CSE 333 Homework 3
Out: Friday, July 23, 2022
Due: Thursday, August 5, 2022 by 11:59 pm
Goals
In this assignment, you will build on top of your Homework 2 implementation and move the inverted index to an on-disk index:
- In Part A, you will write code that takes an in-memory inverted index produced by HW2 and writes it out to disk in an architecture-neutral format.
- In Part B, you will write C++ code that walks through an on-disk index to service a lookup.
- In Part C, you will write a query processor that serves queries from multiple on-disk indices.
- While you do these parts, you are expected to fill in a bug
journal which can be found in
bug_journal.md.
As before, please read through this entire document before beginning the assignment, and please start early! As usual, there is a lot of code involved with HW3, and since this is your first serious attempt to use C++ you should expect to encounter a lot of problems along the way. Also, manipulating on-disk data is trickier than in-memory data structures, so plan for some time to get this part right.
Disk-Based File System Search Engine
General Implementation Notes
- We will not be using C++ exceptions in HW3.
- As before, you may not modify any of the existing header files or class definitions distributed with the code. If you wish to add extra "helper" functions you can to do that by including additional static functions in the implementation (.cc) files.
- As with HW2, you don't need to worry about propagating errors
back to callers in all situations.
You will use Verify333()'s to spot errors and cause your program
to crash out if they occur.
Be sure to only use
Verify333()if the function doesn't specify what it will do on error.
Starter Videos
The following videos are intended to help you double-check your understanding of the index file format used in HW3 as well as demonstrate the debugging process. It is recommended that you watch these AFTER reading through the specs.
Note: You can click on the labeled timestamps in the "Contents" menu to jump between sections of the video.
Part A: MemIndex and DocTable convert to Index File
Keeping a search engine index in memory is problematic, since memory is expensive and also volatile. So, in Part A, you're going to write some C++ code that takes advantage of your HW2 implementation to first build an in-memory index of a file subtree, and then it will write that index into an index file in an architecture-neutral format.
What do we mean by architecture-neutral? Every time we need to store an integer in the file's data structure, we will store it in big endian representation. This is the representation that is conventionally used for portability, but the bad news is that this is the opposite representation than most computers you use: x86 computers are little endian. So, you will need to convert integers (whether 16-bit, 32-bit, or 64-bit) into big endian before writing them into the file. We provide you with helper functions to do this.
The good news is that we're going to keep roughly the same data structure inside the file as you built up in memory: we'll have chained hash tables that are arrays of buckets containing linked lists. And, our inverted index will be a hash table containing a bunch of embedded hash tables. But, we need to be very precise about the specific layout of these data structures within the file. So, let's first walk through our specification of an index file's format. We'll do this first at a high level of abstraction, showing the major components within the index file. Then, we'll zoom into these components, showing additional details about each.
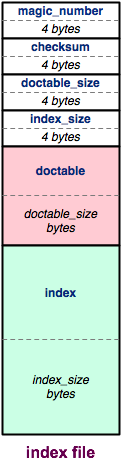
At a high-level, the index file looks like the figure on the right. The index file is split into three major pieces: a header, the doctable, and the index. We'll talk about each in turn.
Header
An index file's header contains metadata about the rest of the index file:
- The first four bytes of the header are a
magic number,
or format indicator.
Specifically, we use the 32-bit number
0xCAFEF00D. We will always write the magic number out as the last step in preparing an index file. This way, if the program crashes partway through writing one, the magic number will be missing, and it will be easy to tell that the index file is corrupt. - The next four bytes are a checksum of the doctable and index regions of the file. A checksum is a mathematical signature of a bunch of data, kind of like a hash value. By including a checksum of most of the index file within the header, we can tell if the index file has been corrupted, such as by a disk error. If the checksum stored in the header doesn't match what we recalculate when opening an index file, we know the file is corrupt and we can discard it.
- The next four bytes store the size of the doctable region of the file. The size is stored as a 32-bit, signed, big endian integer.
- The final four bytes of the header store the size of the index region of the file, in exactly the same way.
Doctable
Let's drill down into the next level of detail by examining the
content of the doctable region of the file.
The doctable is a hash table that stores a mapping from 64-bit
document ID to an ASCII string representing the document's
filename.
This is the docid_to_docname HashTable that you built
up in HW2, but but stored in the file rather than in memory.
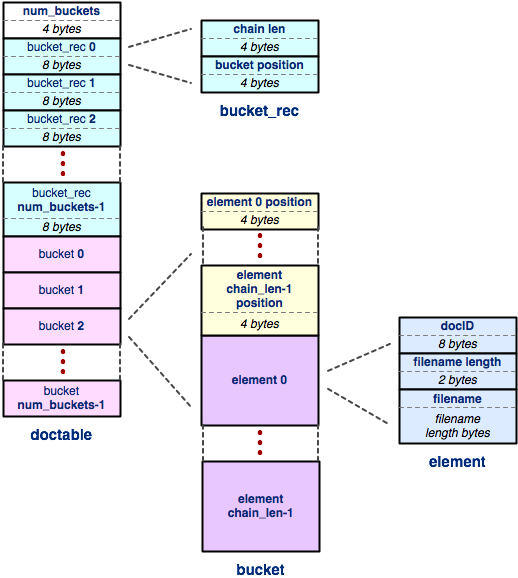
The doctable consists of three regions; let's walk through them, and then drill down into some details:
num_buckets: This region is the simplest; it is just a 32-bit big endian integer that represents the number of buckets inside the hash table, exactly like you stored in your HashTable.- An array of
bucket_recrecords: This region contains one record for each bucket in the hash table. Abucket_recrecord is 8 bytes long, and it consists of two four-byte fields. The chain len field is a four byte integer that tells you the number of elements in the bucket's chain. (This number might be zero if there are no elements in that chain!) Thebucket positionfield is a four-byte integer that tells you the offset of the bucket data (i.e., the chain of bucket elements) within the index file. The offset is just like a pointer in memory or an index of an array, except that it points within the index file. For example, an offset of 0 would indicate the first byte of the file, an offset of 10 would indicate the 11th byte of the file, and so on. - An array of buckets: This region
contains one bucket for each bucket in the hash table.
A bucket is slightly more complex; it is a little embedded data
structure.
Specifically, each bucket contains:
- An array of element positions: Since elements are variable-sized, rather than fixed-sized, we need to know where each element of the bucket lives inside the bucket. For each element, we store a four-byte integer containing the position (i.e., offset) of the element within the index file.
- An array of elements: At each position specified in the element positions array lives an element. Since this is the docid-to-filename hash table, an element contains a 64-bit document ID and a filename. The document ID is an unsigned, big endian integer. Next, we store a 16-bit (2-byte) signed, big endian integer that contains the number of characters in the file name. Finally, we store the filename characters (each character is a single ASCII byte). Note that we do NOT store a null-terminator at the end of the filename; since we have the filename length in an earlier field, we don't need it!
Index
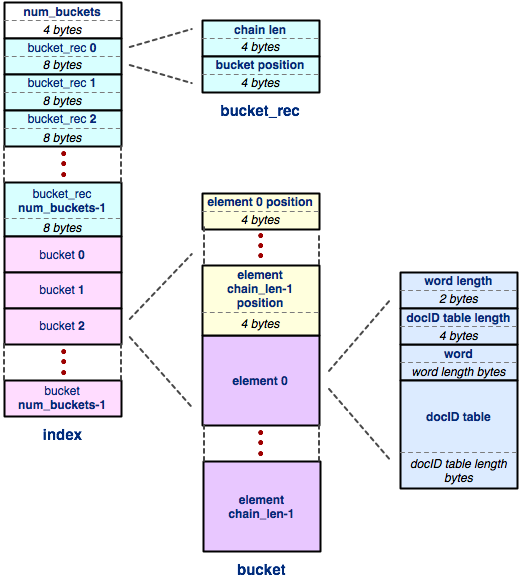
The index is the most complicated of the three regions within the index file. The great news is that it has pretty much the same structure as the doctable: it is just a hash table, laid out exactly the same way. The only part of the index that differs from the doctable is the structure of each element, so let's focus on that.
An index maps from a word to an embedded docID hash table, or docID table. So, each element of the index contains enough information to store all of that. Specifically, an index table element contains:
- A two-byte signed integer that specifies the number of characters in the word.
- A four-byte signed integer that specifies the number of bytes in the embedded docID table.
- An array of ASCII characters that represents the word; as before, we don't store a NULL terminator at the end.
- Some variable number of bytes that represents the docID table.
So, all we need to understand now is the format of the docID table. We're sure its format will come as no surprise at this point...
docIDtable
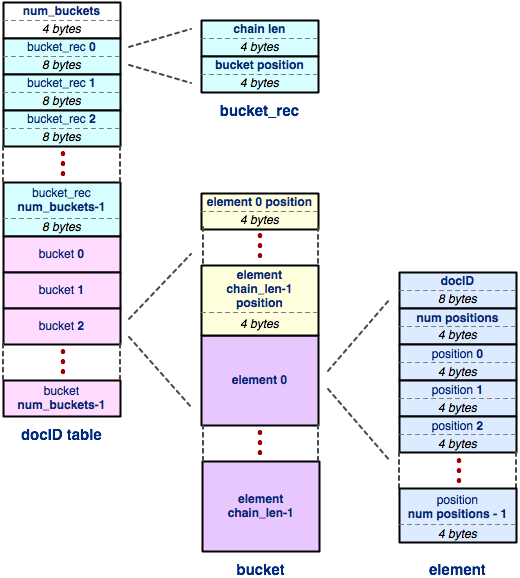
Like the "doctable" table, each embedded "docIDtable" table within
the index is just a hash table!
A docIDtable maps from a 64-bit docID to a list of
positions with that document that the word can be found in.
So, each element of the docID table stores exactly that:
- A 64-bit (8-byte) unsigned integer that represents the docID.
- A 32-bit (4-byte) signed integer that indicates the number of word positions stored in this element.
- An array of 32-bit (4-byte) signed integers, sorted in ascending order, each one containing a position within the docID that the word appears in.
So, putting it all together, the entire index file contains a header, a doctable (a hash table that maps from docID to filename), and an index. The index is a hash table that maps from a word to an embedded docIDtable. The docIDtable is a hash table that maps from a document ID to a list of word positions within that document.
Part A Instructions
The bulk of the work in this homework is in this step. We'll tackle it in parts.
- Change to the directory containing your CSE333 GitLab
repository.
Use
git pullto retrieve the newhw3/folder for this assignment. You still will need thehw1/,hw2/, andprojdocsdirectories in the same folder as your newhw3folder sincehw3/links to files in those previous directories, and thetest_treefolder also still needs to be present. - Look around inside of
hw3/to familiarize yourself with the structure. Note that there is alibhw1/directory that contains a symlink to yourlibhw1.a, and alibhw2/directory that contains a symlink to yourlibhw2.a. You can replace your libraries with ours (from the appropriatesolution_binariesdirectories) if you prefer. - Next, run
maketo compile the three HW3 binaries. One of them is the usual unit test binary. Run it, and you'll see the unit tests fail, crash out, and you won't yet earn the automated grading points tallied by the test suite. - Now, take a look inside
public/Utils.handpublic/LayoutStructs.h. These header files contains some useful utility routines and classes you'll take advantage of in the rest of the assignment. We've provided the full implementation ofprivate/Utils.cc. Next, look insidepublic/WriteIndexFile.h; this header file declares theWriteIndexFile()function, which you will be implementing in this part of the assignment. Also, look insidebuildfileindex.cc; this file makes use ofWriteIndexFile()and your HW2CrawlFileTree(), to crawl a file subtree and write the resulting index out into an index file. Try running thesolution_binaries/buildfileindexprogram to build one or two index files for a directory subtree, and then run thesolution_binaries/filesearchshellprogram to try out the generated index file. - Finally, it's time to get to work!
The first part of the project is writing your index in memory and
putting it into a file. Open up
writer/WriteIndexFile.ccand notice that it calls some functions that have been included inwriter/WriteHashTable_priv.handwriter/WriterFunctions_priv.h, which their according.ccfiles have their definitions. It's good to notice here how we are able to factor out that we are just writing downHashTable's at the end of the day. To give some steps towards what should be implemented first:writer/WriteHashTable_priv.h: This file contains a template helper function to factor out the calls towards writing all types of structs in creating the index filewriter/WriteHashTable.cc: This file will be where you are generalizing how you would write aHashTablewithout considering what elements there arewriter/WriterFunctions.cc: This file will contain how to handle specific elements stored in aHashTablewriter/WriteIndexFile.cc: Now that you have the tools to create aHashTableinto memory with elements stored like in aDocTableandMemIndex, the last steps are to write them into one file and create a header for them!
There will be a future push around Saturday or Sunday in order to add tests to resolve in this order later.take a look around inside. It looks complex, but all of the helper routines and major functions correspond pretty directly to our walkthrough of the data structures above. Start by reading throughWriteIndexFile(); we've given you part of its implementation. Then, start recursively descending through all the functions it calls, and implement the missing pieces. (Look forSTEP:in the text to find what you need to implement.) - Once you think you have the writer working,
compile and run the
test_suiteas a first step. Next, use yourbuildfileindexbinary to produce an index file (we suggest indexing something small, like./test_tree/tinyas a good test case). After that, use thesolution_binaries/filesearchshellprogram that we provide, passing it the name of the index file that yourbuildfileindexproduces, to see if it's able to successfully parse the file and issue queries against it. If not, you need to fix some bugs before you move on!Aside: If you write the index files to your personal directories on a CSE lab machine or on attu, you may find that the program runs very slowly. That's because home directories on those machines on a network file server, andbuildfileindexdoes a huge number of small write operations, which can be quite slow over the network. To speed things up dramatically we suggest you write the index files into/tmp, which is a directory on a local disk attached to each machine. Be sure to remove the files when you're done so the disk doesn't fill up. - As an even more rigorous test, try running the
filesystem_checkerprogram we've provided insolution_binariesagainst the index that you've produced.filesystem_checkerscans through the entire index, checking every field inside the file for reasonableness. It tries to print out a helpful message if it spots some kind of problem. Once you passfilesystem_checkerand once you're able to issue queries against your file indices, then rerun yourbuildfileindexprogram under valgrind and make sure that you don't have any memory leaks or other memory errors.
Part B: Index Lookup
Now that you have a working memory-to-file index writer, the next step is to implement code that knows how to read an index file and lookup query words and docids against it. We've given you the scaffolding of the implementation that does this, and you'll be finishing our implementation.
Part B Instructions
- Start by looking inside
public/FileIndexReader.h. Notice that we're now in full-blown C++ land; you'll be implementing constructors, manipulating member variables and functions, and so on. Next, open upprivate/writers/FileIndexReader.cc. Your job is to finish the implementation of its constructor, which reads the header of the index file and stores various fields as private member variables. As above, look for"STEP:"to figure out what you need to implement. When you're done, recompile and re-run the test suite. You should pass all the tests fortests/test_fileindex_reader.cconce you have implementedFileIndexReadersuccessfully. - Next, move on to
public/readers/HashTableReader.h. Read through it to see what the class does. Don't worry about the copy constructor and assignment operator details (though if you're curious, read through them to see what they're doing and why). This class serves as a base class for other subclasses. The job of aHashTableReaderis to provide most of the generic hash-table lookup functionality; it knows how to look through buckets and chains, returning offsets to elements associated with a hash value. Open upprivate/readers/HashTableReader.cc. Implement the"STEP:"components in the constructor and theLookupElementPositionsfunction. When you're done, recompile and run the unit tests to see if you passtests/test_hashtablereader.ccunit test. - Now it's time to move on to
public/readers/DocTableReader.h. Read through it, and note that it is a subclass ofHashTableReader. It inheritsLookupElementPositions()and other aspects, but provides some new functionality. Next, open upprivate/readers/DocTableReader.cc,and implement the"STEP:"functionality. See how well you do on its unit test (and valgrind) when you're done. - Next, lets move on to
public/readers/IndexTableReader.h. Read through it and understand its role. Next, open upprivate/readers/IndexTableReader.ccand implement the"STEP:"functionality. Test against the unit tests (and valgrind). - Next, do the same with
public/readers/DocIDTableReader.handpublic/readers/DocIDTableReader.cc. - We're almost there!
Open up
public/QueryProcessor.hand read through how it is supposed to work. Check outtests/test_queryprocessor.ccfor more information. Now open upprivate/QueryProcessor.ccand read through our implementation of the constructor and destructor.This part of the assignment is the most open-ended. We've given you the function definition forProcessQuery(), and also a clue about what you should be building up and returning. But, we've given you nothing about its implementation. You get to implement it entirely on your own; you might want to define helper private member functions, you might want to define other structures to help along the way, etc.; it's entirely up to you. But, once you're finished, you'll need to pass our unit test to know you've done it correctly.- Hint #1: You should be able to take inspiration from what
you did to implement the query processor in HW2.
Here, it's only a little bit more complicated.
You want to process the query against each index, and then
intersect each index's results together and do a final sort
(use the STL's
sort). Remember that processing a query against an index means ensuring all query words are present in each matching document, and remember how ranking works. Then, once you have query results from each index, you'll append them all together to form your final query results. - Hint #2: Once you think you have this working, move on to
Part C and finish our
filesearchshellimplementation. You'll be able to test the output of yourfilesearchshellagainst ours (insolution_binaries/) as a final sanity check.
- Hint #1: You should be able to take inspiration from what
you did to implement the query processor in HW2.
Here, it's only a little bit more complicated.
You want to process the query against each index, and then
intersect each index's results together and do a final sort
(use the STL's
- Now would be a great time to run valgrind over the unit tests to verify you have no memory leaks or memory errors.
Part C: Search Shell
For Part C, your job is to implement a search shell, just like in HW2, but this time using your HW3 infrastructure you completed Parts A and B.
- Open up
filesearchshell.ccand read through it. Note that unlike Parts A and B, we have given you almost nothing about the implementation of thefilesearchshellbesides a really long (and hopefully helpful) comment. Implementfilesearchshell.cc. - Try using your
filesearchshellbinary. You can compare the output of your binary against a transcript of our solution. The transcripts should match precisely, except perhaps for the order of equally ranked matches. You can also walk yourfilesearchshellagainst a very tiny index (tiny.idx) in the debugger to see if it's reading the correct fields and jumping to the correct offsets. - Also, note that you can hit control-D to exit
the
filesearchshell.filesearchshellought to clean up all allocated memory before exiting. So, run yourfilesearchshellunder valgrind to ensure there are no leaks or errors.
Bonus
There are three bonus tasks for this assignment. As before you can do none of them with no impact on your grade. Or, you can do one, two, or all three of them if you're feeling inspired!
If you want to do any of the bonus parts, first create a
hw3-final tag in your repository to mark the version
of the assignment with the required parts of the project.
That will allow us to more easily evaluate how well you did on the
basic requirements of the assignment.
REMINDER: you may not modify the header files for the normal
submission.
Any bonus you do most not be present in the hw3-final tag,
otherwise it could mess up the results of your submisison when we
go to grade it.
Then, when you are done adding additional bonus parts, create a
new tag hw3-bonus after committing your additions,
and push the additions and the new tag to your GitLab repository.
If we find a hw3-bonus tag in your repository we'll
grade the extra credit parts; otherwise we'll assume that you just
did the required parts.
For these tasks you may modify the header files to add additional
members, but do not modify the existing ones and do not have these
changes show up under your hw3-final tag, these changes should only
be present under hw3-bonus.
- (Easy): You've probably noticed that the books seem to
be consistently ranked higher than other document types in the
corpus.
This is for a pretty simple reason: books are long, so any given
query word will, on average, appear more often in a book than in
an email message, inflating the rank of the book.
Solve this problem by normalizing the rank contribution of a word
within a document by the document length; you'll have to modify
the information calculated by hw2 and stored by hw3.
In other words, instead of defining the rank contribution of a
word in a document to be the word frequency, definie it to be the
(word frequency) / (number of words in the document). Do an informal study that evaluates whether this ranking is better or worse, and present your evidence. - (Medium): Normalized term frequency is a better ranking function, but it also has a flaw: some words (e.g., "the" or "person") are inherently more frequently used than others (e.g., "leptospirosis" or "anisotropic"). There is a different ranking contribution function called "tf-idf", or term frequency inverse document frequency, that tries to compensate for this. Calculating tf-idf involves keeping track of how often a word appears across an entire corpus of documents, and normalizing term frequency within a document by the frequency across all documents. So, td-idf measures how much more frequently than average a word appears in a given document. (Here's the wikipedia page on tf-idf.) Implement tf-idf ranking. You'll have to populate a new hashtable for corpus word frequency and incoporate it into the index file format. Do an informal study that evaluates whether this ranking is better or worse than term frequency, and present your evidence.
- (Hard): Use valgrind to do a performance analysis of hw3 query processing, and identify any major performance bottlenecks. If you find some obvious performance bottlenecks, attempt to optimize the code to reduce them. Present graphs that demonstrate the performance before and after your optimization, and the evidence you used to decide what to optimize.
Testing
As with the previous HWs, you can compile the your implementation
by using the make command.
This will result in several output files, including an executable
called test_suite.
After compiling your solution with make, you can run
all of the tests for the homwork by running:
bash$ ./test_suite
You can also run only specific tests by passing command-line
arguments into test_suite.
This is extremely helpful for debugging specific parts of the
assignment, especially since test_suite can be run
with these settings through valgrind and
gdb!
Some examples:
- To only run the
QueryProcessortests, enter:bash$ ./test_suite --gtest_filter=Test_QueryProcessor.*
- To only want to test on a single index for
QueryProcessor, enter:bash$ ./test_suite --gtest_filter=Test_QueryProcessor.TestQueryProcessorSingleIndex
You can specify which tests are run for any of the tests in the assignment — you just need to know the names of the tests! You can list them all out by running:
bash$ ./test_suite --gtest_list_tests
WriteIndexFile tests can take a while to
run, so you can run all tests except those, using:
bash$ ./test_suite --gtest_filter=-Test_WriteIndex.*