Project 3: Extra credit
Due
Here are several possible extra credit ideas. These are all due on the same day part 3 is due.
Enhancing your query handling
Our TfIdfAnalyzer program has one major limitation: it can only handle queries that contain complete words with no typos. However, realistically, we probably can't expect our users to be capable of typing queries perfectly 100% of the time with no typos -- ideally, our search engine should be resilient to mistakes.
We might also be interested in enhancing the power of your search engine: our users might be interested in searching for exact phrases, performing wildcard searches, adding boolean operators, etc...
For this extra credit assignment, you will implement one or more of these different enhancements.
Specific enhancement ideas
Note: you may find the following book, especially the first few chapters, to be particularly useful when attempting to implement these enhancements:
"Introduction to Information Retrieval" – Manning, Raghavan, Schütze
- Implement a document relevance algorithm that is tolerent of typos
- Let users perform exact phrase searches -- e.g. searching
"hello world"will return all documents containing exactly the phrase "hello world". - Let users perform wildcard searches: so, searching for
lib*rywill return all documents containing a word starting with "lib", followed by some number of letters, followed by "ry". - Let users blacklist certain words: so, searching for
printer -cartridgewill perform a normal search on the word "printer", but will remove or suppress any documents that contain the word "cartridge". - Research some other feature an existing search engine supports or you think would be interesting, and implement it.
Note: you do not need to implement all of these things to get extra credit.
Deliverables
-
Create a new analyzer class named "EnhancedQueryAnalyzer" and add
it to your
search.analyzerspackage. Important note: do NOT change your working TfIdfAnalyzer class! -
Modify the
search.SearchEngineclass so it uses your new analyzer either along with or in place of TfIdfAnalyzer. - Implement one or more of the suggest enhancements in the previous section.
-
Create a new file located at
src/writeups/extra-credit.txtand document what you implemented and some examples of interesting queries we should try running to verify your work.
IDictionary variants: preserving sorted order
In project 2, you implemented a fairly standard chaining hash table. For extra credit, you will try implementing a dictionary that preserves the sorted order of its keys.. Specifically, you will implement an AVL tree.
Your AVL tree should implement the IDictionary<K, V>
interface, with the added restriction that all of its keys must implement
the Comparable<K> interface. When you iterate over the
AVL tree, the iterator should yield all the key value pairs in sorted order,
based on the key.
In other words, your AVL tree implementation should behave identically to
java.util.TreeMap.
Note: the hardest parts of this extra credit assignment will likely be correctly implementing all the AVL tree rotations and implementing the iterator.
Deliverables
-
Create a new class named "AvlTreeDictionary" and add it to the
datastructures.concrete.dictionariespackage. Your class should look like the following:public class AvlTreeDictionary<K extends Comparable<K>, V> implements IDictionary<K, V> { // Your code here } - Create a new test file that subclasses the "TestDictionary" class.
-
Create a new file located at
src/writeups/extra-credit.txtand document what you implemented. In particular, discuss how you implemented and verified the correctness of your rotation and balance preservation code as well as your iterator.
IDictionary variants: preserving insertion order
According to conventional wisdom, hashmaps are often thought to be inherently orderless: due to how hashing works, we retrieve the key/value pairs in no particular order when iterating over regular hash-based dictionaries. Broadly speaking, we treat this lack-of-ordering as the "price we pay" for getting fast \(\mathcal{O}(1)\) behavior.
For this extra credit, we will implement hash-based dictionaries that maintain this nice \(\mathcal{O}(1)\) runtime, but also preserve insertion order: it remembers the order in which we added the keys.
That is, if we have an IDictionary<Integer, String>
and we run:
dictionary.put(4, "a");
dictionary.put(11, "b");
dictionary.put(6, "c");
dictionary.put(7, "d");
dictionary.put(3, "e");
...then iterate over it, we're guaranteed to see the key-value pairs in the exact same order they were placed in the map. So in this case, if we iterate over dictionary, we're guaranteed that we'll see the pairs (4, "a"), (11, "b"), (6, "c"), (14, "d"), and (1, "e") in precisely that order.
Unlike the ChainingHashDictionary from project 2, this dictionary MUST be implemented using open addressing – we handle collisions by probing instead of adding elements to some chain. The trick is that instead of storing information in just a single array, we use two: one containing the key-value pairs, and another one containing indices into the first array.
For example, consider the example above. Suppose our dictionary initially has a capacity of 8, and suppose (for the sake of simplicity) that we use linear probing. After inserting all of our key-value pairs, our two internal arrays would look like the following:

Now, suppose we want to look up the value corresponding to the key "11". We hash this key as usual, and get 11 % 8 = 3. We look up the entry corresponding to cell 3, and see it contains the number 1. This means we should try looking at cell number 1 in the contents table. And indeed, in that cell, we can find the correct key-value pair:
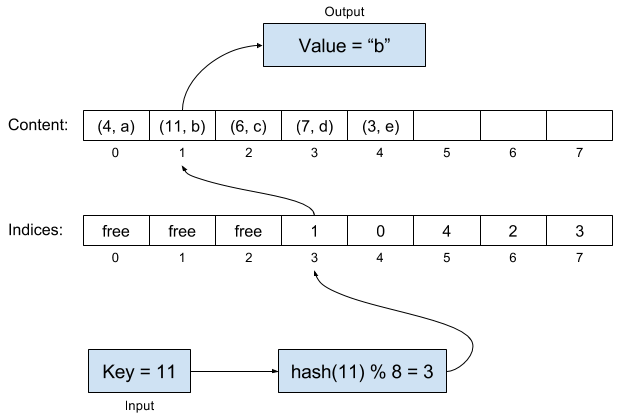
Initially, it might seem all we did was add an extra, unnecessary layer of indirection with the new array, but here's the trick! We can just traverse the "Content" array to get the order in which the keys were inserted.
Note: there are some more nuances here we haven't fully covered -- for example, how do we correctly implement remove and preserve insertion order? For full credit, your implementation's remove method should run in \(\mathcal{O}(1)\) time and always preserve insertion order: when we delete a key then iterate over the dictionary, we should yield the keys as if we had never inserted the deleted key to begin with.
Our example also uses linear probing -- that may not necessarily be the most efficient approach to take.
Deliverables
-
Create a new class named "InsertionPreservingDictionary" and add it to the
datastructures.concrete.dictionariespackage. Your class should subclass theIDictionary<K, V>class. - Create a new test file that subclasses the "TestChainedHashDictionary" class.
-
Create a new file located at
src/writeups/extra-credit.txtand document what you implemented. In particular, document how you handled remove and explain which probing strategy you picked and why.