Minimum Spanning Trees
MSTs.
Minimum Spanning Trees
- Trace Prim’s algorithm to find a minimum spanning tree in a graph.
- Compare and contrast Prim’s algorithm and breadth-first search.
- Apply the super-source node pattern to simplify graph problems.
The minimum spanning tree (MST) problem is about finding a spanning tree of minimum total weight in a connected and weighted undirected graph.
- Spanning tree
- A tree that connects all the vertices in an undirected graph.
- Tree (graph theory)
- A selection of vertices and edges in an undirected graph where there is only a single path between any two vertices.
Prim’s algorithm
Prim’s algorithm for finding an MST builds on the foundation of Dijkstra’s for finding an MST. Just like Dijkstra’s, Prim’s algorithm starts from a given vertex and gradually builds the tree structure on each iteration of the while loop. But there is 1 major difference:
- Earlier we learned that Dijkstra’s algorithm gradually builds a shortest paths tree on each iteration of the while loop. Prim’s algorithm does this similarily but instead selects the next unvisited vertex based on edge weight alone for the MST, whereas Dijkstra’s algorithm selects the next unvisited vertex based on the sum total cost of its shortest path.
In short, Prim’s algorithm builds a MST by repeatedly choosing the next-smallest edge to an unvisited vertex. The algorithm is finished once all the reachable vertices are visited.
Review the comments in this code snippet to identify how each difference appears in Prim’s algorithm.
public class PrimMST<V> implements MSTSolver<V> {
// Same edgeTo map as in Dijkstra's for shortest paths trees.
private final Map<V, Edge<V>> edgeTo;
// Same distTo map as in Dijkstra's for shortest paths trees.
private final Map<V, Double> distTo;
public PrimMST(Graph<V> graph) {
edgeTo = new HashMap<>();
distTo = new HashMap<>();
// The MST problem does not specify a start vertex.
// But, like Dijkstra's, Prim's algorithm requires a start vertex, so pick any vertex.
V start = graph.randomVertex();
// Unvisited vertices are considered in order of edge weight.
MinPQ<V> perimeter = new DoubleMapMinPQ<>();
perimeter.add(start, 0.0);
Set<V> visited = new HashSet<>();
while (!perimeter.isEmpty()) {
// Remove the next-smallest weight vertex from the perimeter.
V from = perimeter.removeMin();
// Mark a vertex as visited only after it's removed from the perimeter.
visited.add(from);
for (Edge<V> edge : graph.neighbors(from)) {
V to = edge.to;
double oldWeight = distTo.getOrDefault(to, Double.POSITIVE_INFINITY);
// Check that we haven't added the vertex to the MST already...
// Diff 1. AND this edge weight is better than the previous best edge weight to this vertex
// (infinity if this vertex has not been encountered before).
if (!visited.contains(to) && edge.weight < oldWeight) {
edgeTo.put(to, edge);
// Diff 1. Store the edge weight rather than distance from start.
distTo.put(to, edge.weight);
perimeter.addOrChangePriority(to, edge.weight);
}
// This entire if block is called "relaxing" an edge.
}
}
}
/** Returns a collection of edges representing a minimum spanning tree in the graph. */
public Collection<Edge<V>> mst() {
return edgeTo.values();
}
}
Cut property
How do we know Prim’s algorithm works?
- Prim’s algorithm stores all the next potential vertices to visit sorted by lowest-cost edge weight. In each iteration of the
whileloop, Prim’s algorithm grows the MST-in-progress by 1 vertex.
When Prim’s algorithm “grows the MST-in-progress” by selecting the lowest-cost edge to an unvisited vertex, it’s actually applying the cut property.
There are three key terms to define about the cut property.
- Cut
- A partitioning of the vertices of a graph into two non-empty sets.
- Crossing edge
- An edge that has one endpoint in each set of a cut.
- Cut property
- The idea that, for any cut, a minimum-weight crossing edge must be in an MST.
Prim’s algorithm can be understood as a repeated application of the cut property.
- Start with a single vertex in one set and every other unvisited vertex in the other set.
- On each iteration of the
whileloop, apply the cut property to choose the minimum-weight crossing edge. This expands the visited set by taking 1 vertex from the unvisited vertices. - Once the
whileloop is done and all reachable vertices have been visited, return the MST.
Disjoint Sets
QuickFindUF.javaQuickUnionUF.javaWeightedQuickUnionUF.java
- Trace Kruskal’s algorithm to find a minimum spanning tree in a graph.
- Compare Kruskal’s algorithm runtime on different disjoint sets implementations.
- Describe opportunities to improve algorithm efficiency by identifying bottlenecks.
A few weeks ago, we learned Prim’s algorithm for finding a minimum spanning tree in a graph. Prim’s uses the same overall graph algorithm design pattern as breadth-first search (BFS) and Dijkstra’s algorithm. All three algorithms:
- use a queue or a priority queue to determine the next vertex to visit,
- finish when all the reachable vertices have been visited,
- and depend on a
neighborsmethod to gradually explore the graph vertex-by-vertex.
Even depth-first search (DFS) relies on the same pattern. Instead of iterating over a queue or a priority queue, DFS uses recursive calls to determine the next vertex to visit. But not all graph algorithms share this same pattern. In this lesson, we’ll explore an example of a graph algorithm that works in an entirely different fashion.
Kruskal’s algorithm
Kruskal’s algorithm is another algorithm for finding a minimum spanning tree (MST) in a graph. Kruskal’s algorithm has just a few simple steps:
- Given a list of the edges in a graph, sort the list of edges by their edge weights.
- Build up a minimum spanning tree by considering each edge from least weight to greatest weight.
- Check if adding the current edge would introduce a cycle.
- If it doesn’t introduce a cycle, add it! Otherwise, skip the current edge and try the next one.
The algorithm is done when |V| - 1 edges have been added to the growing MST. This is because a spanning tree connecting |V| vertices needs exactly |V| - 1 undirected edges.
You can think of Kruskal’s algorithm as another way of repeatedly applying the cut property.
- Prim’s algorithm
- Applied the cut property by selecting the minimum-weight crossing edge on the cut between the visited vertices and the unvisited vertices. In each iteration of Prim’s algorithm, we chose the next-smallest weight edge to an unvisited vertex. Since we keep track of a set of visited vertices, Prim’s algorithm never introduces a cycle.
- Kruskal’s algorithm
- Instead of growing the MST outward from a single start vertex, there are lots of small independent connected components, or disjoint (non-overlapping) sets of vertices that are connected to each other.
Informally, you can think of each connected component as its own “island”. Initially, each vertex is its own island. These independent islands are gradually connected to neighboring islands by choosing the next-smallest weight edge that doesn’t introduce a cycle.1
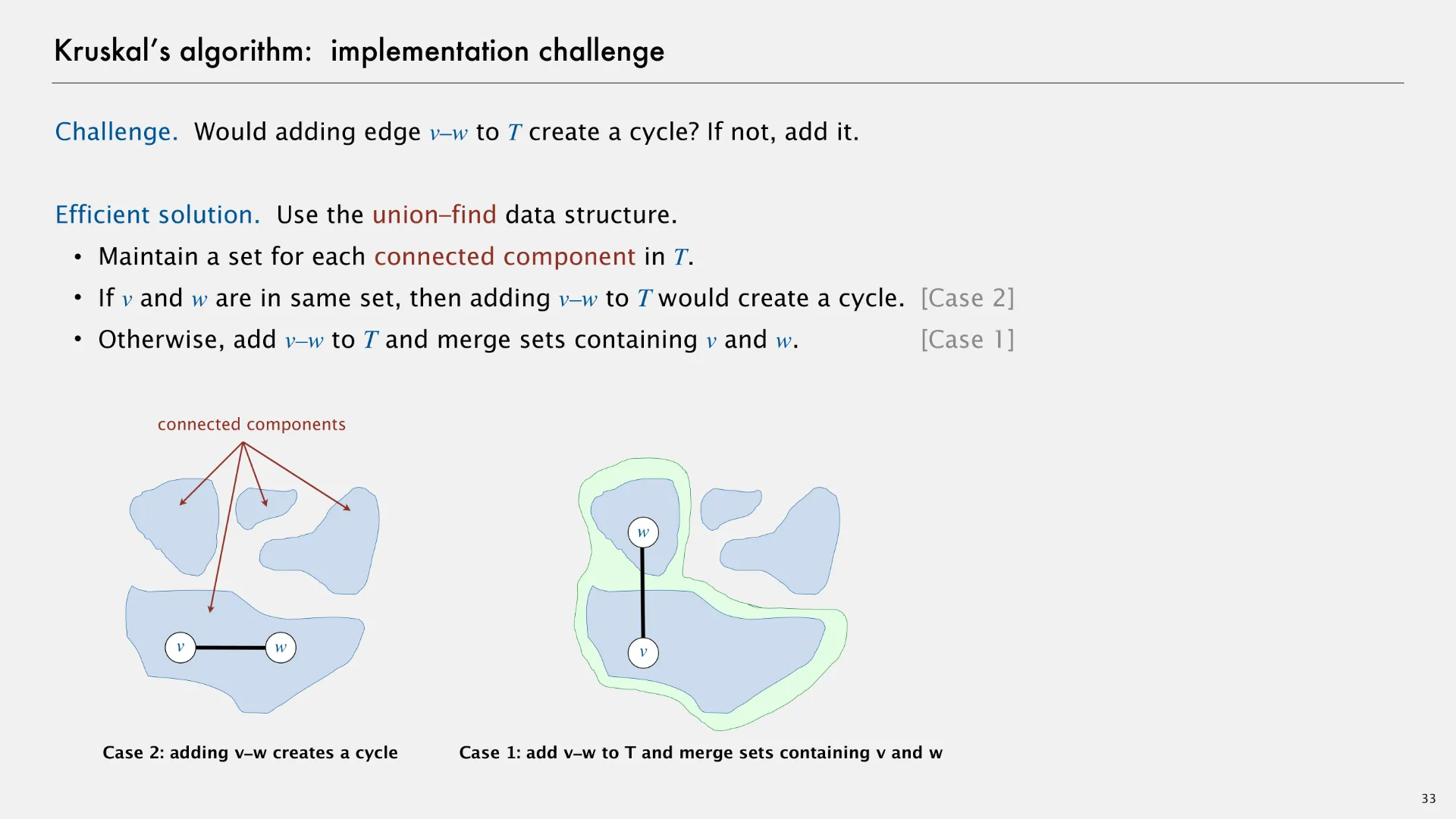
In case 2 (on the left of the above slide), adding an edge v-w creates a cycle within a connected component. In case 1 (on the right of the above slide), adding an edge v-w merges two connected components, forming a larger connected component.
Disjoint sets abstract data type
The disjoint sets (aka union-find) abstract data type is used to maintain the state of connected components. Specifically, our disjoint sets data type stores all the vertices in a graph as elements. A Java interface for disjoint sets might include two methods.
find(v)- Returns the representative for the given vertex. In Kruskal’s algorithm, we only add the current edge to the result if
find(v) != find(w). union(v, w)- Connects the two vertices v and w. In Kruskal’s algorithm, we use this to keep track of the fact that we joined the two connected components.
Using this DisjointSets data type, we can now implement Kruskal’s algorithm.
kruskalMST(Graph<V> graph) {
// Create a DisjointSets implementation storing all vertices
DisjointSets<V> components = new DisjointSetsImpl<V>(graph.vertices());
// Get the list of edges in the graph
List<Edge<V>> edges = graph.edges();
// Sort the list of edges by weight
edges.sort(Double.comparingDouble(Edge::weight));
List<Edge<V>> result = new ArrayList<>();
int i = 0;
while (result.size() < graph.vertices().size() - 1) {
Edge<V> e = edges.get(i);
if (!components.find(e.from).equals(components.find(e.to))) {
components.union(e.from, e.to);
result.add(e);
}
i += 1;
}
return result;
}
The remainder of this lesson will focus on how we can go about implementing disjoint sets.
Look-over the following slides where Robert Sedgewick and Kevin Wayne introduce 3 ways of implementing the disjoint sets (union-find) abstract data type.
- Quick-find
- Optimizes for the
findoperation. - Quick-union
- Optimizes for the
unionoperation, but doesn’t really succeed.
- Weighted quick-union
- Addresses the worst-case height problem introduced in quick-union.
Robert Sedgewick and Kevin Wayne. 2022. Minimum Spanning Trees. In COS 226: Spring 2022. ↩