PROJECT: Homework 5
Due: Friday, May 12, 2023, at 11:59pm
You may not drop this project assignment.
Assignment goals
In this assignment, you will develop a more complex program using dynamic data structures. In doing so you will:
- Gain experience developing a larger system one part at a time, testing as you go.
- Learn about the trie data structure, a version of a search tree.
- Gain experience working with trees, structs, and dynamically allocated data.
- Gain more experience reading and processing text files in C.
- Practice writing simple Makefiles.
This is a significantly larger task than the previous programming assignment! Start early.
Synopsis
In this assignment, you will build programs to implement T9 predictive text,
a text input mode developed originally for cell phones and
still used for numeric keypads. Each number
from 2-9 on the keypad represents three or four letters, the number 0 represents
a space, and 1 represents a set of symbols such as { , . ! ? } etc. The numbers
from 2-9 represent letters as follows:
2 => ABC
3 => DEF
4 => GHI
5 => JKL
6 => MNO
7 => PQRS
8 => TUV
9 => WXYZ
Since multiple letters map to a single number, many key sequences represent multiple words. For example, the input 2665 represents "book" and "cool", among other possibilities.
2 6 6 5 2 6 6 5
a B c m n O m n O j K l OR a b C m n O m n O j k L
| | | | | | | |
----------------------- -----------------------
| |
book cool
To translate from number sequences to words, we will use a data structure known as a trie. A trie is a multiway branching structure (tree) that stores the prefixes of sequences. As we travel down a path in the trie, we reach word sequences spelled out by the numbers along that path. Classic trie data structures have edges labeled with letters to store prefixes of strings. But for this application, we use a compressed trie that has only 10 possible branches at each node instead of 26, since the digits 0-9 represent the 26 letters, space and symbols. Because of this, an extra layer of complexity is needed to figure out the string represented by a path.
(Actually, for our application, each node only needs 8 possible children numbered 2-9, since digits 0 and 1 don't encode letters. But writing the code might be easier if nodes have 10 children numbered 0-9, since then subtree number n corresponds to digit n. Feel free to use either representation for the trie depending on which seems simpler to implement.)
For more information on the trie data structure, here is a link to the Wikipedia article.
Technical Requirements
Implement a program t9. You must use C for this assignment.
The command
$ ./t9 FILE
should read in a dictionary file (FILE) that contains a list
of words. Translate each word in the dictionary into its numeric key sequence,
then add the
key sequence to your trie, with the word at the end of the path corresponding
to the digits. If a word with the same numeric sequence already exists in
the trie, add the new word to the trie as a link to a new node with an edge
labeled '#' instead of one of the digits 2-9. (The words linked from a
node by the '#' edges essentially form a "linked list" of words that have the
same numeric code, but we use additional tree nodes to link the words together
instead of defining a separate kind of linked-list node just for this situation.)
For example, if the program reads the set of words "jello","rocks",
and "socks" from
the dictionary and adds it to an empty trie, the resulting trie should look
like this:
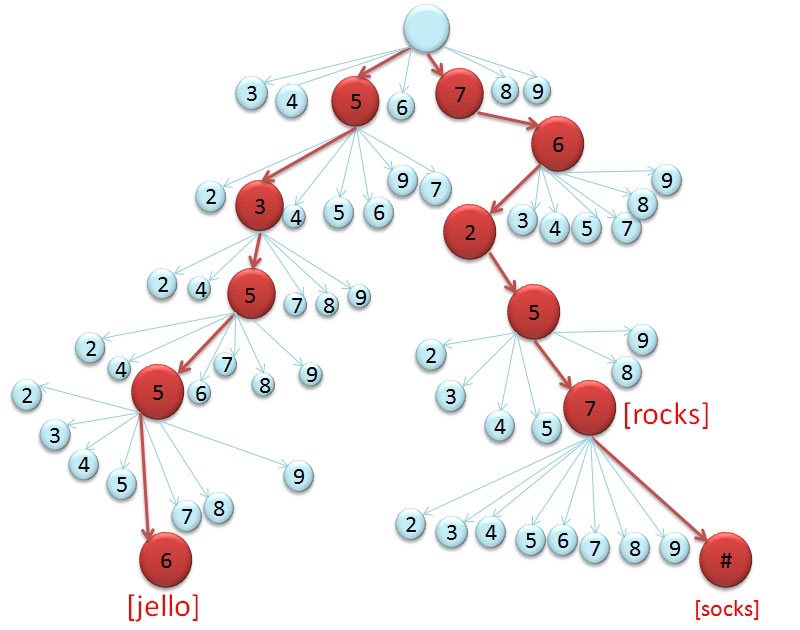
Once your program has read the dictionary and built the trie containing the words in it, it should start an interactive session. The user should be able to type numbers and the program should print out the word corresponding to the sequence of numbers entered. Your program should use the numbers typed by the user to traverse the trie that has already been created, retrieve the word, and print it to the screen. If the user then enters '#', the program should print the next word in the trie that has the same numeric value, and so forth. The user can also type a number followed by one or more '#' characters - this should print the same word that would be found by typing the number and individual '#' characters on separate input lines.
As an example, if we run the program using the above trie, an interactive session might look like this:
Enter "exit" to quit. Enter Key Sequence (or "#" for next word): > 76257 'rocks' Enter Key Sequence (or "#" for next word): > # 'socks' Enter Key Sequence (or "#" for next word): > 53556 'jello' Enter Key Sequence (or "#" for next word): > # There are no more T9onyms Enter Key Sequence (or "#" for next word): > 76257# 'socks' Enter Key Sequence (or "#" for next word): > 2273 'acre' Enter Key Sequence (or "#" for next word): > # 'bard' Enter Key Sequence (or "#" for next word): > 76257## There are no more T9onyms Enter Key Sequence (or "#" for next word): > 2273#### 'base' Enter Key Sequence (or "#" for next word): > 4423 Not found in current dictionary. Enter Key Sequence (or "#" for next word): > exit
The interactive session should terminate either when the user enters the word "exit" or when the end-of-file is reached on the interactive input (indicated by typing control-D on the keyboard on a separate line by itself).
Note: The user of your program may not behave the way you expect - make sure your program can handle the case where "#" is entered but there are no more T9onyms, as well as cases where the user enters characters that aren't [2-9,#], or patterns with no word associated with them.
We provide you with two text files,
smallDictionary.txt and
dictionary.txt.
Each of these text files contains a list of words to be used in constructing
a trie - the small one primarily for testing, and the large one for the final
program. You may wish to create a third test file with only one or two words.
Translate each word in the file into its associated T9 key sequence, and add the word to the trie. In the case of multiple words having the same key sequence k, let the first word encountered in the text file be represented by the key sequence k, the next encountered represented by k#, the next k##, etc. For example, 2273 can represent acre, bard, bare, base, cape, card, care, or case. To disambiguate, acre would be represented by 2273, bard by 2273#, bare by 2273##, and so forth.
For the interactive session, use the user-entered pattern to traverse the trie and return the correct word.
Your trie data structure should contain nodes to represent the tree, and strings (char arrays) containing copies of the words read from the dictionary file, linked to appropriate nodes in the trie.
Besides the general specification given above, your program should meet the following requirements to receive full credit.
- You should create a
Makefileand usemaketo compile your program. YourMakefileshould only recompile the necessary part(s) of the program after changes are made. YourMakefileshould include a targetcleanto remove previously generated files. You may also want to include a targettestfor your own use during development. - Use
mallocto dynamically allocate the nodes, strings, and any other data that make up your trie. Make sure you free all the memory at the end of the run. We will usevalgrindto evaluate how well your code manages memory. - If you need to create a copy of a string or other variable-size
data, you should dynamically allocate an appropriate amount of storage
using
mallocand release the storage withfreewhen you are done with it. The amount allocated should be based on the actual size needed, not some arbitrary size that is assumed to be "large enough". - One exception to this is that you may assume that no word exceed 50 characters in length. While you should not create trie nodes with strings of the default length of 50, you may use this value while reading from the input file.
- Use standard C library functions where possible; do not reimplement operations available in the standard libraries.
- Use buffer safe varitions of functions, such as
strncpyinstead ofstrcpy - You must check the return status (result code) of every library
function you call to be sure that no errors occurred. In particular,
mallocwill returnNULLif it is unable to allocate storage. Although this is extremely unlikely to happen, a robust program must check for the possibility and react appropriately if it does. - If an error occurs when opening or reading a file, or due to a failed
function call, the program should write
an appropriate error message to
stderrand terminate if there is no further work to be done. - Before the program terminates, all dynamically allocated data must
be properly freed (i.e.,
freeeverything acquired withmalloc). This should be done explicitly without relying on the operating system to clean up after the program finishes. - Your code must compile and run without errors or warnings when
compiled with
gcc -Wallon cancun or the CSE Linux VM. Your program should build without errors whenmakeis used to run yourMakefile. You are, of course, free to use other systems for development, and you should be fine as long as you have a relatively recent version of gcc. But we will test the code on the CSE Linux machines. - Your program should terminate cleanly with no memory leaks or other
memory errors reported when it is run using
valgrind. (Warning:valgrindslows down execution considerably. It will take several minutes to load the full dictionary.txt file and then free the resulting tree undervalgrind. We suggest you use smaller input files during development to test for memory problems withvalgrind.) If memory leaks are detected,valgrind's--leak-check=fulloption will be useful to generate more extensive messages with information about the memory leaks.
Code Quality Requirements
As with any program you write, your code should be readable and understandable to anyone who knows C. In particular, for full credit your code must observe the following requirements.
- Your program should be divided into reasonable modules that interact.
We have provided starter code in
trienode.h,trie.c, andtnine.c, which give some guidance to segmenting the code. Within a module/file your code should be divided into functions, each of which has a single well-defined purpose. - The header (
.h) file for the trie (and any other header files) should only declare items that are shared between client programs that use the header and the file(s) that implement it. Don't include in the header file implementation details that should be hidden. The header provided for you may not need to be edited, and already uses the standard#ifndefpreprocessor trick so your header files work properly if included more than once in a source file, either directly or indirectly. You will want to look closely at what is included in the header file. - Be sure to include appropriate function prototypes near the beginning of each source file for functions defined in that file whose declarations are not included in a header file.
- Comment sensibly, but not excessively. You should not use comments
to repeat the obvious or explain how the C language works - assume that
the reader knows C at least as well as you do. Your code should,
however, include the following minimum comments:
- Every function must include a heading comment that explains what the function does (not how it does it), including the significance of all parameters. It must not be necessary to read the function code to determine how to call it or what happens when it is called. (But these comments do not need to be nearly as verbose as, for example JavaDoc comments.) If your function assumes something about an argument make sure to be clear about that in the comments.
- Every significant variable must include a comment that is sufficient to understand the information in the variable and how it is stored. It must not be necessary to read code that initializes or uses a variable to understand this.
- Every source file should begin with a comment identifying the file, author, and purpose (i.e., the assignment or project).
- Use appropriate names for variables and functions
- No global variables. Use parameters (particularly pointers) appropriately.
- No unnecessary computation or excessive use of
mallocorfree- these are expensive. Don't make unnecessary copies of large data structures; use pointers. (Copies of ints, pointers, and similar things are cheap; copies of large arrays and structs are expensive.)
As with the previous assignment, you should use the cpplint.py style checker to review your code. While this checker may flag a few things that you wish to leave as-is, most of the things it catches, including whitespace errors in the code, should be fixed. We will run this style checker on your code to check for any issues that should have been fixed. Please use the class discussion board if you have questions about any of clint's warnings and whether they can be ignored.
Implementation Hints
- You can obtain the supporting files by pulling from the
cse374-materialsrepository from gitlab. If you have not yet cloned the repository you may use the commandgit@gitlab.cs.washington.edu:mh75/cse374-materials.git. If you already completed that step go to the directory and usegit pullto get the most up-to-date files. - In this file three source code files are provided -
trienode.h,trie.c, andtnine.c. These files are designed to get you started. You should edit them to complete your program, and submit your completed files for the assignment. The header file may not need to be edited, but the two .c files will definitely need additions. You may use the enclosed comments for some additional guidance. - There are a lot of things to get right here; the job may seem overwhelming if you try to do it all at once. But if you break it into small tasks, each one of which can be done individually by itself, it should be quite manageable. For instance, design the structure of the trie and the structs (and struct fields) you need. Figure out how to add a single word to the trie before you implement the logic to process all of the words in the dictionary. Figure out how to add a few words that have different numeric codes before you handle words that have the same codes. Implement the code to traverse the trie to translate an input key sequence into the corresponding word once you've built the trie, not before.
- Before you start typing code into the computer, spend some time
sketching out data structures and code (particularly trie node
structs) on paper or on a whiteboard. Be sure you understand what you are trying to do before you start typing. - Every time you add something new to your code (see hint #1), test
it. Right Now! It is much easier to find and fix
problems if you can isolate the potential bug to a small section of code
you just added or changed.
gdbandprintfare your friends here to examine values while debugging. - You will probably find it very useful to include code that can print the contents of the trie in some understandable format. This is not required, but how can you be sure your code is correct if you can't look at the trie that is built for a small set of input data?
- Start with a small data file and figure out in advance what the resulting trie should look like. Then verify that the program does, in fact, create that trie.
gdbis your friend.- To build the trie, you need some way to translate characters
(primarily letters) from words in the dictionary file to the
corresponding keypad digits. It is probably a great idea to include in
your code a function that takes a character as an argument and returns
the corresponding digit. This can be implemented with a series of
if-elseif-elsestatements, but another way to do it is to have an array with one entry for each possible character. In the entry for each character, store the corresponding digit code. Then you can look up the code for a character without a complicated nest ofifstatements. (Recall that in C, as in Java and other languages, a character can be used as a small integer. That is particularly helpful for exactly this kind of application, where we might want to use a character value as an index into a table of data.) - Be sure to check for errors like trying to open a nonexistent file to see if your error handling is working properly.
- Once you're done, read the instructions again to see if you overlooked anything.
- Reread the previous hint and obey.
Test Sequences:
The sequences below can be used to validate your trie against the supplied
dictionary.txt file.
- 22737: acres, bards, barer, bares, barfs, baser, bases, caper, capes, cards, carer, cares, cases
- 46637: goner, goods, goofs, homer, homes, honer, hones, hoods, hoofs, inner
- 2273: acre, bard, bare, barf, base, cape, card, care, case
- 729: paw, pax, pay, raw, rax, ray, saw, sax, say
- 76737: popes, pores, poser, poses, roper, ropes, roses, sords, sorer, sores
What to turn in
You will need to submit your Makefile and all source code required to make this project. We will be expecting new copies of the three files provided as starter code in addition to your Makefile.
Submit your files to the Gradescope assignment, which will be linked through Canvas. For this assignment we ask that you submit through Gitlab. To do this you will follow these steps:
- Commit your HW5 code to your Gitlab repository. Push this to the origin branch.
- The files you will submit for HW5 should be in a folder named HW5, at the top level of your repository.
- If you have other material in your repository, you will make a branch named hw5submit. Update this branch so that it contains ONLY the files you need to submit. Make sure to push this branch to the origin/remote branch. (If you do not have other materials in your repository, you may choose to skip this step.)
- Atlassian has a good branching tutorial
- Pushing this branch to the origin the first time will use a command similar to
git push --set-upstream origin hw5submit - Please notice that this is an atypical use of git branching. In practice a stable release is usually in the main repository and branches are used to develop new feature or bug fixes without affecting the primary release.
- When you submit through Gradescope, choose the 'Gitlab' button. This will connect to your CSE Gitlab account.
- Choose the repository, and branch, that contains on the HW5 code.
There is an autograder provided which will perform basic tests on your code. You should not use this autograder as your primary test mechanism, but it will provide some immediate feedback. There will be additional manual grading of your assignment that focuses on the code quality issues described above.
Evaluation
This assignment will be worth 50 points total. You will be evaluated based on the overall performance of your program, as well as your attention to the code quality points above.