Homework 3
Due: Tuesday, Nov 19th, 2024 by 10:00 pm
Goals & Guidelines
In this assignment you will build on top of your HW2 implementation: In Part A, you will write code that takes an in-memory inverted index produced by HW2 and writes it out to disk in an architecture-neutral format. In Part B, you will write C++ code that walks through an on-disk index to service a lookup. Finally, in Part C, you will write a query processor that serves queries from multiple on-disk indices.
As before, please read through this entire document before beginning the assignment, and please start early! As usual, there is a lot of code involved with HW3, and since this is your first large-scale attempt to use C++ you should expect to encounter a lot of problems along the way. Also, manipulating on-disk data is trickier than in-memory data structures, so plan for some time to get this part right.
In HW3, as with HW2, you don't need to worry about propagating errors back to callers in all situations. You will use Verify333()'s to spot errors and cause your program to crash out if they occur. We will not be using C++ exceptions in HW3.
Also, as before, you may not modify any of the existing header files or class definitions distributed with the code. If you wish to add extra "helper" functions you can to do that by including additional static functions in the implementation (.cc) files.
Disk-Based File System Search Engine
Part A: Memory-to-File Index Marshaller
Keeping a search engine index in memory is problematic, since memory is expensive and also volatile. So, in Part A, you're going to write some C++ code that takes advantage of your HW2 implementation to first build an in-memory index of a file subtree, and then it will write that index into an index file in an architecture-neutral format.
What do we mean by architecture-neutral? Every time we need to store a binary integer in the file's data structure, we will store it in big endian representation. This is the representation that is conventionally used for portability, but the bad news is that this is the opposite representation than most computers you use: x86 computers are little endian. So, you will need to convert integers (whether 16-bit, 32-bit, or 64-bit) into big endian before writing them into the file. We provide you with helper functions to do this.
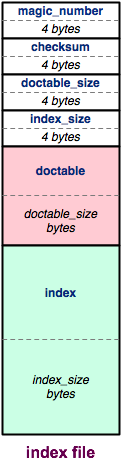
The good news is that we're going to keep roughly the same data structure inside the file as you built up in memory: we'll have chained hash tables that are arrays of buckets containing linked lists. And, our inverted index will be a hash table containing a bunch of embedded hash tables. But, we need to be very precise about the specific layout of these data structures within the file. So, let's first walk through our specification of an index file's format. We'll do this first at a high level of abstraction, showing the major components within the index file. Then, we'll zoom into these components, showing additional details about each.
At a high-level, the index file looks like the figure on the right. The index file is split into three major pieces: a header, the doctable, and the index. We'll talk about each in turn.
Header: an index file's header contains metadata about the rest of the index file.
The first four bytes of the header are a
magic number,
or format indicator. Specifically, we use the 32-bit
number 0xCAFEF00D. We will always write
the magic number out as the last step in preparing an index
file. This way, if the program crashes partway through
writing one, the magic number will be missing, and it will
be easy to tell that the index file is corrupt.
The next four bytes are a checksum of the doctable and index regions of the file. A checksum is a mathematical signature of a bunch of data, kind of like a hash value. By including a checksum of most of the index file within the header, we can tell if the index file has been corrupted, such as by a disk error. If the checksum stored in the header doesn't match what we recalculate when opening an index file, we know the file is corrupt and we can discard it.
The next four bytes store the size of the doctable region of the file. The size is stored as a 32-bit, signed, big endian integer.
The final four bytes of the header store the size of the index region of the file, in exactly the same way.
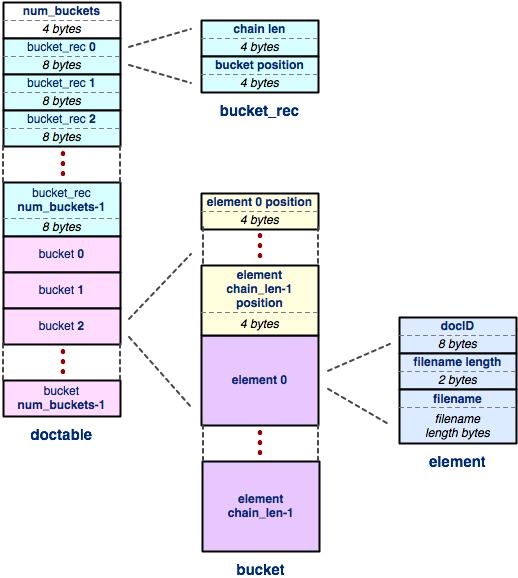
Doctable: Let's drill down into the next level of
detail by examining the content of the doctable region
of the file. The doctable is a hash table that stores a
mapping from 64-bit document ID to an ASCII string
representing the document's filename. This is the
docid_to_docname HashTable that you built up in
HW2, but stored in the file rather than in memory.
The doctable consists of three regions; let's walk through them, and then drill down into some details.
-
num_buckets: this region is the simplest; it is just a 32-bit big endian integer that represents the number of buckets inside the hash table, exactly like you stored in your HashTable. - an array of
bucket_recrecords: this region contains one record for each bucket in the hash table. Abucket_recrecord is 8 bytes long, and it consists of two four-byte fields. The chain len field is a four byte integer that tells you the number of elements in the bucket's chain. (This number might be zero if there are no elements in that chain!) Thebucket positionfield is a four byte integer tells you the offset of the bucket data (i.e., the chain of bucket elements) within the index file. The offset is just like a pointer in memory, or an index of an array, except it points within the index file. So, for example, an offset of 0 would indicate the first byte of the file, an offset of 10 would indicate the 11th byte of the file, and so on. - an array of buckets: this region contains one bucket
for each bucket in the hash table. A bucket is slightly more
complex; it is a little embedded data structure.
Specifically, each bucket contains:
- an array of element positions: since elements are variable-sized, rather than fixed-sized, we need to know where each element of the bucket lives inside the bucket. For each element, we store a four-byte integer containing the position (i.e., offset) of the element within the index file.
- an array of elements: at each position specified in the element positions array lives an element. Since this is the docid-to-filename hash table, an element contains a 64-bit document ID and a filename. The document ID is an unsigned, big endian integer. Next, we store a 16-bit (2 byte) signed, big endian integer that contains the number of characters in the file name. Finally, we store the filename characters (each character is a single ASCII byte). Note that we do NOT store a null-terminator at the end of the filename; since we have the filename length in an earlier field, we don't need it!
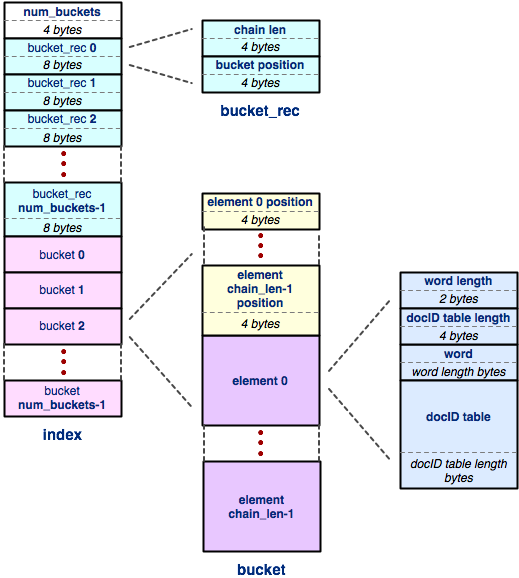
Index: The index is the most complicated of the three regions within the index file. The great news is that it has pretty much the same structure as the doctable: it is just a hash table, laid out exactly the same way. The only part of the index that differs from the doctable is the structure of each element. Let's focus on that.
An index maps from a word to an embedded docID hash table, or docID table. So, each element of the index contains enough information to store all of that. Specifically, an index table element contains:
- a two-byte signed integer that specifies the number of characters in the word.
- a four-byte signed integer that specifies the number of bytes in the embedded docID table.
- an array of ASCII characters that represents the word; as before, we don't store a NULL terminator at the end.
- finally, the element contains some variable number of bytes that represents the docID table. So, all we need to understand now is the format of the docID table. We're sure it's format will come as no surprise at this point...
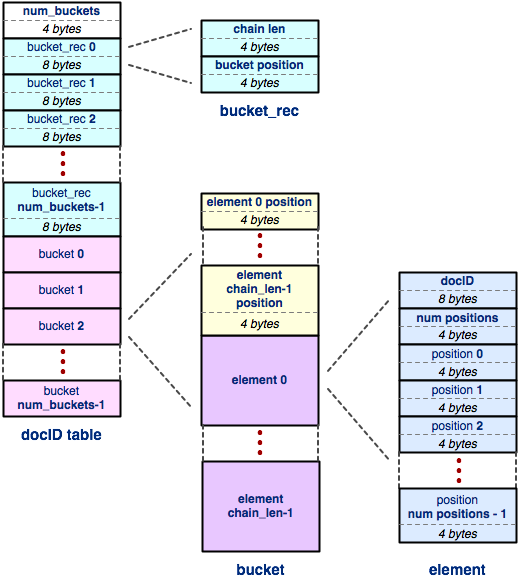
docIDtable: like the "doctable" table,
each embedded "docIDtable" table within the index is just
a hash table! A docIDtable maps from a 64-bit
docID to a list of positions with that document that the
word can be found in. So, each element of the docID table
stores exactly that:
- a 64-bit (8-byte) unsigned integer that represents the docID.
- a 32-bit (4-byte) signed integer that indicates the number of word positions stored in this element.
- an array of 32-bit (4-byte) signed integers, sorted in ascending order, each one containing a position within the docID that the word appears in.
So, putting it all together, the entire index file contains a header, a doctable (a hash table that maps from docID to filename), and an index. The index is a hash table that maps from a word to an embedded docIDtable. The docIDtable is a hash table that maps from a document ID to a list of word positions within that document.
Instructions
The bulk of the work in this homework is in this step. We'll tackle it in parts.
- Change to the directory containing your CSE333 GitLab
repository. Use
git pullto retrieve the newhw3/folder for this assignment. You still will need thehw1/,hw2/, andprojdocsdirectories in the same folder as your newhw3folder sincehw3/links to files in those previous directories. - Look around inside of
hw3/to familiarize yourself with the structure. Note that there is alibhw1/directory that contains a symlink to yourlibhw1.a, and alibhw2/directory that contains a symlink to yourlibhw2.a. You can replace your libraries with ours (from the appropriatesolution_binariesdirectories) if you prefer. - Next, run
maketo compile the three HW3 binaries. One of them is the usual unit test binary. Run it, and you'll see the unit tests fail, crash out, and you won't yet earn the automated grading points tallied by the test suite. - Now, take a look inside
Utils.handLayoutStructs.h. These header files contains some useful utility routines and classes you'll take advantage of in the rest of the assignment. We've provided the full implementation ofUtils.cc. Next, look insideWriteIndex.h; this header file declares theWriteIndex()function, which you will be implementing in this part of the assignment. Also, look insidebuildfileindex.cc; this file makes use ofWriteIndex()and your HW2CrawlFileTree(), to crawl a file subtree and write the resulting index out into an index file. Try running thesolution_binaries/buildfileindexprogram to build one or two index files for a directory subtree, and then run thesolution_binaries/filesearchshellprogram to try out the generated index file. - Finally, it's time to get to work! Open up
WriteIndex.ccand take a look around inside. It looks complex, but all of the helper routines and major functions correspond pretty directly to our walkthrough of the data structures above. Start by reading throughWriteIndex(); we've given you part of its implementation. Then, start recursively descending through all the functions it calls, and implement the missing pieces. (Look forSTEP:in the text to find what you need to implement.) - Once you think you have the writer working, compile and run
the
test_suiteas a first step. Next, use yourbuildfileindexbinary to produce an index file (we suggest indexing something small, like../projdocs/test_tree/tinyas a good test case). After that, use thesolution_binaries/filesearchshellprogram that we provide, passing it the name of the index file that yourbuildfileindexproduces, to see if it's able to successfully parse the file and issue queries against it. If not, you need to fix some bugs before you move on![Aside: If you write the index files to your personal directories on a CSE lab machine or on attu, you may find that the program runs very slowly. That's because home directories on those machines on a network file server, and
buildfileindexdoes a huge number of small write operations, which can be quite slow over the network. To speed things up dramatically we suggest you write the index files into/tmp, which is a directory on a local disk attached to each machine. Be sure to remove the files when you're done so the disk doesn't fill up.] -
As an even more rigorous test, try running the
hw3fsckprogram we've provided insolution_binariesagainst the index that you've produced.hw3fsckscans through the entire index, checking every field inside the file for reasonableness. It tries to print out a helpful message if it spots some kind of problem.Once you pass
hw3fsckand once you're able to issue queries against your file indices, then rerun yourbuildfileindexprogram under valgrind and make sure that you don't have any memory leaks or memory errors.Congrats, you've passed part A of the assignment!
Part B: Index Lookup
Now that you have a working memory-to-file index writer, the next step is to implement code that knows how to read an index file and lookup query words and docids against it. We've given you the scaffolding of the implementation that does this, and you'll be finishing our implementation.
Instructions
- Start by looking inside
FileIndexReader.h. Notice that we're now in full-blown C++ land; you'll be implementing constructors, manipulating member variables and functions, and so on. Next, open upFileIndexReader.cc. Your job is to finish the implementation of its constructor, which reads the header of the index file and stores various fields as private member variables. As above, look for"STEP:"to figure out what you need to implement. When you're done, recompile and re-run the test suite. You should pass all the tests fortest_fileindex_reader.cconce you have implementedFileIndexReadersuccessfully. - Next, move on to
HashTableReader.h. Read through it to see what the class does. Don't worry about the copy constructor and assignment operator details (though if you're curious, read through them to see what they're doing and why). This class serves as a base class for other subclasses. The job of aHashTableReaderis to provide most of the generic hash-table lookup functionality; it knows how to look through buckets and chains, returning offsets to elements associated with a hash value. Open upHashTableReader.cc. Implement the"STEP:"components in the constructor and theLookupElementPositionsfunction. When you're done, recompile and run the unit tests to see if you passtest_hashtablereader.ccunit test. - Now it's time to move on to
DocTableReader.h. Read through it, and note that it is a subclass ofHashTableReader. It inheritsLookupElementPositions()and other aspects, but provides some new functionality. Next, open upDocTableReader.cc,and implement the"STEP:"functionality. See how well you do on its unit test (and valgrind) when you're done. - Next, lets move on to
IndexTableReader.h. Read through it and understand its role. Next, open upIndexTableReader.ccand implement the"STEP:"functionality. Test against the unit tests (and valgrind). - Next, do the same with
DocIDTableReader.handDocIDTableReader.cc. - We're almost there! Open up
QueryProcessor.hand understand how it is supposed to work. Check outtest_queryprocessor.ccfor more information. Now open upQueryProcessor.ccand read through our implementation of the constructor and destructor.This part of the assignment is the most open-ended. We've given you the function definition for
ProcessQuery(), and also a clue about what you should be building up and returning. But, we've given you nothing about its implementation. You get to implement it entirely on your own; you might want to define helper private member functions, you might want to define other structures to help along the way, etc.; it's entirely up to you. But, once you're finished, you'll need to pass our unit test to know you've done it correctly.As a hint, you should be able to take inspiration from what you did to implement the query processor in HW2. Here, it's only a little bit more complicated. You want to process the query against each index, and then intersect each index's results together and do a final sort (use the STL's
sort). Remember that processing a query against an index means ensuring all query words are present in each matching document, and remember how ranking works. Then, once you have query results from each index, you'll append them all together to form your final query results.One more hint, once you think you have this working, move on to Part C and finish our
filesearchshellimplementation. You'll be able to test the output of yourfilesearchshellagainst ours (insolution_binaries/) as a final sanity check.Also, now would be a great time to run valgrind over the unit tests to verify you have no memory leaks or memory errors.
You're done with part B!
Part C: Search Shell
For Part C, your job is to implement a search shell, just like in HW2, but this time using your HW3 infrastructure you completed parts A and B.
- Open up
filesearchshell.ccand read through it. Note that unlike parts A and B, we have given you almost nothing about the implementation of thefilesearchshellbesides a really long (and hopefully helpful) comment. Implementfilesearchshell.cc. - Try using your
filesearchshellbinary. You can compare the output of your binary against a transcript of our solution. The transcripts should match precisely, except perhaps for the order of equally ranked matches. You can also walk yourfilesearchshellagainst a very tiny index --tiny.idx-- in the debugger to see if it's reading the correct fields and jumping to the correct offsets. - Also, note that you can hit control-D to exit the
filesearchshell.filesearchshellought to clean up all allocated memory before exiting. So, run yourfilesearchshellunder valgrind to ensure there are no leaks or errors.
Congrats, you're done with (the mandatory parts) of HW3!!
Testing
As with previous homeworks, you compile your implementation
using the make command. This will result in several
output files, including an executable called
test_suite. You can run all of the tests in that
suite with the command:
bash$ ./test_suite
You can also run only specific tests by passing command line
arguments into test_suite. For example, to only
run the FileParser tests, you can type:
bash$ ./test_suite --gtest_filter=Test_QueryProcessor.*
If you only want to test ReadFileToString from
FileParser, you can type:
bash$ ./test_suite --gtest_filter=Test_FileParser.ReadFileToString
To test only a single index for QueryProcessor, you
can use:
bash$ ./test_suite --gtest_filter=Test_QueryProcessor.TestQueryProcessorSingleIndex
In general, you can specify which tests are run for any of the tests in the assignment; you just need to know the names of the tests, which can be obtained by running:
bash$ ./test_suite --gtest_list_tests
You can also run test_suite and specify particular
tests that should NOT be run. For instance, the
WriteIndex tests can take a while to run; to run all
tests expect for those, enter
bash$ ./test_suite --gtest_filter=-Test_WriteIndex.*
These settings can be helpful for debugging specific parts of the
assignment, especially since test_suite can be run
with these settings through valgrind and
gdb! However, you should not debug your code using
only the supplied tests! The test setup and code are complex
enough that it can be hard to isolate problems effectively
without spending excessive amounts of time trying to
reverse-engineer the details of the test_suite code.
A very effective testing technique is to create some small test
cases with a few directories and a handful of short files, where
you can draw out on paper the expected data structures and the
expected disk file contents when those data structures are written
to disk. Then, you can use programs like hexdump and
others to examine the created index files in detail, to verify if
everything looks correct. (Tools for examining and debugging disk
files will be covered further in sections.)
Code Quality
In addition to passing tests, your code should be high quality and readable. This includes several aspects:
- Modularity: Your code should be divided into
reasonable modules (e.g., functions) and should not have
excessive redundancies that could be removed by
replacing redundant code with calls to suitable, possibly new,
functions. If you create any additional private (e.g.,
static) helper functions, be sure to provide good comments that explain the function inputs, outputs, and behavior. These comments can often be relatively brief as long as they convey to the reader the information needed to understand how to use the function and what it does when executed. - Readability: Your code should blend smoothly with the code surrounding it. Follow the existing conventions in the code for capitalization; naming of functions, variables, and other items; using comments to document aspects of the code; and layout conventions such as indenting and spacing.
- Automated bug checking: Use the provided tools
(
cpplint.pyandValgrind) to look for common coding bugs and fix reported issues before submitting your code. Exception: ifcpplintreports style problems in the supplied starter code, you should leave that code as-is. - Style guide: Refer to the Google C++ Style Guide for advice.
- Good development practices: We will look through your git activity (eg, tags and commits) to verify that you are following the development practices described in class. This may include correct tagnames, succinct commit messages, and incremental checkins (eg, commiting after a major milestone like passing a test or implementing a feature).
Project Submission & Evaluation
Project Submission
When you are ready to turn in your assignment, you should follow
the same procedures you used for previous homeworks, except this
time tag the repository with hw3-final. Remember to
clean up, commit, and push all necessary files to your repository
before you add the tag. After you have created and pushed the
tag, remember to
test everything in the CSE Linux environment
by creating a new clone of the repository in a separate, empty
directory, checking out the hw3-final tag, and
verifying that everything works as expected. Refer to the
hw0 turnin instructions
for details, and follow those steps carefully.
When you clone your repository to check it, it normally will not
include hw1/libhw1.a and hw1/libhw2.a,
which are needed to build hw3. Either run "make" in each of the
hw1 and hw2 directories to recreate them using your solutions,
or copy the two libhwX.a files out of their
hwX/solution_binaries directories into the main
hwX directories to use the sample solution version of that
library.
It is YOUR responsibility to check your work. If your project doesn't build properly when the course staff does these exact steps to grade it, you may lose a huge amount of the possible credit ... even if almost absolutely everything is correct.
Grading
We will be basing your grade on several elements:
- The degree to which your code passes the unit tests
contained in
test_suite.cc. If your code fails a test, we won't attempt to understand why: we're planning on just including the number of points that the test drivers print out. - We have some additional unit tests that test a few additional cases that aren't in the supplied test drivers. We'll be checking to see if your code passes these as well.
- The quality and readability of your code. We'll be judging this on several qualitative aspects described above.
Remember: Both code correctness and code quality matter. Both are weighed significantly in the evaluation of your project.