In the first part of this lab, Chip D. Signer, Ph.D., is trying to reverse engineer a competitor's microprocessors to discover their cache geometries and has recruited you to help. Instead of running programs on these processors and inferring the cache layout from timing results, you will approximate his work by using a simulator.
In the second part of this lab, you will design a matrix transpose function that has as few cache misses as possible.
wget https://courses.cs.washington.edu/courses/cse351/23sp/files/labs/lab4.tar.gzRunning tar xvf lab4.tar.gz will extract the lab files to a directory called lab4 with the following files:
cache-test-skel.c - Skeleton code for determining cache parameterstestCache.sh - Script that makes and runs cache-test with all the cache object filescaches/cache_*.o - "Caches" with known parameters for testing your codecaches/mystery*.o - "Caches" with unknown parameters that you will need to discoversupport/mystery-cache.h - Defines the function interface that the object files exporttrans.c - Place for your transpose functionsgrade_trans.py - Script to run all part 2 performance tests and calculate scorecheck_trans_vars - Script to check for compliance with the lab4 variable usage rulessupport/test-trans.c - Code to test efficiency of your functions in trans.csupport/tracegen.c - Used by test-trans.c to generate memory tracessupport/csim-ref - Cache Simulator used by test-transsupport/cachelab.* - Helper code used by other programs in part 2Makefile - For compiling and linking filessynthesis/lab4synthesis.txt - For your Synthesis Question responsessynthesis/lab0.c - A copy of lab0 for your conveniencesynthesis/lab0.d - The assembly of compiled lab0.c, without any optimizations done by the compilersynthesis/lab0opt.d - The assembly of compiled lab0.c, with optimizations done by the compiler (compiled with the flag-O2)Each of the “processors” is provided as an object file (.o file) against which you will link your code. The filemystery-cache.h defines the function interface that these object files export. It includes a typedef for a type addr_t (an unsigned 8-byte integer) which is what these (pretend) caches use for "addresses", or you can use any convenient integer type.
typedef unsigned long long addr_t;
typedef unsigned char bool_t;
#define TRUE 1
#define FALSE 0
/** Lookup an address in the cache. Returns TRUE if the access hits,
FALSE if it misses. */
bool_t access_cache(addr_t address);
/** Clears all words in the cache.
Useful for helping you reason about the cache
transitions, by starting from a known state. */
void flush_cache(void);Your job is to fill in the function stubs incache-test-skel.c which, when linked with one of these cache object files, will determine and then output the cache size, associativity, and block size. You will use the functions above to perform cache accesses and use your observations of which ones hit and miss to determine the parameters of the caches.
Some of the provided object files are named with this information (e.g., cache_65536c_2e_16k.ois a 65536 Byte capacity, 2-way set-associative cache with 16 Byte blocks) to help you check your work. There are also 4 mystery cache object files, whose parameters you must discover on your own.
You can assume that the mystery caches have sizes that are powers of 2 and use a least recently used replacement policy. You cannot assume anything else about the cache parameters except what you can infer from the cache size. Finally, the mystery caches are all pretty realistic in their geometries, so use this fact to sanity check your results.
You will need to complete this assignment on a Linux machine with the C standard libraries (e.g., the CSE VM, attu). The provided Makefile includes a target cache-test. To use it, set TEST_CACHEto the object file to link against on the command line. That is, from within the lab4 directory run the command:
$ make cache-test TEST_CACHE=caches/cache_65536c_2e_16k.oThis will create an executable cache-test that will run your cache-inference code against the supplied cache object. Run this executable like so:
$ ./cache-testand it will print the results to the screen.
We've also included a script calledtestCache.sh in your lab directory that makes and runs cache-test with all the object files. This is provided to help you test your code. But you are not required to use it and it is provided without support. Run this shell script like so:
$ bash testCache.shIn Part II, you will write a transpose function in trans.c that causes as few cache misses as possible.
Let A denote a matrix, and Aij denote the component in the ith row and jth column. The transpose of A, denotated AT, is a matrix such that for all i and j, Aij = ATji
To help you get started, we have given you an example transpose function in trans.c that computes the transpose of M x N matrix A and stores the results in N x M matrix B:
char trans_desc[] = "Simple row-wise scan transpose";
void trans(int M, int N, int A[M][N], int B[N][M])The example transpose function is correct, but it is inefficient because the access pattern results in relatively many cache misses.
Your job in Part II is to write a similar function, called transpose_submit, that minimizes the number of cache misses across different sized matrices on a simulated cache with parameters:
s (Index Bits) = 5E (Associativity) = 1k (Offset Bits) = 5char trans_desc[] = "Transpose submission";
void transpose_submit(int M, int N, int A[M][N], int B[N][M])The Linux program valgrind can generate traces of memory accesses of programs. For example, typing
$ valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -lon the command line runs ls -l, captures the memory accesses in order, and prints them to stdout.
valgrind memory accesses have the following form:
I 0400d7d4,8
M 0421c7f0,4
L 04f6b868,8
S 7ff0005c8,8
Each line denotes one or two memory accesses. The format of each line is:
[space]operation address,sizeThe operation field denotes the type of memory access: "I" denotes an instruction load, "L" a data load, "S" a data store and "M" a data modify (i.e., a data load followed by a data store). There is never a space before each "I". There is always a space before each "M", "L", and "S". The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
Tools in this lab use valgrind traces of your code running on a cache simulator to evaluate the efficiency of your transpose function. See Hints for more information.
Include your name and NetID in the header comment for trans.c.
Your code in trans.c must compile without warnings to receive credit.
Your transpose function may not use recursion.
You are allowed to define at most 12 local variables of type int per transpose function. This means 12 variables in scope at once. For example the following code would be allowed:
/* Note: function arguments are not counted as local variables */
void func_ok(int x, int y) {
int array1[8];
if (x == y) {
int array2[4]; // OK: 12 ints in scope
} else {
int array3[2]; // OK: 10 ints in scope
}
}
But the following is not:
void func_bad(int x, int y) {
int array1[8];
if (x == y) {
int array2[2]; // OK: 10 ints in scope
if (x > 0) {
int array3[4]; // BAD: 14 ints in scope
// Even though this branch may not always run,
// the MAXIMUM number of local ints exceeds 12.
}
}
}
The reason for this restriction is that our testing code is not able to count references to the stack. We want you to limit your references to the stack and focus on the access patterns of the source and destination arrays.
Your are permitted to use int arrays, but arrays do count towards your 12 localints. For example, if you have already declared 4ints, you could declare an array of ints up to size 8.
You are not allowed to side-step the previous rule by using any variables of type long or by using any bit tricks to store more than one value to a single variable.
If you choose to use helper functions, you may not have more than 12 local variables on the stack at a time between your helper functions and your top level transpose function. For example, if your transpose declares 8 variables, and then you call a function which uses 4 variables, which calls another function which uses 2, you will have 14 variables on the stack, and you will be in violation of the rule.
malloc.For Part 2, we will evaluate the correctness and performance of your transpose_submit function on 2 different-sized input matrices:
For each matrix size, the performance of your transpose_submit function is evaluated by usingvalgrind to extract the address trace for your function, and then using the reference simulator to replay this trace on a cache with parameters s (Index Bits) = 5, E (Associativity) = 1, k (Offset Bits) = 5 .
Your performance score for each matrix size scales linearly with the number of misses, m, up to the following thresholds:
Your code must be correct to receive any performance points for a particular size. Your code only needs to be correct for these two cases and you can optimize it specifically for these two cases. In particular, it is perfectly OK for your function to explicitly check for the input sizes and implement separate code optimized for each case.
We have provided you with a driver program, called grade_trans.py, that performs a complete evaluation of your transpose code's correctness and performance for both matrix sizes. This is the same program your instructor uses to evaluate your submission. The driver uses test-trans to evaluate your submitted transpose function on the two matrix sizes. Then it prints a summary of your results and the points you have earned. To run the driver, type:
$ make # You need to run make every time you change your code
$ python3 grade_trans.pyIn addition to the correctness and performance score, you must pass the programming rules check. Failing the rules check will result in NO POINTS for part 2. To run the rules check:
$ ./check_trans_vars trans.c
Variables used by transpose_submit: 2
transpose_submit passes the programming rules checks.
Extra credit will be awarded for code that results in fewer misses than the full score "baselines."
For reference, there exist solutions with m as low as 259 (32 x 32) and 1052 (64 x 64).
We reserve the right to set the threshold for "full extra credit" (5/5 points) below these numbers.
You can check the performance and correctness scores of your transpose functions by running test-trans. Your final submission must go in the giventranspose_submit function. However, we provide the ability to try out multiple implementations; see below for more details.
To test your code for a particular size of matrix:
$ make # run make each time you change your code
$ ./test-trans -M 32 -N 32
Function 0 (1 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 0 (Transpose submission): hits:1766, misses:288, evictions:255
Summary for official submission (func 0): correctness=1 misses=288
The test program ran the solution function and printed out two pieces of information:
Additionally, you can test both the 32x32 and 64x64 matrices at once and see your point scores for the assignment:
$ make
$ python grade_trans.py
Part B: Testing transpose function
Running ./test-trans -M 32 -N 32
Running ./test-trans -M 64 -N 64
Cache Lab summary:
Points Max pts Misses
Trans perf 32x32 5.00 5 288
Trans perf 64x64 5.00 5 1107
Total points 10.00 1
As stated above, you will receive no points for part 2 if you violate the programming rules. As with lab1a, we provide you the script we use to check programming rule correctness for part II. To check for violations, run the following command:
$ ./check_trans_vars trans.cIf your code passes the checks, you will see the following:
$ ./check_trans_vars trans.c
Variables used by transpose_submit: 2
transpose_submit passes the programming rules checks.
If it fails, you will see something like this:
$ ./check_trans_vars trans.c
transpose_submit DOES NOT PASS the programming rules checks:
- Maximum variable count exceeded (transpose_submit: 14)
- Disallowed variable type(s) used: long
We have provided you with an autograding program, called test-trans.c that tests the correctness and performance of each of the transpose functions that you have registered with the autograder.
You can register up to 100 versions of the transpose function in your trans.c file. Each transpose version has the following form:
/* Header comment */
char trans_simple_desc[] = "A simple transpose";
void trans_simple(int M, int N, int A[M][N], int B[N][M])
{
/* your transpose code here */
}
To register a particular transpose function with the autograder, make a call in the registerFunctionsroutine in trans.c of the form:
registerTransFunction(trans_simple, trans_simple_desc); At runtime, the autograder will evaluate each registered transpose function and print the results. Of course, one of the registered functions must be thetranspose_submit function that you are submitting for credit:
registerTransFunction(transpose_submit, transpose_submit_desc);See the default trans.c function for an example of how this works.
The autograder takes the matrix size as input. It uses valgrind to generate a trace of each registered transpose function. It then evaluates each trace by running a cache simulator called csim-ref on a cache with parameters s (Index Bits) = 5, E (Associativity) = 1, k (Offset Bits) = 5, though csim-ref uses the equivalent notation from the book s = 5, E = 1, b = 5.
For example, to test your registered transpose functions on a 32 x 32 matrix, rebuild test-trans, and then run it with the appropriate values for M and N:
$ make
$ ./test-trans -M 32 -N 32
Step 1: Evaluating registered transpose funcs for correctness:
func 0 (Transpose submission): correctness: 1
func 1 (Simple row-wise scan transpose): correctness: 1
func 2 (column-wise scan transpose): correctness: 1
func 3 (using a zig-zag access pattern): correctness: 1
Step 2: Generating memory traces for registered transpose funcs.
Step 3: Evaluating performance of registered transpose funcs (s (Index Bits) = 5, E (Associativity) = 1, k (Offset Bits) = 5)
func 0 (Transpose submission): hits:1766, misses:288, evictions:255
func 1 (Simple row-wise scan transpose): hits:870, misses:1183, evictions:1151
func 2 (column-wise scan transpose): hits:870, misses:1183, evictions:1151
func 3 (using a zig-zag access pattern): hits:1076, misses:977, evictions:945
Summary for official submission (func 0): correctness=1 misses=288
In this example, we have registered four different transpose functions in trans.c. The test-transprogram tests each of the registered functions, displays the results for each, and extracts the results for the official submission.
This Intel post is a good place to start if you are stuck.
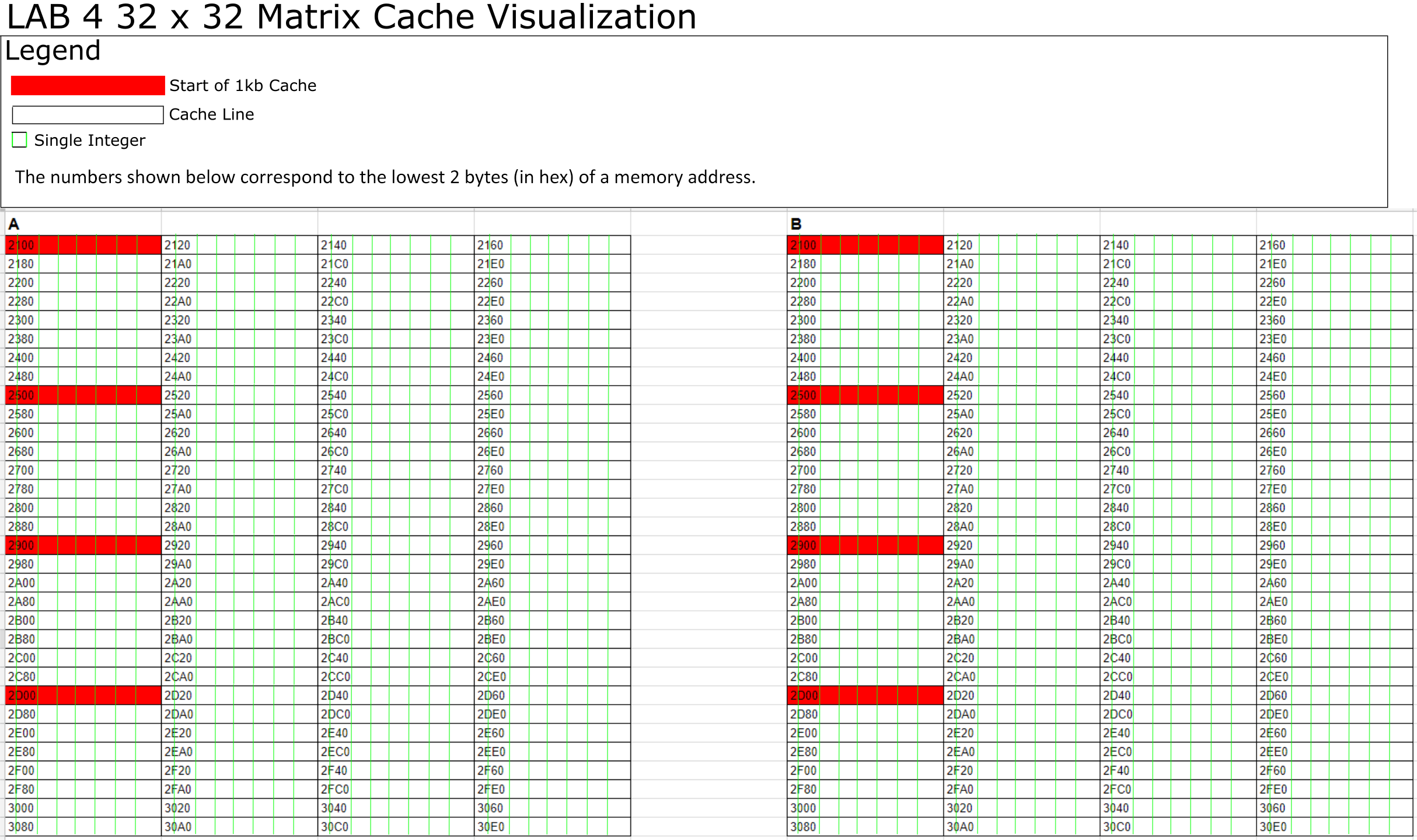
This image shows the last 2 bytes of the address of each cache block as they align to the 32x32 matricies. Red squares notate the start of a section that would fit in cache. Green lines divide individual integers, and black lines divide cache blocks.
The cache simulator is available to help you get practice with and visualize different cache operations and mechanics. See the associated worksheet for more information.
The Matrix Visualizer can help you visualize how matrices are laid out in memory, which may come in handy for Part 2. Just select the parameters of your matrix and you can see what the address of every element is.
If you have variables specific to one case of an "if", you can declare the variable within that block and it will only count against your variable count for code in that part of the "if". Remember — you're only limited by the number of variables that exist at one time. You can declare variables within "if" statements and loops. This is especially helpful if you have different variables for the two matrix sizes.
Use #define! These don't count against your variable total. You can declare constants using #define and use them wherever you want.
Always use a constant integer size when declaring arrays. The variable rules checker will fail if you don't do this. For example, instead of this:
int size = 5;
int array[size]; // error: trans.c:24:9: Unable to process due to non-constant value "size" used in array declaration.
// Please use a constant integer as the array dimension.int array[5]; // OK!The test-trans program saves the trace for the function i in the file trace.fi. These trace files are invaluable debugging tools that can help you understand exactly where the hits and misses for each transpose function are coming from. To debug a particular function, simply run its trace through the reference simulator with the verbose option:
$ ./support/csim-ref -v -s 5 -E 1 -b 5 -t trace.f0
S 68312c,1 miss
L 683140,8 miss
L 683124,4 hit
L 683120,4 hit
L 603124,4 miss eviction
S 6431a0,4 miss
...
If you find mention online of a recursive "cache-oblivious algorithm" for matrix transpose, is not a good choice as recursion is not allowed in your solution.
Since your transpose function is being evaluated on a direct-mapped cache, conflict misses are a potential problem. Think about the potential for conflict misses in your code, especially along the diagonal. Try to think of access patterns that will decrease the number of these conflict misses.
In the synthesis directory of your lab, you will find lab0.c, along with two other files:
lab0.d: The assembly of compiled lab0.c, without any optimizations done by the compiler.lab0opt.d: The assembly of compiled lab0.c, with optimizations done by the compiler (compiled with the flag -O2).While doing the synthesis, we expect you will read the assembly, rather than use GDB, to answer the questions. Attempting to compile then run GDN on lab0.c may get you different assembly than what we're using to grade responses.
Questions
In part_4, the nested loops come between the calls to clock() (callq <clock@plt> in the assembly). How many of the assembly instructions in the nested loops access (read or write to) memory? Provide the count and list of instructions for both the unoptimized and optimized code. For the lists of instructions, you can either copy and paste the instructions or include the relative address of each instruction (<func+##>). [2 pt]
Only count each instruction once; ignore the looping mechanics and multiple accesses in a single instruction.
nop* is a family of instructions that do nothing (i.e., they don't access memory).
Don't count the instructions found in big_array_index, but the callq <big_array_index> instruction is part of the nested loops.
Only count the number of data accesses caused by the execution of the instructions and not by their retrieval.
In the unoptimized code, where are the loop variables i, j, and k "stored?" Give the corresponding assembly operands ( e.g., %r8, 2(%rax)) and not
In the optimized code, the loop variables have sort of disappeared! Name what the values found in registers %edx and %rcx correspond to in the C code. [2 pt]
Take a look at your transpose code for the 32 x 32 matrix. If the starting address of matrix A did not map to the beginning of a cache block, how would the number of misses be affected? (Increase / Stay the Same / Decrease) Briefly explain. [2 pt]
Take a look at your transpose code for the 64 x 64 matrix. If you were to run this code for a matrix of size 57 x 71, how would the number of misses be affected? (Increase / Stay the Same / Decrease) Briefly explain. [2 pt] (Hint: You don’t need to modify your code to work with this matrix size. Use what you know about cache images to answer this.)
Submit your completed cache-test-skel.c, trans.c, and lab4synthesis.txt files to the "Lab 4" assignment on Gradescope.
If you completed the extra credit, also submit the same trans.c file to the "Lab 4 Extra Credit" assignment on Gradescope.
After submitting, please wait until the autograder is done running and double-check that you passed the "File Check" and "Compilation and Execution Issues" tests. If either test returns a score of -1, be sure to read the output and fix any problems before resubmitting. Failure to do so will result in a programming score of 0 for the lab.
It is fine to submit multiple times up until the deadline, we will only grade your last submission. NOTE that if you do re-submit, you MUST RE-submit ALL files again.
{kind=link}