

CSE 333 12su - Systems Programming
Homework #4
out: Friday, Aug. 3, 2012.extra credit feature approval (if you attempt this): Friday, Aug. 10.
due: Wednesday, Aug. 15, 2012 by 11:00 pm.
[ summary | part a | part b | part c | bonus | how to submit | grading ]
| Summary |
For homework #4, you will build on your homework #3 implementation to implement an event-driven Web server front-end to your query processor. In Part A, you will read through some of our code to learn about the event infrastructure we have built for you. In Part B, you will complete some of our classes and routines to finish the implementation of a simple Web server. In Part C, you will add several components to our Web server.
As before, pease read through this entire document before beginning the assignment, and please start early!
In HW4, as with HWs 2 and 3, you don't need to worry about propagating errors back to callers in all situations. You will use assert()'s to spot some kinds of errors and cause your program to crash out. However, no matter what a client does, your web server must handle that; only internal issues (such as out of memory) should cause your web server to crash.
In HW4, you have the choice to work in teams of two. This is not mandatory, it's optional: as with HW3, you can work solo if you prefer.
| Part A -- read through the event and asynchronous processing infrastructure. |
Context.
Our web server is an event-driven program. Instead of creating a thread to handle each connection from a web client, our server instead relies on non-blocking I/O to manage concurrency. This means the web server is structured as a set of callbacks from a main event loop: whenever some event of interest happens, the event loop dispatches that event to an event handling routine. Events include such things as "a socket is readable", or "a new client has connected to a listening socket," or "some file descriptor experienced an error."
 Your HW3 implementation is not event driven. Since the
rest of the web server is event-driven, we'll need to convert
your HW3 to an asynchronous implementation. In a nutshell, we'll
hide your synchronous HW3 implementation behind an interface
(AsyncQuery.h), and we'll implement a pool of threads that will
process queries in the background, while letting the event loop
continue to process queries in the foreground.
Your HW3 implementation is not event driven. Since the
rest of the web server is event-driven, we'll need to convert
your HW3 to an asynchronous implementation. In a nutshell, we'll
hide your synchronous HW3 implementation behind an interface
(AsyncQuery.h), and we'll implement a pool of threads that will
process queries in the background, while letting the event loop
continue to process queries in the foreground.
A web server isn't too complicated, but there is a fair amount of plumbing to get set up. In this part of the assignment, we want you to read through a bunch of lower-level code that we've provided for you. This code sets up the event infrastructure and asynchronous query processing. You need to understand how this code works to finish our web server implementation, but we won't have you modify this plumbing. Be sure to read through everything we ask carefully; event-driven code is non-intuitive, and also somewhat delicate!
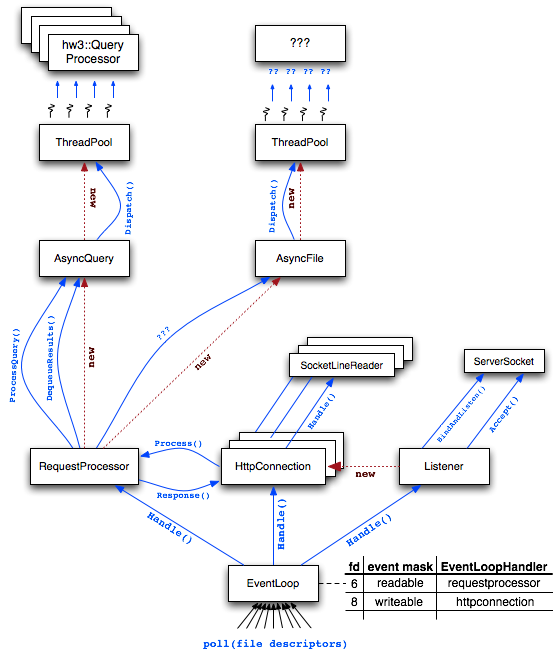
The architecture of the web server is shown in the figure on the right. The bottom of the web server is the EventLoop, which is a module that keeps track of file descriptors, the events customers are interested in learning about on those file descriptors, and callback handler functions for those customers when an event of interest happens. The EventLoop uses the poll() system call to wait for events.
The Listener is a class tha uses a ServerSocket to establish a listening socket. When the Listener is notified that a new client has connected, it accepts the client and creates a new HttpConnection object to manage it.
The HttpConnection object uses a SocketLineReader to read HTTP headers from the client, then invokes Process() on the RequestProcessor to process the request. When the RequestProcessor has finished processing the request, it invokes Response() on the HttpConnection object to hand it the response headers and body. The HttpConnection object then writes the response back to the client and closes the connection.
The RequestProcessor determines what kind of request the client has sent (a web query? a file request), and dispatches the request to the appropriate handler. In the case of a web query, the RequestProcessor invokes ProcessQuery() on an AsyncQuery object. In the case of a file request, you will get to design the AsyncFile object and figure out how to stitch it into the RequestProcessor.
An AsyncQuery object uses a thread pool to process a query asynchronously. The thread pool dispatches one of a number of prefabricated threads to invoke your hw3::QueryProcessor object; the thread takes some time to process the query, and then enqueues the results on a queue maintained by AsyncQuery. When the RequestProcessor is notified that the results are ready, it invokes DequeueResults() to pick them up, fabricates HTTP and HTML, and invokes Response() on the HttpConnection.
What to do.
- Download our hw4.tar.gz archive. Untar it and look around inside of it to familiarize yourself with the structure. Note that there is a libhw1/ directory that contains our libhw1.a, a libhw2/ directory that contains our libhw2.a, and a libhw3/ directory that contains our libhw3.a. You can replace our libraries with yours, or you can use ours if you'd prefer. Also note there is the familiar solution_binaries/ directory with our compiled, working version of HW4's solution. (There is a third binary in there, http333d_withflaws; its purpose will become clear later.)
- Run "make" to compile the two HW4 binaries. One of them is
the usual unit test binary; this time, we're using Google's C++
unit testing framework. The unit test binary is called
"test_suite". Run it, and you'll see the unit tests fail, crash
out, and you won't yet earn the automated grading points tallied
by the test suite. The second binary is the web server itself
(http333d). Try running it to see its command line arguments.
When you're ready to run it for real, you can use a command like:
./http333d 5555 ./unit_test_indices/*
(You might need to pick a different port than 5555 if another student is using that port on the same machine as you.) - Read through ThreadPool.h and ThreadPool.cc. You don't need to implement anything in either, but several pieces of the project rely on this code. The header file is well-documented, so it ought to be clear how it's used. (There's also a unit test file that you can peek at.)
- Similarly, read through AsyncQuery.h and AsyncQuery.cc. These files use the ThreadPool and libhw3.a to process queries asynchronously. A customer dispatches a query request with ProcessQuery(); a worker thread from the thread pool picks up the request and starts processing it. When the query completes, the AsyncQuery object enqueues the results on a queue for the customer to pick up and writes a byte on a "self-pipe" to notify the customer that a query has completed.
- Read through EventLoop.h. The EventLoop class is the beating
heart of the web server. It receives "registrations" from
higher-level objects; a registration provides the event loop with
a file descriptor, a set of events, and a callback handler. When
the event loop detects events have occurred on a registered file
descriptor, it invokes the associated callback handler to deliver
the events. The EventLoop uses the "poll()" system call to do
this; poll is just a more efficient version of select().
The other thing to know about EventLoop is that it will call "delete" on the registered callback handler when it is unregistered. You'll need to keep this in mind as you do other parts of the assignment.
- Read through Listener.cc and Listener.h. This class is a customer of the EventLoop. It establishes a listening socket, then relies on callbacks from the EventLoop to tell it when a new client has connected. When one has connected, it creates an HttpConnection object (HttpConnection.h/.cc) to process it.
- Finally, read through http333d.cc. This file contains main(); it basically creates an EventLoop, a couple of additional classes, then runs the event loop by calling EventLoop::Run().
| Part B -- get the basic web server working. |
Context.
You are now going to finish a basic implementation of the http333d web server. We'll have you implement some of the event handling routines at different layers of abstraction in the web server, culiminating with generating HTTP and HTML to send to the client.
What to do.
- Take a look at HttpUtils.h. This file contains some useful utility routes that we'll use in the rest of this project. Your first job is to implement the URLParser class; we've given you the class declaration as part of HttpUtils.h, and we've placed the skeleton of the class in HttpUtils.cc, but we haven't provided any of the code. (There is unit test code, though, so you'll be able to know when you've got it right!)
- Take a look at ServerSocket.h. This file contains a helpful
class for creating a server-side listening socket, and accepting
a new connection from a client. We've provided
you with the class declaration in ServerSocket.h but no
implementation in ServerSocket.cc; your next job is to build it.
Something you'll need to do is set both the server's listening
socket and each new client socket to non-blocking mode. You can
do this with the fcntl system call; you'll call it once with
F_GETFL to get the socket flags, then you need to call it a
second time with updated flags and F_SETFL. ("man fcntl").
You'll need to make the code handle either IPv4 or IPv6 addresses. Note that the unit test code exercises both cases!
- Look at SocketLineReader.h. This file defines a class that incrementally reads data from a socket, stashing it in an internal buffer. It looks for "\r\n", i.e., carriage-return + newline, which demarcates the end of an HTTP line. It copies each line found to the end of a vector of strings provided by the caller. Your job is to implement SocketLineReader.cc; we've provided the scaffolding and a tiny bit of the implementation, you need to finish it off. Note that there is a good unit test that you can use to see if you're done.
- Read through HttpConnection.h and HttpConnection.cc. This class processes HTTP connections by (a) reading a request, (b) generating a response (asynchronously) by calling out to the RequestProcessor class, and (c) writing the response to the client. We've provided everything but the implementation of the ProcessRead() function; you need to implement that. You might look at ProcessWrite() for some inspiration.
- Finally, read through RequestProcessor.h and RequestProcessor.cc. This class receives a request to process a URL from HttpConnection.cc. Depending on the content of the URL, it processes it in different ways. We've provided you with most of the implementation. Your job is to write the QueryHttpHtml() function, which generates HTTP headers and HTML content, given the response from AsyncQuery.cc. The comment in that function should give you a good start. When you generate the HTML for the query response contents, don't worry about adding hyperlinks for items in the response list -- you'll do that in part C.
You're nearly done with part B! At this point, your web server should run correctly, and everything should compile with no warnings. Try running your web server and connecting to it from a browser. Also try running the test_suite under valgrind to make sure there are no memory issues. Finally, launch the web server under valgrind to make sure there are no issues or leaks; after the web server has launched, exercse it by issuing a few queries, then visit the url "/secret/quit/url" to cause the web server to shut down.
| Part C - add to the Web server. |
Context.
Now that the basic web server works, you are going to add some new functionality to it. There are two things you will do:
- You might have noticed that our example web server is able to serve clients the content of files, but yours does not yet do this. You'll add file serving capabilities to the web server in the first part of part C.
- Your web server (probably) has two security vulnerabilities. We are going to point these out to you, and you will repair them.
This part of the assignment is deliberately open-ended, with much less structure than earlier assignments. This is the culmination of the course; you're ready to handle this on your own!
What to do.
- You are first going to add file processing capabilities
to the web server. The basic idea is simple: when your
web server receives a URL that starts with "/file/", it
will treat the rest of the URL as the name of a file to
open. So, if it receives "/file/test_tree/README.TXT', your web
server should provide clients with the content of
"test_tree/README.TXT". Play around with our web server, and
try clicking on a few of the files; inspect the URLs, and look at
the web page source code that our web server returns.
Remember that the web server is an event-driven, asynchronous program; reading a file, especially a big file, can take quite some time. So, the file reading itself should be done in an asynchronous fashion. Unfortunately, O_NONBLOCK doesn't work for files -- only network sockets -- so, you'll have to make use of our thread pool to do file processing asynchronously.
Your job is to implement a new pair of files (AsyncFile.h and AsyncFile.cc), modify several of the existing web server files (Makefile, RequestProcessor.cc, RequestProcessor.h), and implement unit tests (test_asyncfile.cc and test_asyncfile.h). You should take inspiration from the existing AsyncQuery.h, AsyncQuery.cc, and test_asyncquery.h/test_asyncquery.cc to do it.
You'll also have to modify the code that generates the HTML so that it adds hyperlinks to "/file/" URLs in the query result listing. Also, note that our web server converts results from the wiki.idx index file into URLs into wikipedia; this is really easy to do, so add support for this as well!
- We bet that your implementation has two security flaws.
-
The first is called a "cross-site scripting" flaw. See
this for background if you're curious:
http://en.wikipedia.org/wiki/Cross-site_scripting
Try typing the following query into our example web server, and into your web server, and compare the two. (Note: do this with Firefox or Safari; it turns out that Chrome will attempt to help out web servers by preventing this attack from the client-side!)hello <script>alert("Boo!");</script>
To fix this flaw, you need to implement HTML "escaping": before you relay untrusted input from the client to output, you need to look for dangerous characters and convert them to safe characters. The dangerous characters you need to replace are &, ", ', <, and >. You should replace them with HTML codes for them, such as & for &. - Try visiting the following URL in your browser,
replacing "localhost:5555" with whatever domain name and
port number your server is running on:
http://localhost:5555/file//etc/passwd
Or, try telnet'ing to your web server, and manually typing in a request for the following URL. (Browsers are smart enough to help defend against this attack, so you can't just type it into the URL bar, but nothing prevents attackers from directly connecting to your server with a program of their own!)/file/../http333d.cc
This is called a directory traversal attack. Instead of trusting the file pathname provided by a client, you need to normalize the path and verify that it names a file within your test_tree/ subdirectory; if the file names something outside of that subdirectory, you should return an error message instead of the file contents.As a hint, try looking at the "realpath()" system call available to you on Linux. Think about what the realpath of the test_tree/ directory is; using this, think about what the realpath of an attack path is, what the realpath of a benign path is, and how you would tell the difference.
Fix these two security flaws, assuming they do in fact exist in your server. As a point of reference, in solution_binaries/, we've provided a version of our web server that has both of these flaws in place (http333d_withflaws). Feel free to try it out, but DO NOT leave this server running, as it will potentially expose all of your files to anybody that connects to it.
-
The first is called a "cross-site scripting" flaw. See
this for background if you're curious:
Congrats, you're done with the HW4 project sequence!!
| Bonus |
There are two bonus tasks for this assignment. As before, you can do either one, or not; if you don't, there will be no negative impact on your grade.
- Figure out some interesting feature to add to your web
server, and implement it! As one idea, find the implementation
of a "chat bot", such as Eliza, and add it to your web server.
As another idea, implement logging functionality; every time
your server serves content, write out some record with a timestamp
to a log file; make the log file available through the web server
itself. As a third idea, change the results page to show excerpts
from matching documents, similar to how Google shows excerpts from
matching pages; specifically, make it so that each result in the
result list shows (x words + <bold>hit word> + y words)
for one or more of the query words that hit.
If you decide to do this part, you should send email to cse333-staff@cs with your proposed feature by Friday, Aug. 10. We will let you know if your idea is appropriate for extra credit or not. We'll reject ideas that are too trivial for additional credit (e.g., changing colors of text on the result page) and will strongly advise you against attempting anything that seems way too ambitous to be completed on time (or at least we will ask you to revise your proposal to specify basic features that can likely be implemented in the available time plus others you would like to add if you have time).
- The other bonus task is to perform a performance analysis of your web server implementation, determining what throughput your server can handle (measured in requests per second) and what the performance bottleneck is. You might want to look at the "httperf" tool for Linux to generate synthetic load.
| What to turn in |
When you're ready to turn in your assignment, do the following:
- In the hw4 directory, run "make clean" to clean out any object files and emacs detritus; what should be left are your source files. Also, temporarily move the unit_test_indices and test_tree directory out of the directory so that you don't accidentally include them in your turnin.
- Create a README.TXT file in hw4 that contains your name, student number, and UW email address. If you worked in a team, include both teammates' information. Also, include a brief description of how you solved each part of Part C. If you did any of the bonus parts, include a description of what you did.
- cd up a directory so that hw4 is a subdirectory of your
working directory. Then, run the following command to create your
submission tarball, but replacing "UWEMAIL" with your uw.edu email
account name; note there are two underscores before and
after your UW email address:
tar -cvzf hw4_submission__UWEMAIL__.tar.gz hw4
For example, since my uw.edu email account is "spaulding", I would run the command:tar -cvzf hw4_submission__spaulding__.tar.gz hw4
If you worked in a team, include both of your names in the tarball file name (e.g., hw4_submission__UWEMAIL1__UWEMAIL2__.tar.gz).
- Move the "test_tree/" and "unit_test_indices" subdirectories back into your hw4 directory.
- Use the course dropbox (there is a link on the course homepage) to submit the hw4_submission_UWEMAIL.tar.gz tarball.
| Grading |
We will be basing your grade on several elements:
- The degree to which your code passes the unit tests. If your code fails a test, we won't attempt to understand why: we're planning on just including the number of points that the test drivers print out.
- We have some additional unit tests that test a few additional cases that aren't in the supplied test drivers. We'll be checking to see if your code passes these.
- The quality of your code. We'll be judging this on several qualitative aspects, including whether you've sufficiently factored your code and whether there is any redundancy in your code that could be eliminated.
- The readability of your code. For this assignment, we don't have formal coding style guidelines that you must follow; instead, attempt to mimic the style of code that we've provided you. Aspects you should mimic are conventions you see for capitalization and naming of variables, functions, and arguments, the use of comments to document aspects of the code, and how code is indented.