CSE 333 Homework 1
Out: Wednesday, October 4, 2023
Due: Friday, October 13, 2023 by 10:00 pm PDT
Goals
For Homework 1, you will complete our implementation of two C data structures: a doubly-linked list (Part A) and a chained hash table (Part B).
malloc/free puzzles, and these can cause
awful bugs that take time and patience to find and fix.
C Data Structures
Part A: Doubly-Linked List
If you've programmed in Java, you're used to having a fairly rich library of elemental data structures upon which you can build, such as vectors and hash tables. In C, you don't have that luxury: the C standard library provides you with very little. In this assignment, you will add missing pieces of code in our implementation of a generic doubly-linked list.
At a high-level, a doubly-linked list looks like this:

Each node in a doubly-linked list has three fields: a payload, a
pointer to the previous element in the list (or NULL
if there is no previous element), and a pointer to the next element
in the list.
If the list is empty, there are no nodes.
If the list has a single element, both of its next and previous
pointers are NULL.
So, what makes implementing this in C tricky? Quite a few things:
- We want to make the list useful for storing arbitrary kinds of payloads. In practice, this means the payload element in a list node needs to be a pointer supplied by the customer of the list implementation. Given that the pointer might point to something malloc'ed by the customer, this means we might need to help the customer free the payload when the list is destroyed.
- We want to hide details about the implementation of the list by exposing a high-level, nicely abstracted API. In particular, we don't want our customers to fiddle with next and previous pointers in order to navigate through the list, and we don't want our customers to have to stitch up pointers in order to add or remove elements from the list. Instead, we'll offer our customers nice functions for adding and removing elements and a Java-like iterator abstraction for navigating through the list.
- C is not a garbage-collected language: you're responsible for managing memory allocation and deallocation yourself. This means we need to be malloc'ing structures when we add nodes to a list, and we need to be free'ing structures when we remove nodes from a list. We also might need to malloc and free structures that represent the overall list itself.
Given all of these complications, our actual linked list data structure ends up looking like this:
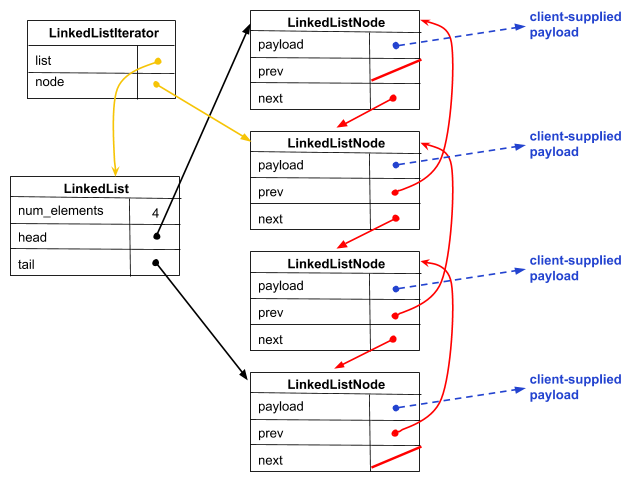
Specifically, we define the following types and structures:
- LinkedList: The structure containing our linked list's metadata, such as head and tail pointers. When our customer asks us to allocate a new, empty linked list, we malloc and initialize an instance of this structure then return a pointer to that malloc'ed structure to the customer.
- LinkedListNode: this structure represents
a node in a doubly-linked list.
It contains a field for stashing away (a pointer to) the
customer-supplied payload and fields pointing to the previous and
next LinkedListNode in the list.
When a customer requests that we add an element to the linked
list, we malloc a new LinkedListNode to store the pointer to
that element, do surgery to splice the
LinkedListNodeinto the data structure, and update ourLinkedList's metadata. - LLIterator: sometimes customers want to
navigate through a linked list; to help them do that, we provide
them with an iterator.
LLIteratorcontains bookkeeping associated with an iterator. In particular, it tracks the list that the iterator is associated with and the node in the list that the iterator currently points to. Note that there is a consistency problem here: if a customer updates a linked list by removing a node, it's possible that some existing iterator becomes inconsistent because it referenced the deleted node. So, we make our customers promise that they will free any live iterators before mutating the linked list. (Since we are generous, we do allow a customer to keep an iterator if the mutation was done using that iterator.) When a customer asks for a new iterator, we malloc an instance and return a pointer to it to the customer.
Part A Instructions
You should follow these steps to do this part of the assignment:
- Make sure you are comfortable with C pointers, structures, malloc, and free. We will cover them in detail in lecture, but you might need to brush up and practice a bit on your own; you should have no problem Googling for practice programming exercises on the Web for each of these topics.
- Get the source files for hw1: navigate to a
directory that contains a checked-out copy of your cse333 git
repository and run the command
git pull. (See GitHub Docs if thepullcommand fails because you have unstaged changes or other problems.) After thepullcommand finishes you should see at least the following directories and files in your repository:$ ls cpplint.py exercises gtest hw0 hw1
- Look inside the
hw1directory. You'll see a number of files and subdirectories, including these that are relevant to Part A:- Makefile: a Makefile you can use to
compile the assignment using the Linux command
makeon the CSE Linux machines. - LinkedList.h: a header file that defines and documents the API of the linked list. A customer of the linked list includes this header file and uses the functions defined within in. Read through this header file very carefully to understand how the linked list is expected to behave.
- LinkedList_priv.h: a private
header file included by
LinkedList.c; it defines the structures we diagrammed above. These implementation details would typically be withheld from the client by placing the contents of this header directly inLinkedList.c; however, we have opted to place them in a "private .h" instead so that our unit test code can verify the correctness of the linked list's internals. - LinkedList.c: Contains the
partially-completed implementation of our doubly-linked list.
Your task will be to finish the implementation; see the
labels that say "STEP X:".
Take a minute and read through both
LinkedList_priv.handLinkedList.c. - example_program_ll.c: this is a simple example of how a customer might use the linked list; in it, you can see how a customer can allocate a linked list, add elements to it, create an iterator, use the iterator to navigate a bit, and then clean up.
- test_linkedlist.cc: this file contains unit tests that we wrote to verify that the linked list implementation works correctly. The unit tests are written to use the Google Test unittesting framework, which has similarities to Java's JUnit testing framework. As well, this test driver will assist the course staff in grading your assignment. As you add more pieces to the implementation, the test driver will make it further through the unit tests, and it will print out a cumulative score along the way. You don't need to understand what's in the test driver for this assignment, though if you peek inside it, you might get hints for what kinds of things you should be doing in your implementation!
- solution_binaries: in this directory,
you'll find some Linux executables, including
example_program_llandtest_suite. These binaries were compiled with a complete, working version ofLinkedList.c; you can run them to explore what should be displayed when your assignment is working!
- Makefile: a Makefile you can use to
compile the assignment using the Linux command
- Run
makeon a CSE Linux machine to verify that you can build your own versions ofexample_program_llandtest_suite.makeshould print out a few things, and you should end up with new binaries inside the hw1 directory. - Since you haven't yet finished the
implementation of
LinkedList.c, the binaries you just compiled won't work correctly yet. Try running them, and note thatexample_program_llhalts with an assertion error or a segfault andtest_suiteprints out some information indicating failed tests, and may crash before terminating. - This is the hard step: finish the implementation
of
LinkedList.c. Go throughLinkedList.c, find each comment that says "STEP X", and place working code there (please keep the "STEP X" comment for your graders' sanity so they can locate your code!). The initial steps are meant to be relatively straightforward, and some of the later steps are trickier. You will probably find it helpful to read through the code from top to bottom to figure out what's going on. You will also probably find it helpful to recompile frequently to see what compilation errors you've introduced and need to fix. When compilation works again, try running the test driver to see if you're closer to being finished.- Note: You may not modify any
header files or interfaces in this or later project
assignments.
We may test your code by extracting your implementations and
compiling them with the original header files or in some
other test harness where they are expected to behave as
specified.
You are certainly free, of course, to add additional private
(e.g.,
static– more info here) helper functions in your implementation, and you should do that when it improves modularity. - Debugging hint:
Verify333is used in many places in the code to check for errors and terminate execution if something is wrong. You might find it helpful to discover the function that is called when this happens so you can place a debugger breakpoint there.
- Note: You may not modify any
header files or interfaces in this or later project
assignments.
We may test your code by extracting your implementations and
compiling them with the original header files or in some
other test harness where they are expected to behave as
specified.
You are certainly free, of course, to add additional private
(e.g.,
- We'll also be testing whether your program has
any memory issues using Valgrind.
To try out Valgrind on the solution binaries:
- From the
hw1directory run the following command:$ valgrind --leak-check=full ./solution_binaries/example_program_ll
Note that we are runnning this on the solution binaries, so Valgrind prints out that no memory issues were found. Similarly, try running the solution test driver under Valgrind:$ valgrind --leak-check=full ./solution_binaries/test_suite
and note that Valgrind again indicates that no memory issues were found. - To test your implementation, compile your
versions of the
example_program_llandtest_suitebinaries while in thehw1directory and run them under Valgrind. For example:$ valgrind --leak-check=full ./test_suite
If you have no memory issues and thetest_suiteruns the linked list tests to completion, you're done with Part A!
- From the
Part B: Chained Hash Table
A chained hash table is a data structure that consists of an array of buckets, with each bucket containing a linked list of elements. When a user inserts a key/value pair into the hash table, the hash table uses a hash function to map the key into one of the buckets, and then adds the key/value pair onto the linked list. There is an important corner case: if the key of the inserted key/value pair already exists in the hash table; our implementation of a hash table replaces the existing key/value pair with the new one and returns the old key/value pair to the customer.
Over time, as more and more elements are added to the hash table, the linked lists hanging off of each bucket will start to grow. As long as the number of elements in the hash table is a small multiple of the number of buckets, lookup time is fast: you hash the key to find the bucket, then iterate through the (short) chain (linked list) hanging off the bucket until you find the key. As the number of elements gets larger, lookups become less efficient, so our hash table includes logic to resize itself by increasing the number of buckets to maintain short chains.
As with the linked list in Part A, we've given you a partial implementation of a hash table. Our hash table implementation looks approximately like this:
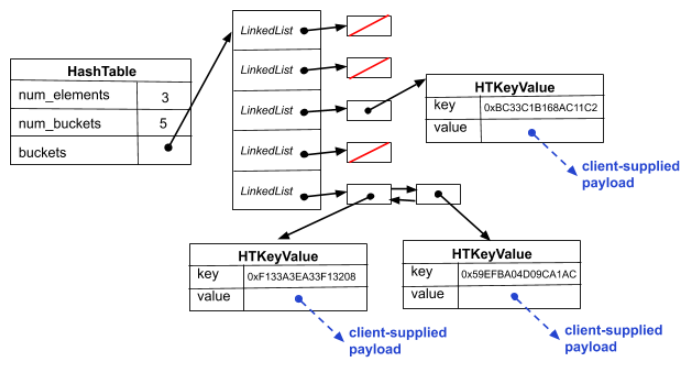
Specifically, we defined the following types and structures:
- HashTable: The structure containing our hash table's
metadata, such as the number of elements and the bucket array.
When our customer asks us to allocate a new, empty hash table,
we malloc and initialize an instance of this (including
malloc'ing space for the bucket array that it uses and allocating
LinkedListsfor each bucket), and return a pointer to that malloc'ed structure to the customer. - HTIterator (not shown in the diagram):
sometimes customers want to iterate through all elements in a
hash table; to help them do that, we provide them with an
iterator.
HTIteratorpoints to a structure that contains bookkeeping associated with an iterator. Similar to a linked list iterator, the hash table iterator keeps track of the hash table the iterator is associated with and in addition has a linked list iterator for iterating through the bucket linked lists. When a customer asks for a new iterator we malloc anHTIteratorand return a pointer to it.
Part B Instructions
You should follow these steps to do this part of the assignment:
- The code you fetched in Part A also contains the files you'll
need to complete your hash table implementation and test it.
Similar to the linked list, the hash table implementation is
split across a few files:
HashTable.ccontains the implementation you need to finish,HashTable.hcontains the public interface to the hash table and documents all of the functions & structures that customers see, andHashTable_priv.hcontains some private, internal structures thatHashTable.cuses. - Read through
HashTable.hfirst to get a sense of what the hash table interface semantics are. Then, take a look atexample_program_ht.c; this is a program that uses the hash table interface to insert/lookup/remove elements from a hash table, and uses the iterator interface to iterate through the elements of the hash table. - As before,
test_hashtable.cccontains our Google Test unit tests for the hash table. Run this — on its own, and using valgrind — to seer how close you are to finishing your hash table implementation. - Look through
HashTable.c, find all of the missing pieces (identified by "STEP X" comments, as before), and implement them. - As before, in
solution_binaries, we've provided linux executables (i.e.,example_program_htand the sametest_suite) that were compiled with our complete, working version ofHashTable.c. You can run them to explore what should be displayed when your Part B implementation is working and look at the source code for examples of how to use the data structures.
Bonus: Code Coverage Statistics
You'll notice that we provided a second Makefile called
Makefile.coverage.
You can use it to invoke the gcov code coverage
generation tool.
Figure out how to (a) use it to generate code coverage statistics
for LinkedList.c and HashTable.c, (b)
note that the code coverage for HashTable is worse than that for
the LinkedList, and (c) write additional HashTable unit tests to
improve HashTable's code coverage.
If you do work on bonus task, you must also include a
hw1-bonus tag in your repository.
While grading, we will use whichever commit has that tag to examine
the bonus, so it may be the same or a different commit from the one
that has hw1-final.
The hw1-final tagged commit must also still work
properly (i.e., pass all tests, no memory issues, etc.).
If you do not have a hw1-bonus tag in your repository,
we will assume you did not choose to submit anything for the bonus
(which will not affect your grade in any way!).
The bonus task is simple, but we're deliberately providing next to no detailed instructions on how to do it — figuring out how is part of the bonus task!
Please make sure your additional unit tests don't change the scoring mechanism that we use, obviously (we'll be checking that). Place your additional unit tests in a separate file from the original test suite. That will make it easier for us to find and evaluate your tests.
Testing
As with hw0, you can compile your implementation by using the
make command.
This will result in several output files, including an executable
called test_suite.
After compiling your solution with make, you can run
all of the tests for the homework by running:
$ ./test_suite
You can also run only specific tests by passing command-line
arguments into test_suite.
This is extremely helpful for debugging specific parts of the
assignment, especially since test_suite can be run
with these settings through valgrind and
gdb!
Some examples:
- To only run the
LinkedListtests, enter:$ ./test_suite --gtest_filter=Test_LinkedList.*
- To only test
PushandPopfromLinkedList, enter:$ ./test_suite --gtest_filter=Test_LinkedList.PushPop
You can specify which tests are run for any of the tests in the assignment — you just need to know the names of the tests! You can list them all out by running:
$ ./test_suite --gtest_list_tests