Build a compiler. Your compiler accepts as input programs written in naught,
a language I made up, and that is described in detail shortly. Your compiler's
target language is C, that is, it compiles the naught program into an
equivalent C program. You then use gcc to compile the C program into an
executable.
You should realize that your naught compiler, like all compilers, is part of
a larger toolkit that together allow us to turn source language programs into executions.
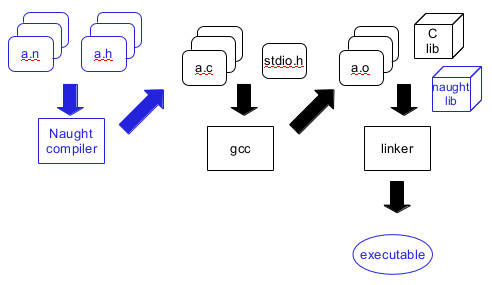
Here's a picture of the relevant components of the naught toolkit. naught
source files have extension .n. It uses .h files in the same way as
C/C++.
The blue components and path are the abstract functionality -- your compiler turns
naught programs into executables. It achieves this using other tools (just as
all compilers do). You will implement the compiler and the naught standard
library, and probably some set of naught test programs. An important part
of this assignment is understanding how all of this fits together. The insights
you'll gain will apply to C/C++ as well.
You'll write the naught compiler in C++. You'll produce C files, and
use gcc to compile them, and not g++. (C is the preferable
target language because it
tolerates more questionable code than C++ is willing to compile.) Because of that,
you'll write the naught library in C as well, so it can be linked with
naught programs.
Here is a nonsense application that shows all the constructs in the
naught language. The application is contained in four files.
Source files must have extent .n.
naught is primarily a subset of C. It contains only the
major features seen in the code above. Here we highlight the
differences from C.
Comments begin with '#' and go to the end of the line.
naught has only three (non-function) data types: int,
pointer, and string. The first is
equivalent to C's int32_t. The second is equivalent
to a int32_t*. The last is compatible with
C strings, so is a char*, but is not quite a C string.
We discuss it in more detail in a later section.
There are only two types of functions: function
and sfunction. The former returns an int
and the latter a string. naught is even
looser about the types of functions than C: a function's type
is determined solely by the type of value it returns; the parameter
list is not part of the type. So, naught can/will not check
that an invocation matches a prototype, in the C sense. Instead,
it just makes sure that if the function has been declared and that the use of
the return value agrees with the declared return type.
Like C, naught allows calls to functions that haven't been
declared. In that case, it prints a warning and assumes that the function returns an int.
The only naught language operations on strings are assignment and '+',
which means concatenation. Concatenation produces a new string.
Assignment makes a copy of the source. Additional operations can be provided
as part of the naught standard library. The reference solution
implements nstrlen(), which is used in the example above.
Pointer dereferencing is indicated by '@', rather than '*'.
naught includes a unary operator, print, that prints
the value it's applied to. Being an operator, it can be embedded inside
expressions to print intermediate results. It returns the type of whatever
it is applied to. (It applies only to strings and ints.)
A working naught compiler promises to give correct executions of
correct naught programs. It says nothing about what happens if
it is given a buggy naught program - even egregious syntax errors
may not be detected at compile time, or ever. The goal, though, is to
provide the strongest, useful compile-time diagnostics possible.
A naught string is stored in memory as a length field followed by
a C-style string. The length field helps speed up the concatenate operation.
The length field is what strlen would return, meaning it does not count
the '\0' that terminates the C-style string portion.
length (int32_t)
C-style string
typedef struct nstring_st {
int32_t len; // The length of the string, ignoring the trailing \0
char str[]; // This is a C-style string
} nstring_st;
A naught string variable is a pointer, meaning it holds an address.
It does not point at the beginning
of this structure, though. Instead, it points at the C-string portion of it.
A pointer to the structure itself can be recovered from the string's value
using pointer arithmetic. (No naught program ever wants to do that, but
the compiler or standard library routines might want to generate code that does.)
Because the naught string points to a C-style string, it can be passed to
C library routines, such as printf.
Note that even string literals are stored using this format in naught.
Building a compiler involves using tools that are usually referred to as
scanner generators and parser generators, also casually referred to as
"lex" and "yacc" (pronounced "yak") after the first widely influential implementations.
In our case, we'll use flex
and bison.
You shouldn't require much involvement with those tools,
so anything you read about lex'ing and yacc'ing should apply. Certainly
the concepts are the same to a very detailed level, far beyond what we
require for this project. However, if you end up wanting to manipulate
those tools, there may well be details that are crucial, and so you'll have
to be careful to obtain those details for our tools.
Compiling comprises lex'ing, parsing, and code generation. Lex'ing is the
process of breaking the input into tokens that make sense in the language.
For instance, a lexer for C would break (x+y+++z) up into tokens (, x,
+, y, +, ++, z, and ).
A parser generator (like flex) typically
takes as input a set of regular expressions. From that it generates a program
that can split an input file up into tokens according to the regular expressions.
We provide you with the input file flex needs to break naught programs
up into sensible tokens.
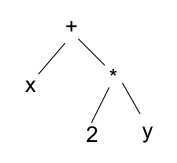
Given the sequence of program tokens, the question now is how they represent statements
the language. The way to think of that is as a syntax tree. For instance, the
expression x+2*y could be represented by this tree:
Given the tree, it's easy to generate code that computes the expression: you
just do a depth first, post-order traversal, emitting the obvious code as you visit
each node. For instance:
temp_172472 = 2 * y;
temp_172473 = x + temp_172472;
What happened was we started at the root, descended to node x, and evaluated it.
Since it's a variable, there's nothing to do. We then descended to the right
and evaluated the multiplication node. That descended to its left and right (resulting
in nothing, since both operands are already evaluated), and then evaluated itself.
That produced the multiplication instruction that comes first in the code sequence.
We then return back to the addition node, which evaluates itself, producing the
second instruction.
Some things to note. First, we have to do some updating of the tree as we evaluate.
For instance, we have to remember that the value of the multiplication was left in
"location" temp_172472, because we might need it later. Second, this evaluation step
is the time to do type checking. We need to verify that the operator applies to
the types of the operands, and we need to annotate the operator with the type of its
result. The types of literals are known from the parsing step (e.g., 2 is an integer
and "this" is a string). We determine the types of program source variables by
maintaining a symbol table, a map from variable name to type. We add new entries
when we see declarations (being careful that our table conforms to the scope rules
of the language). Finally, we determine the types of values produced by intermediate
nodes of the tree when we evaluate them: the operator plus the types of the operands
tells us the type of the result.
While our example tree represents only a simple expression, it's possible to
represent an entire source file this way. That representation is called an
abstract syntax tree (AST). The AST doesn't have to be a binary tree -- you need to
represent sequences of instructions, for instance, and while you could do that with
a binary tree it's arguably not the most natural approach. In any case, the overall
idea is to parse the program file into tokens, to use them to build the AST, and then
to traverse the AST to perform type checking and code generation. (What could be
simpler?)
The missing link in this is how we go from a stream of tokens to the tree.
We do that using a grammar, a set of rules that describe the form of legal statements
in the source language. We then use a parser generator (bison) to create a program
that can apply the grammar to the stream of tokens produced by a lexer. With that,
it becomes pretty straightforward to build the AST.
Here's a grammar for our simple expression example:
expr : expr PLUS expr
| expr MULT expr
| term
;
term : LITERAL
| ( expr )
| ID
;
The capitalized names are tokens produced by the lexer, called terminals.
If our source is the expression x+2*y the lexer could produce ID PLUS LITERAL MULT ID.
The other names are elements of the grammar called non-terminals representing
logical fragments of a program. For example, in the grammar above a term is
thing that has a value without requring any further computation.
You read the sample grammar like this: "an expr is an expr followed by a PLUS followed by
an expr, or it's an expr followed by a MULT followed by an expr, or it's
a term." This should be somewhat intuitive, maybe after a bit of getting
used to it. Addition and multiplication are both binary operators, and
can be applied to any two expressions, getting a new, more complicated
expression.
The parser (created by bison) tries to find a way to go from the token stream
produced by the lexer to the goal symbol (in this case, expr). It uses something
of a back-tracking scheme until either it finds a way
to get from tokens to the expr non-terminal symbol (called a derivation),
or it determines there isn't one.
If there isn't one, there's a syntax error in the source, e.g., x + * 3.
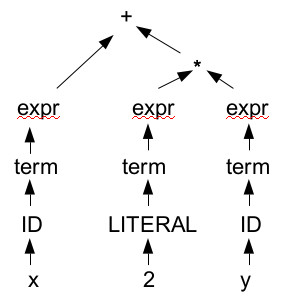
Here's a derivation for our example expression in the simple grammar above:
The bottom row of arrows are decisions made by the lexer, depending solely on the sequence
of characters it sees in the source file. All the arrows above that correspond to
applications of rules in the grammar.
Each time a rule is applied, the parser alerts your code and gives it an opportunity
to do whatever it wants. What it wants to do is to build the AST, piece by piece.
For example, when the "expr MULT expr" rule is applied, you code will create a new
AST node, for the multiply operator, and hang the two existing expr nodes on it. When the
derivation succeeds, the final node is the root of the AST. (You can then traverse
the AST to do type checking and code generation.)
You specify what code to run when a rule fires by annotating the grammar with
your code, like this:
expr : expr PLUS expr
{ $$ = new add_Node($1, $3); }
| expr MULT expr
{ $$ = new mult_Node($1, $3); }
| term
{ $$ = $1; }
;
In the braces is any C++ code you want to execute when the associated grammar rule fires.
There are some special symbols provided.
The parser code associates some value with each non-terminal instance it fires a rule for.
$$ is the name of the value to be associated with the non-terminal instance. $1, $2, etc.
are the names of the values associate with the first, second, etc. item in the rule.
So, the code for the first rule says "create a new add_Node that remembers the nodes corresponding
to the left and right expr operands and associate it with the expr intance that is created by
firing this rule." (You create the add_Node class.)
The code above is representative but isn't
intended to be 100% accurate or to constrain you -- you do whatever you think is needed as rules
fire.
If you want to read more about this process, you could start
here.
There are many documents online that provide even more information, although
most of them seem to be wrestling with the details of tools, rather than
the general concepts. You shouldn't have to wrestle the tools; that's been
done for you already.
Note that there is some complexity in interfacing the
lexer, produced by flex from file naught.lex and the parser, produced
by bison from file naught.bison. The bison file determines what
codes the lexer can return. It also indicates the C++ type of any object associated
with an instance of a rule firing (the type of the $$ variable associated with the
rules of each non-terminal). You'll have to modify the .bison file
as you design your implementation to provide the data types you're using.
You shouldn't have to change the grammar, however, although you can if you want.
The obvious answer is that we should provide routines that will
be of widespread use. Because there will be approximately no
naught programs in the world, there isn't much motivation
to write routines for that reason. As a learning experience, providing
one method is about as good as providing many, so you should write at
least one, nstrlen(), which returns the length of a naught
string (by using that string's length field, not by the more expensive
approach of calling strlen() on the C-string portion).
You should also write a nstdlib.h file that provides prototypes
for the methods in your library, to be used by client naught
programs.
Note: You can give the -I dir switch to gcc to tell it to add dir to .h file directory search path.
A less obvious use for the standard library is to ease the burden
of the compiler. If some language feature leads to a complicated
code generation issue, you might want to compile that feature into a call
to a library routine, rather than generating a long sequence of instructions
in place. Among the advantages are that you get to use the full C language
in a library routine, whereas generated code is much more restricted (see
the next section).
Note: To build an actual library file, libnaught.a, first create nstdlib.o and then issue command
ar -rcs libnaught.a nstdlib.o
Note: To use your library, use the switch -lnaught at the
end of the gcc command that compiles the programs created by
your naught compiler. You can an directory to the library search
path using the switch -L dir.
We give you a complete lexer input file (naught.lex)
that determines what tokens the lexer will return.
We give you a complete grammar file (naught.bison) for naught programs.
That file encodes information about the C++ classes used by your code, so you'll have to modify
it as you define those classes. The modifications should be straightforward, following a brief
period of utter confusion.
We don't give you any code for building the AST (the code associated with the rules firing),
nor for traversing the AST once it is built. Instead we've associated printing with each
grammar rule, so that you can see how things work.
We give you a mainline that controls the process. It calls the parser, which itself calls the lexer.
The parser runs until the derivation is completed, and then returns to the mainline. In a fully working
implementation, that would be where tree traversal started.
This means that you'll:
modify file naught.bison to replace our grammar rule printing code with
whatever you design to construct the AST. You might also have to implement some new classes (e.g., one
or more AST node classes), which you do using the usual .cc/.h file mechanism. Finally, you'll have to
modify some bison directives in naught.bison to expose your new C++ classes to the parser and
lexer. Comments in that file tell you a bit more.
write code to traverse the AST, perform type checking, and generate code.
That code is completely isolated from the lexer/parser infrastructure - it's just a regular old C++
program. It's execution starts in the mainline, when the parser returns.
The skeleton files can be fetched from this link: naught.tar.gz.
Once you have unpacked the files, say make to build the base system. (The machine you're
running on needs to have flex and bison installed, of course. All CSE machines do.)
Then say ./comp test.n to run the lexer and parser against a simple naught program:
The output shows the sequence of grammar rules that fire:
$ ./comp test.n
int x -> vardecl
int x ; -> vardecl_list
x -> term
x -> expr
2 -> term
2 -> expr
y -> term
y -> expr
2 * y -> expr
x + 2 * y -> expr
x + 2 * y ; -> stmt
x + 2 * y ; -> stmt_list
0 -> term
0 -> expr
return 0 ; -> stmt
x + 2 * y ; return 0 ; -> stmt_list
{ int x ; x + 2 * y ; return 0 ; } -> block
function test ( ) { int x ; x + 2 * y ; return 0 ; } -> funcdef
function test ( ) { int x ; x + 2 * y ; return 0 ; } -> module
The C programs your compiler produces have to obey the restriction that
"almost all" C statements involve no more than a single operator (in addition
to a single assignment operator) and up to two operands.
That is, your C shouldn't be much more powerful than hardware machine instructions.
This means you can't compile
the naught statement w = x + y + z into the C statement
w = x + y + z, but instead need something like t1 = y+z; t2 = t1+x; w = t2;.
The exception to this rule, sort of, is procedure calls. A naught function call
can provide an arbitrary number of arguments, and you can just translate this into a C call with
all those arguments.
There's just no end to the improvements that could, conceivably, be
made to any compiler implementation. With that in mind, here is some
help with recognizing when you should stop:
Your compiler (and supporting tools, like the runtime) should produce
correct results on correct naught programs. What they do
for incorrect programs is undefined.
Obviously, the better job you do of rejecting incorrect programs the better.
Also, you shouldn't rely on the C compiler to detect errors for you.
Ideally, any program your compiler produces should be error free as far as the
C compiler is concerned. (C compiler warnings are okay, and maybe inevitable.)
You should try to have a complete implementation for the int and function types
before worrying about pointer.
You should try to have a complete implementation of the pointer data type
before worrying about string.
You should implement strings, and sfunctions, last.
The naught language specification says that string operations produce new
strings. This means the compiler will be causing memory allocations to take place
in the instructions it compiles for those string operations. Someone has to free
that memory, and it can't be the naught programmer's responsibility.
(For example, consider the following string assignment statement: s1 = s2 + s3 + s4.)
You don't have to resolve the memory leak caused by failing to clean up all storage allocated by
the code you generate for string operations. If you have extra time you might try to do that,
but there's no penalty for not even trying. (You should understand what the issue is, though.)
Your compiler provides only part of the functionality requiredto execute naught programs.
I used the following makefile to build executables. (It's shown here to show what the other parts are.)
My compiler is called comp. I push my naught source files through the C preprocessor
(called cpp) before compiling them.