name: inverse layout: true class: center, middle, inverse --- # Google maps 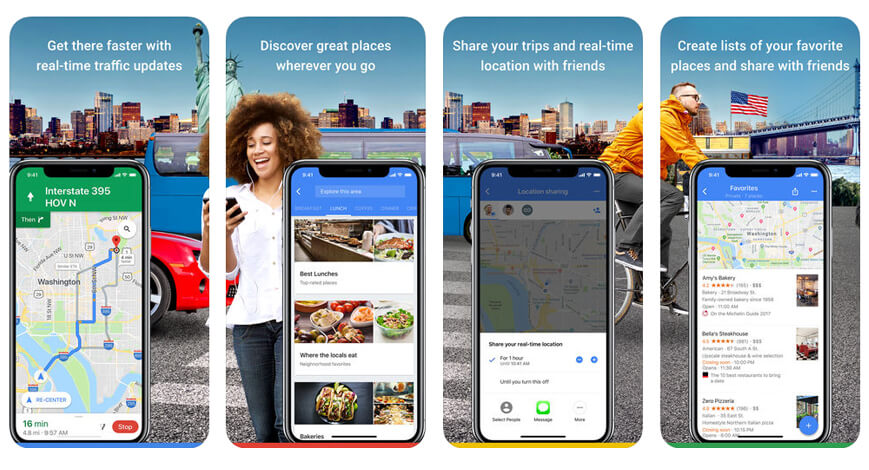](img/ml/google.jpg) .footnote[Picture from [Machine Learning on your Phone](https://www.appypie.com/top-machine-learning-mobile-apps)] ??? fame/shame neighborhood traffic... shorter commutes... --- # Machine Learning and your Phone Jennifer Mankoff CSE 340 Spring 2020 .footnote[Slides credit: Jason Hong, Carnegie Mellon University [Are my Devices Spying on Me? Living in a World of Ubiquitous Computing](https://www.slideshare.net/jas0nh0ng/are-my-devices-spying-on-me-living-in-a-world-of-ubiquitous-computing); ] --- layout: false .left-column[ ## Smartphones are Intimate Fun Facts about Millennials ![:fa thumbs-down] 83% sleep with phones ] .right-column[  ] --- .left-column[ ## Smartphones are Intimate Fun Facts about Millennials ![:fa thumbs-down] 83% sleep with phones ![:fa thumbs-down] 90% check first thing in morning ] .right-column[  ] --- .left-column[ ## Smartphones are Intimate Fun Facts about Millennials ![:fa thumbs-down] 83% sleep with phones ![:fa thumbs-down] 90% check first thing in morning ![:fa thumbs-down] 1 in 3 use in bathroom ] .right-column[  ] --- # Smartphone Data is Intimate  | Who we know | Sensors | Where we go | |-----------------------|-----------------------|---------------| | (contacts + call log) | (accel, sound, light) | (gps, photos) | --- # Some useful applications of this data  .footnote[[LeafSnap](http://leafsnap.com/) uses computer vision to identify trees by their leaves] --- # Some useful applications of this data  .footnote[[Vision AI](https://www.aipoly.com/) uses computer vision to identify images for the Blind and Visually Impaired] --- # Some useful applications of this data  .footnote[[Carat: Collaborative Energy Diagnosis](http://carat.cs.helsinki.fi/) uses machine learning to save battery life] --- # Some useful applications of this data  .footnote[[Imprompdo](http://imprompdo.webflow.io/ ) uses machine learning to recommend activities to do, both fund and todos] --- # How do these systems work? Machine Learning is used to make these kinds of predictions - Machine learning is one area of Artificial Intelligence - This is the kind that’s been getting lots of press The goal of machine learning is to develop systems that can improve performance with more experience - Can use "example data" as "experience" - Uses these examples to discern patterns - And to make predictions --- # Two main approaches ![:fa eye] *Supervised learning* (we have lots of examples of what should be predicted) ![:fa eye-slash] *Unsupervised learning* (e.g. clustering into groups and inferring what they are about) ![:fa low-vision] Can combine these (semi-supervised) ![:fa history] Can learn over time or train up front --- .left-column[ ## In class exercise ![:fa bed, fa-7x] ] .right-column[ How might you recognize sleep? - What recognition question - What sensors ] ??? (sleep quality? length?...) How to interpret sensors? --- .left-column[ ## In class exercise - What recognition question (sleep quality? length?...) - What sensors - How to interpret sensors? ] .right-column[  ] --- # How do we program this? Write down some rules Implement them --- # ML is a major shift in thinking Old Approach: Create software by hand - Use libraries (like JQuery) and frameworks - Create content, do layout, code up functionality - Deterministic (code does what you tell it to) New Approach: Collect data and train algorithms - Will still do the above, but will also have some functionality based on ML - *Collect lots of examples and train a ML algorithm* - *Statistical way of thinking* --- # How Machine Learning is Typically Used Step 1: Gather lots of data (easy on a phone!) -- Step 2: Figure out useful features - Convert data to information (not knowledge!) - (typically) Collect labels --- # How Machine Learning is Typically Used Step 1: Gather lots of data (easy on a phone!) Step 2: Figure out useful features Step 3: Select and train the ML algorithm to make a prediction - Lots of toolkits for this - Lots of algorithms to choose from - Mostly treat as a "black box" --- # Example: Decision tree for predicting premature birth  --- # Examwple: Deep Learning for Image Captioning  .footnote[[Captioning images. Note the errors.](http://cs.stanford.edu/people/karpathy/deepimagesent/) Deep learning now [available on your phone!](https://www.tensorflow.org/lite)] ??? Note differences between these: one label vs many --- # Training process  --- # How Machine Learning is Typically Used Step 1: Gather lots of data (easy on a phone!) Step 2: Figure out useful features Step 3: Select and train the ML algorithm Step 4: Evaluate metrics (and iterate) ??? See how well algorithm does using several metrics Error analysis: what went wrong and why Iterate: get new data, make new features --- # Evaluation Concerns Accuracy: Might be too error-prone --- .left-column[ ## Assessing Accuracy] .right-column[ Prior probabilities - Probability before any observations (ie just guessing) - Ex. ML classifier to guess if a person is male or female based on name - Just assume all names are female (50% will be right) - Your trained model needs to do better than prior Other baseline approaches - Cheap and dumb algorithms - Ex. Names that end in vowel are female - Your model needs to do better than these too ] ??? We did this to study gender's impact on academic authorship; doctors reviews --- .left-column[ ## Assessing Accuracy] .right-column[ Don't just measure accuracy (percent right) Sometimes we care about *False positives* vs *False negatives* ] --- .left-column[ ## Assessing Accuracy ## Confusion matrix helps show this] .right-column[ | | | .red[Prediction] | | |-------------|--------------|----------------------|----------------------| | | | **Positive** | **Negative** | | .red[Label] | **Positive** | True Positive (good) | False Negative (bad) | | | **Negative** | False Positive (bad) | True Negative (good) | Accuracy is (TP + TN) / (TP + FP + TN + FN) ] --- .left-column[ ## Assessing Accuracy ## Precision ] .right-column[ | | | .red[Prediction] | | |-------------|--------------|----------------------------|----------------------| | | | **Positive** | **Negative** | | .red[Label] | **Positive** | .red[True Positive (good)] | False Negative (bad) | | | **Negative** | .ref[False Positive (bad)] | True Negative (good) | Precision = TP / (TP+FP) Intuition: Of the positive items, how many right? ] --- .left-column[ ## Assessing Accuracy ## Recall ] .right-column[ | | | Prediction | | |--------|--------------|----------------------------|----------------------------| | Actual | | **Positive** | **Negative** | | | **Positive** | .red[True Positive (good)] | .red[False Negative (bad)] | | | **Negative** | False Positive (bad) | True Negative (good) | Recall = TP / (TP+FN) Intuition: Of all things that should have been positive, how many actually labeled correctly? ] --- # Evaluation Concerns Accuracy: Might be too error-prone Overfitting: Your ML model is too specific for data you have - Might not generalize well  --- # Avoiding Overfitting To avoid overfitting, typically split data into training set and test set Train model on training set, and test on test set Often do this through cross validation  --- # How Machine Learning is Typically Used Step 1: Gather lots of data (easy on a phone!) Step 2: Figure out useful features Step 3: Select and train the ML algorithm Step 4: Evaluate metrics (and iterate) Step 5: Deploy --- # What makes this work well? Typically more data is better Accurate labels important Quality of features determines quality of results .red[*NOT* as sophisticated as the media makes out] -- .red[*BUT* can infer all sorts of things] --- # AI / Machine Learning Not As Sophisticated as in Media A lot of people outside of computer science often ascribe human behaviors to AI systems - Especially desires and intentions - Works well for sci-fi, but not for today or near future These systems only do: - What we program them to do - What they are trained to do (based on the (possibly biased) data) --- # Concerns Significant Societal Challenges for Privacy --- .left-column[ ## Wide Range of Privacy Risks] .right-column[ | Everyday Risks | Medium Risk | Extreme Risks | |--------------------|---------------------|-------------------| | Friends, Family | Employer/Government | Stalkers, Hackers | | Over-protection | Over-monitoring | Well-being | | Social obligations | Discrimination | Personal safety | | Embarrassment | Reputation | Blackmail | | | Civil Liberties | | - It's not just Big Brother - It-s not just corporations - Privacy is about our relationships with every other individual and organization out there ] --- # Five Reasons Why Privacy is Hard ### 1 Strong Incentives to for Companies to Collect Data ### 2 Low Knowledge, Awareness, Motivation by Devs ### 3 Companies Get Little Pushback on Privacy ### 4 Unclear What the Right Thing To Do Is ### 5 Burden on End-Users is Too High ??? - Barriers to collecting data are also really low - More data means better predictive models - Many developers don’t realize how much data their app is collecting (Or that it was collecting data at all) - In one study, over 40% of apps collect data only because of these libraries - Lack of info means privacy does not influence customer purchases. Less than 0.1% of reviews on Google Play mention privacy concerns - Individuals also have to make too many decisions --- # Concerns Significant Societal Challenges for Privacy Who should have the initiative? --- # Mixed-initiative interfaces Basically, who is in charge? - Does person initiate things? Or computer? - How much does computer system do on your behalf? Example: Autonomous vehicles - Some people think Tesla autopilot is full autonomous, leads to risky actions Why initiative matters - Potential major shift: instead of direct manipulation, some smarts (intelligent agent) for automation --- .left-column50[ ## Mixed-initiative best practices - Significant value-added automation - Considering uncertainty - Socially appropriate interaction w/ agent - Consider cost, benefit, uncertainty - Use dialog to resolve uncertainty - Support direct invocation and termination - Remember recent interactions ] .right-column50[  ] --- .left-column50[ ## Mixed-initiative best practices - Significant value-added automation - Considering uncertainty - Socially appropriate interaction w/ agent - Consider cost, benefit, uncertainty - Use dialog to resolve uncertainty - Support direct invocation and termination - Remember recent interactions ] .right-column50[  ] ??? Can see what agent is suggesting, in terms of scheduling a meeting --- .left-column50[ ## Mixed-initiative best practices - Significant value-added automation - Considering uncertainty - Socially appropriate interaction w/ agent - Consider cost, benefit, uncertainty - Use dialog to resolve uncertainty - Support direct invocation and termination - Remember recent interactions ] .right-column50[  ] ??? Uses anthropomorphized aganet Uses speech for input Uses mediation to help resolve conflict --- .left-column[ ## Mixed-initiative best practices ] .right-column[ Built-in cost-benefit model in system - If perceived benefit >> cost, then do the action - Otherwise wait Note that this is just one point in design space (1999), and still lots of open questions - Ex. Should “intelligence” be anthropomorphized? - Ex. How to learn what system can and can’t do? - Ex. What kinds of tasks should be automated / not? - Ex. What are strategies for showing state of system? - Ex. What are strategies for preventing errors? ] --- # Concerns Significant Societal Challenges for Privacy Who should have the initiative? Bias in Machine Learning --- background-image: url(img/ml/gma.png) .quote[Johnson says his jaw dropped when he read one of the reasons American Express gave for lowering his credit limit: ![:fa quote-left] Other customers who have used their card at establishments where you recently shopped have a poor repayment history with American Express. ] --- .right-column[  ] --- # Concerns Significant Societal Challenges for Privacy Who should have the initiative? Bias in Machine Learning Understanding ML --- # Understanding what is going on: Forming Mental Models How does a system know I am addressing it? How do I know a system is attending to me? When I issue a command/action, how does the system know what it relates to? How do I know that the system correctly understands my command and correctly executes my intended action? .footnote[ Belloti et al., CHI 2002 ‘Making Sense of Sensing’ ] --- # Wrong location-based rec  ??? Why did it not tell me about the Museum? How does it determine my location? Providing explana7ons to these ques7ons can make Intelligent systems Intelligible other examples: caregiving hours by insurance company, etc --- # Types of feedback Feedback: crucial to user’s understanding of how a system works and helping guide future action - What did the system do? - What if I do W, what will the system do? - Why did the system do X? - Why did the system not do Y - How do I get the system to do Z? --- # Summary ML and ethics ML is powerful (but not perfect), often better than heuristics Basic approach is collect data, train, test, deploy Hard to understand what algorithms are doing (transparency) - ML algorithms just try to optimize, but might end up finding a proxy for race, gender, computer, etc - But hard to inspect these algorithms - Still a huge open question Privacy - How much data should be collected about people? - How to communicate this to people? - What kinds of inferences are ok? --- # End of deck --- .left-column[ ## Regression  ] .right-column[ Predicting a *continuous value* based on inputs - Ex. House price based on #rooms, #bathrooms, etc - Ex. #views based on page content Simple example: linear regression - Same as in statistics - Seeks to minimize error in predictions Lots of algorithms - See Wikipedia ] --- .left-column[ ## Example classification algorithms] .right-column[ Naïve Bayes (probabilities) Neural Networks / Deep Learning (human brain) **Decision Tree (workflow)** Support Vector Machine (analogy / similarity) ] --- .left-column[ ## Classification ] .right-column[ Predicting from a *set of categories* - Ex. {Spam, Ham}? - Ex. {Chalupa, Taco, Burrito}? Lots of variants - Multi-class (the examples above) - One-class (identifies all objects in that class) - Multi-label (it’s both a Chalupa and a Burrito) Also lots of algorithms - See Wikipedia ]
