,--track-origins=yes, are all very helpful but they do slow down the execution by a certain amount. Consider using them progressively.- If you have a hard time locating the bug with the information given by
valgrind, consider stepping through the program to the segment that causes the error usinggdb, and pay extra attention whenever you see amallocoperation or a write to heap memory.
Technical Requirements
Getting Started
To start this homework, simply cd to the starter code folder and run the command
make. And you’ll notice many compiler errors that come up.
To address this, you’ll need to add certain #include statements
to the appropriate places. To find out what should be included in which file,
you may refer to man pages, online documentation and the error message from gcc
for headers in C standard library. For others, consider reading through the provided code,
or at least the comments of them, to identify how each of the code files are connected.
It should be a relatively simple process to get the code to compile.
Note:The make command is a build automation tool commonly used in
software development. It reads a file called Makefile that specifies a set of
rules and dependencies, allowing developers to easily compile, test, and organize their
code projects. We will learn more about this soon, but for now you may just use it.
Runtime errors: Most of the work will happen here
The provided code is designed to be infested with all kinds of memory errors that programmers can easily make due to negligence. And your task will be to identify and get rid of them; the major, obvious places where you have to make an addition are marked with // TODO but there are many more hidden ones that you’ll have to identify with gdb or valgrind.
To clarify, you should remove the TODO comments once you’re done with them.
To approach this part of the homework, we have a few tips that we recommend:
Style errors
It is recommended that you look at the style errors after you’re done with all the other ones; because fixing style won’t involve any changes to the structure or the behaviors of the program. We didn’t deliberately include any style errors for you to fix, so this shouldn’t be a concern at all if you practice good coding habits.
Please use ./cpplint.py --clint *.c to review your code. If this fails, you must call python3 explicitely: python3 ./cpplint.py --clint *.c.
Code Quality Requirements
You submission for this assignment will not be graded for style because you only need to modify a few places in staff created code. However, you should always adhere to common guidelines for code neatness and readability. In particular, it will be helpful to add short comments on sections of code that you modify. This will help identify your thought process and enforce good commenting standards.Assessment
This assignment is worth 50 points. There will be an autograder, and no manual assessment. You are able to resubmit the assignment as many times as you wish.
Warning: The autograde evaluates your submission, but does not provide feedback designed to debug the assignment. Before you submit make sure you can compile your code using make on Cancun. This should result in zero warnings or errors. Use valgrind to ensure that there are no memory errors. Your code should match the behavior of solution_binary provided with the starter code.
Turning In
You will submit this homework to the Gradescope HW4: Debugging assignment, via Gitlab.
You will first update your Gitlab repository. Use git add and git commit
to ensure that your updated SpellChecker.c and count_typos.c and committed
to your repository. These should be located in the hw4 folder, located at the top
level of your repository. User git push to bring the origin/remote repository up-to-date.
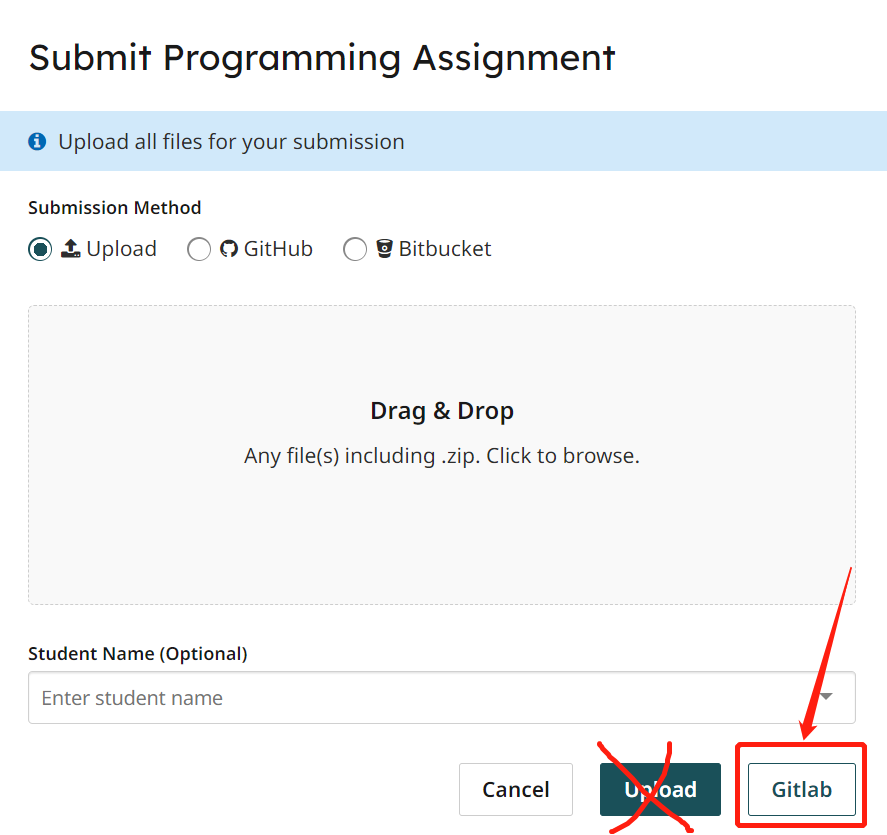
Once you locate the Gitlab assignment you will tap the "GitLab" button on the bottom:

Once you submit your code the autograder may take some time to run. You may resubmit for a higher grade, but your should always do as much testing as possible on your own platform before resubmitting.