Contents:
- Introduction
- Part 1: Written Exercises
- Graph Definitions and Terminology
- Part 2: Write a Specification for Graph
- Part 3: Write Tests for Graph
- Test Script File Format
- Hints
- How to Turn In Your Homework
- Q & A
Introduction
In this assignment, you will design a graph ADT and write tests for it. (You will not implement the ADT until HW6.) You get to specify the ADT (choose its operations), and write tests to demonstrate that an implementation meets the specification.
Although this is an individual assignment, in the design stage you will learn more and produce a better design by bouncing your ideas off others and incorporating their own ideas. To encourage discussion, we are relaxing the standard collaboration policy somewhat for the interface design stage of this assignment. You must first attempt to come up with an interface design on your own, but then you are strongly encouraged to discuss your design with your classmates who have also attempted a design (as well as the course staff during office hours) as much as you like, without restrictions on what materials you can bring to or from meetings. On the other parts of this assignment, the standard collaboration policy still applies.
This assignment is the first of a multi-part project. Think about building a campus map to get an idea of one application for your graph ADT. By the end of the quarter, you will build a full application for getting directions to travel between two buildings on the UW campus. Remember that the goal here is to design a resusable ADT — specializing your graph for the "map" application would only weaken the reusability of your code.
This assignment assumes that you have read and understood the handout about abstraction functions and representation invariants. If you have not read it, do so now.
You will reuse and extend the graph ADT in future assignments. Do the best you can, but you should expect to improve your design and refactor your implementation over the course of the quarter.
In addition to this writeup, this video has an overview of the assignment that you may find to be a useful supplement to the details here.
Part 1: Written Exercises
We start the assignment with this worksheet, where you will practice some of the ADT concepts from lecture.
In this worksheet you will work on the IntPoly ADT, which represents a polynomial with integer coefficients. You will
think about how representation invariants can be chosen, how these invariants relate to the representations we have, and how they
change our design process. Although the rest of this assignment won't use this specific ADT, we recommend you work on this part first,
as it can be helpful in later parts, where you will design your own ADT.
Feel free to rewrite the problems on a separate sheet. You do not have to turn in these exact pages with the blanks filled in (though you can do that as well). It is okay to submit a scanned copy of a hand-written document as long as it is legible, so you can also print the worksheet, write your answers on that, and scan it when done.
After finishing, submit your solution as a PDF in Gradescope. Be sure to indicate in Gradescope which pages of your PDF solved which parts of the worksheet problem. The rest of the homework will have a different submission method (as described in previous assignments); your PDF solution to part 1 should be the only file you submit in Gradescope.
Graph Definitions and Terminology
In the rest of this assignment you will design a directed labeled graph and write tests for it, but you will not implement it. What you eventually turn in will look very similar to the starter code we have given you for the previous homework. There should be full Javadoc comments, stubs for methods/constructors, tests, etc. but no implementation at all – that’s something for HW6 (You will lose a very significant amount of points if you implement it.)
A graph is a collection of nodes (also called vertices) and edges. Each edge connects
two nodes. In a directed graph, edges are one-way: an edge e = ⟨A,B⟩ indicates that B
is directly reachable from A. To indicate that B is directly reachable from A and A from B, a
directed graph would have edges ⟨A,B⟩ and ⟨B,A⟩.
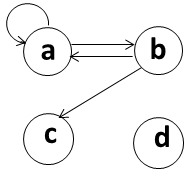
The children of node B are the nodes to which there is an edge from B. In Fig. 1, the children of B are A and C. Similarly, the parents of B are the nodes from which there is an edge to B. In Fig. 1, B has only one parent, A.
A path is a sequence of edges ⟨node1,node2⟩, ⟨node2,node3⟩, ⟨node3,node4⟩,
.... In other words, a path is an ordered list of edges, where an edge to some node is
immediately followed by an edge from that node. In Fig. 1, one possible path is ⟨B,A⟩,⟨A,B⟩,⟨B,C⟩.
This path represents traveling from B to A to B to C. A path may traverse a particular edge any number of times.
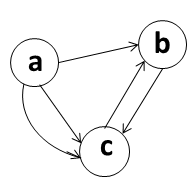
In this class, your graphs can have any number of edges (zero, one, or more) between a pair of nodes (this kind of graph is often known as a multigraph). Fig. 2 shows a graph with 2 edges from A to C.
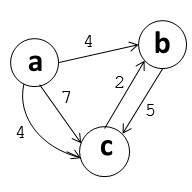
In a labeled graph (Fig. 3), every edge has a label containing information of some sort. Labels are not unique: multiple edges may have the same label. For this project, you may assume that no 2 edges with the same parent and child nodes will have the same edge label. (Whether or not you do make the assumption, make sure it is clearly documented so clients understand how they can use your ADT.)
If you want to learn more, read Wikipedia's definition of a graph. If you still have questions, ask the course staff.
Many interesting problems can be represented with graphs. For example:
- A graph can represent airline flights between cities, where each city is a node and an edge
⟨A,B⟩indicates that there is a flight from A to B. The edge label might represent the cost in money (airfare), time (length of flight), or distance. - To find walking routes across the UW campus, you can build a graph where nodes represent buildings and other locations and edges represent walking paths connecting two locations. The label/cost of an edge is the physical length of that path.
- The Web can be modeled as a graph with node for every webpage and an edge
⟨A,B⟩if page A links to page B. The label could indicate the anchor text for a link on page A, or the number of links from page A to page B. - Facebook is essentially a giant graph with nodes for users and edges between friends. (You can see a visualization of the Facebook graph.)
Part 2: Write a Specification for Graph
To start, you will specify the API for a Java class or classes representing a directed labeled graph. The API, or public interface, is the collection of public classes and methods that clients of your graph ADT can use. We recommend that you work in iterative layers of detail. Start rough — preferably with pencil and paper — by identifying what operations the ADT needs to support, how it might be logically broken into classes and interfaces, and how these classes and interfaces rely on each other. Then, jot down a list of methods for each class that provide these operations. Think through some possible client applications, particularly the application in UW campus map, to get an idea for what operations are needed. Perhaps write some pseudocode (or even real code) for the application and make sure your graph interface meets its needs. (Note: don't worry about implementing the path finding or search algorithm — in fact, you should not add a sorting algorithm. We prefer that you focus on the lower-level operations needed to build the graph and to be able to perform some search. We'll be looking at how to search a graph and do path-finding in later assignments.)
Keep your initial design rough — don't write formal class and method specifications with all the proper clauses right away. Your design will likely go through multiple iterations, and it's easier to throw away parts if you have invested less effort in them.
You may find the Test Script File Format section to be helpful in determining, at minimum, the functionality your graph must be able to satisfy. Implementing the test script commands as a client of your graph should be a trivial matter.
Once you are satisfied with your high-level design, write a Javadoc specification for each class and method.
Follow the CSE 331 format, remembering to use both standard
Javadoc tags (param, return, throws) and ones introduced for this course
(spec.requires, spec.effects, spec.modifies). A good approach is to
create skeleton implementations of your classes containing only method “stubs” for public methods,
then write your specifications in the right place in the source file. A stub is a not-yet-implemented method
whose body simply throws a RuntimeException with a message indicating that the method is not yet implemented. Stub methods give
you the flexibility to compile client code and tests before all your methods are implemented correctly.
As you write the Javadoc specifications and create the stub methods, review the HTML API documentation produced
by the javadoc tool. You can invoke the
javadoc took by running the "javadoc" task under the "documentation" category for your gradle project. Reviewing
specifications in this format can provide useful feedback on the quality and completeness of the work you've
done. After you run the javadoc tool, you can view the generated docs by right clicking on the file
hw-graph/build/docs/javadoc/index.html and choosing "Open in Browser."
You may assume nodes are uniquely identified by their data contents: that is, no two nodes store entirely equal data.
For this assignment, you should restrict your graph to store the data in nodes and edge labels as
Strings. We strongly recommend you DO NOT use Java generics for
this assignment. Students who have had an informal introduction to Java generics, and who try to use generics on
this assignment, tend to struggle on subsequent assignments. CSE 331 will give a more disciplined introduction
to generics. After that, you will use generics to make your ADT work with other data types — text,
integers, doubles, etc.
Because you are defining a single abstraction (a graph), you should generally define a single top-level class.
(You may choose to define a top-level interface as well.) It is OK to use helper classes, but they should be
inner classes — much like Map.Entry
is a nested interface of Map.
Note that inner classes can be public and used by clients, as Map.Entry is. (If the inner class is
an implementation detail, it should be private. If it is a publicized part of the ADT specification, it should
be public.) You can create other top-level classes that are not part of the graph implementation, if necessary.
Why should there be only one top-level graph class? It would be bad style to spread a single abstraction across multiple public top-level classes. Using multiple public top-level classes leads to an implementation and a rep invariant that is distributed across multiple classes rather than being local as it should be. Putting your abstraction in a single top-level class makes it easier to understand and verify. In some cases (though not for public helper classes!), helper classes are implementation details, so their existence exposes the representation — a client could come to depend on them, restricting your ability to change the implementation in the future.
Implementation details, such as fields, representation invariants, and abstraction functions, private methods, and private inner classes, are not part of the public specification. Therefore, they should not be part of what you submit for this assignment.
Design problems such as this one are open-ended by nature: we are not looking for one “right” design. There are principles of good design you have learned in lecture, however. You will also find suggestions of what to consider and how to approach the problem in the hints section. Also, designs naturally evolve as requirements change, so try to make your code easy to expand without making it overly general right away. You are allowed to change the design in the future, and most students do, as they discover limitations of their original design or invent better designs.
In the file hw-graph/src/main/java/graph/answers-hw5.txt, write a brief description of why you included the
operations you did and why you feel they are a sufficient interface to a graph. If your design includes multiple
classes or interfaces, explain why you included each one; if not, explain whether you considered additional
classes and why you decided not to include them. So your total work in this part is this brief write-up plus the
Javadoc class and method specifications as they appear in the source code; you do not need to submit the Javadoc
comments in a separate file, nor the generated API documentation (.html files). You should,
however, make sure that the javadoc tool works without error before you turn in this assignment -
we'll be using the javadoc tool to read your specifications when grading this assignment. The gradle javadoc
task can help you find and fix any formatting or documentation errors you might have.
Part 3: Write Tests for Graph
Write a high-quality test suite for your Graph specifications. It's important to write your tests before your code. You'll be writing tests for your graph in two different ways:
- Script Tests: Because we didn't specify any of the class or method names you need to
write for this assignment, we cannot test your interface directly. Instead, you will
construct script test cases in the format specified in the Test Script File Format section. Each test case should consist of a
“test” file containing a series of commands, and an “expected”
file containing the output that the commands should produce. The file names should have the same base name
but end with
.testand.expected, respectively. For example, you may have a command file namedtestAdd.testwith expected output intestAdd.expected. These files must be in thehw-graph/src/test/resources/testScripts/directory. They should have descriptive file names and comments that explain what case is being tested, and just like methods in unit tests, each test file should test only one distinct condition. It is okay to include many operations in a single test, but those operations must be focused on testing one particular behavior. Think of each .test/.expected pair as the equivalent to one method in a JUnit test suite — you'll probably have a large number of them. The staff supplied GraphTestDriver will read from these files using the format described and "run the tests". For now, you don't have to implement the driver. - JUnit Tests: For any behavior that you weren't able to fully test using the script tests,
you should write unit tests in one or more JUnit test classes, just like you saw in the setup and
polynomial homework assignments. In general, you want to create one test class per public ADT class. Since
you wrote stubs in your class(es), you should write tests that call and test the stubs as if they were
implemented. Therefore, once you implement the stubs in the next assignment, you should be able to run your
JUnit tests without having to edit those files. You should put junit tests you write in
hw-graph/src/test/java/graph/junitTests. Note: You'll likely need to import your graph code (import graph.*;) in your JUnit tests in order for the code to compile.
The combination of the script tests and the JUnit tests should be a complete and thorough test suite for your graph. In general, you should try to test as much behavior as possible using the script tests first, then only add any supplementary tests needed as JUnit tests for anything that you can't write using the script testing language. Depending on your design, this may mean that you have very few JUnit tests (if the majority of your program's behavior can be tested using the script language).
Documentation: In the same answers-hw5.txt file from earlier, write a paragraph or
two (maximum) documenting and explaining your testing strategy. Mention how your script tests differ from
your JUnit tests (if they do) and why.
Note that both your script tests and your JUnit tests will fail, because you have not yet
implemented your graph. They should succeed after you implement your graph in the next assignment. Therefore,
you don't need to try to run your tests for this assignment. Your code should compile correctly,
however. You can use the hw-graph:validateGraphDesign gradle task, under "hw-graph > Tasks >
homework" in the gradle menu, to verify that your code compiles and the javadocs generate successfully.
It is important to check every aspect of the output files to make sure that your tests are running correctly, including whitespace. We use an automated script to compare the expected and actual output of your files and report if they don't match.
Test Script File Format
Because you and your classmates will have different specifications for the class(es) in this assignment, it is important that there is a standardized interface to use and test your code. To that end, we specify a text-based scripting format used to write instructions that will be executed by your graph. Because the script language is designed to be a standard interface for all students, you must implement the script language exactly as we describe it here. You may not add or remove commands, and you may not modify the output format, casing, whitespace, or behavior of any of the exsiting commands in any way. The point of the script language is for it to be consistent across all students, so everyone must implement the same thing.
The testing script is a simple text file with one command listed per line. Each line consists of words separated by white space. The first word on each line is a command name. The remaining words are arguments to that command. To simplify parsing the file, graph names and node and edge data may contain only alphanumeric ASCII characters (in other words, numbers and English letters (upper or lower case)).
Each test that you write will consist of two files with the same name, but one with the .test
extension, and the other with the .expected extension. When the tests are run, the test driver will
read each line in the .test file and execute the corresponding command (or simply echo it, as
described below) then add the output of that command to a file that it generates with the same name but an
.actual extension. After the test is complete, the .actual file looks exactly like the
.test file but every command has been replaced with the output of running that command. To
determine if the test has passed, the test driver compares the contents of the .expected and .actual
files. If they match exactly, the test passes. If there's some difference between what was "expected" and what
"actual"lly happened, the test fails.
Remember, in this assignment, you haven't implemented graph yet, so your tests are expected to fail
and you don't need to try to run them. For reference for future assignments, the .actual files will
generate in hw-graph/build/resources/test/testScripts/. It can sometimes be helpful to look at the
contents of the .actual file to see what went wrong when debugging in later assignments. IntelliJ
can help with this — select both the .expected and .actual files for a test in the
IntelliJ file browser, then right click on one and choose "Compare Files". In the testing window at the
bottom of IntelliJ after running tests, IntelliJ will also often provide a "Click to Show Difference" link
when you have a failed test selected, which uses the same tool.
The following is a description of the valid commands. Each command has an associated output that's generated when the command is executed. Lines that have a hash (#) as their first character are considered comment lines and are only echoed to the output when running the test script. Lines that are blank should cause a blank line to be printed to the output. These commands were chosen for ease of testing and are not meant to suggest what methods you should include in your graph specifications or how you should implement them. For example, it is unlikely to make sense for your graph ADT to store a name for the graph.
CreateGraph graphName
Creates a new graph named graphName. The graph is initially empty (has no nodes and no edges). The command's output is:
created graph graphName
If the graph already exists, the output of this command is not defined. Note that graph names are used purely in the test script — they allow you to create a use multiple graphs within the same test; it is unlikely to make sense for your graph ADT to store a name.
AddNode graphName nodeData
Adds a node represented by the string nodeData to the graph named graphName . The command's output is:
added node nodeData to graphName
If a node with this data is already in the graph, the output of this command is not defined.
AddEdge graphName parentNode childNode edgeLabel
Creates an edge from parentNode to childNode with label edgeLabel in the graph named graphName. The command's output is:
added edge edgeLabel from parentNode to childNode in graphName
If either node does not exist in the graph, the output of this command is not defined. If an identical edge (same parent, child, and label) already exists, the output of this command is not defined either, as it is left to your discretion whether to allow identical edges in your implementation.
ListNodes graphName
This command has no effect on the graph. Its output starts with:
graphName contains:
and is followed, on the same line, by a space-separated list of the node data contained in each node of the graph. The nodes should appear in alphabetical order. There is a single space between the colon and the first node name, but no space if there are no nodes.
ListChildren graphName parentNode
This command has no effect on the graph. Its output starts with:
the children of parentNode in graphName are:
and is followed, on the same line, by a space-separated list of entries of the form
node(edgeLabel), where node is a node in graphName to which there is an edge
from parentNode and edgeLabel is the label on that edge. If there are multiple edges
between two nodes, there should be a separate node(edgeLabel) entry for each edge. The nodes
should appear in lexicographical (alphabetical) order by node name and secondarily by edge label, e.g.
firstNode(someEdge) secondNode(edgeA) secondNode(edgeB)
secondNode(edgeC) thirdNode(anotherEdge). There is a single space between the colon and the
first node name, but no space if there are no children.
Sample input and output
We have provided example input and output files in your hw-graph/src/test/resources/testScripts/
directory. You may assume the input files are well-formed.
Hints
Writing Specifications
To give you some sense of the kinds of issues you should be considering in your design, here are some questions worth considering. These don't in general have simple answers. You'll need to exercise judgment, and think carefully about how different decisions may interfere with each other.
- Will the graph be mutable or immutable?
- Will the graph be implemented as a single class, or will there be a Java interface for the Graph specification and a separate class for the implementation?
- Will edges be objects in their own right? Will they be visible to a client of the abstract type?
- Will nodes be objects in their own right? Will they be visible to a client of the abstract type?
- When will the user specify the nodes and/or edges in the graph? (In the constructor? With an insertion method? Both? Can the user add multiple nodes and/or edges at once?)
- What kind of iterators will the type provide?
- Will the type provide any views, like the set view returned by the
entrySetmethod of java.util.Map? - Will the type implement any standard Java collection interfaces?
- Will the type use any standard Java collections in its implementation?
In choosing what operations/methods to include, strive to include enough that the ADT will be convenient and useful for a client, but avoid the temptation to write an “everything but the kitchen sink” API. Generally speaking, it is better to design a minimal than a maximal API. In the real world, you can always add methods later. However, you can never remove them from a published API, and such methods may over-constrain the implementation in the future.
Make good use of the course staff. If you have concrete questions, then take your specification to office hours for feedback on your design and style. Doing so could save you a lot of time.
Designing Tests
It can be difficult to come up with a good test suite. You would like to test a variety of “interesting” graphs, but what are interesting graphs? One possible approach is a “0, 1, 2” case analysis: test scripts with 0, 1, and 2 graphs are interesting; graphs with 0, 1, and 2 nodes and 0, 1, and 2 edges are interesting. For each method, 0, 1, and 2 parameters and 0, 1, and 2 results are interesting; for example: AddEdge on nodes that currently have 0, 1, and 2 children; ListChildren on nodes with 0, 1, and 2 children; etc. This approach, while certainly not required, can give a good way to structure your tests to cover many important cases without too much redundancy. Following only this approach doesn't guarantee that you've written a good test suite, though, so make sure you apply the knowledge you've gained in lecture and section and ask questions if you're confused.
You also may want to think about specific kinds of Graphs, and test those cases separately. For example: what might go wrong if your graph has a cycle in it? What if there are "islands" — multiple different groups of nodes that have no edges connecting them? What about other "odd" Graphs?
IntelliJ and .test files
IntelliJ may prompt you to install a plugin for .test files. Don't install it, IntelliJ is
misunderstanding what we're using the .test files for. Just manipulate .test files as
text.
How to Turn In Your Homework
Your answers in Part 1 should be submitted in Gradescope, as a PDF file. This should be the only part you are submitting in Gradescope.
Refer to the Assignment Submission Handout and closely follow the steps listed to submit your assignment. Do not forget to double check your submission as described in that handout — you are responsible for any issues if your code does not run when we try to grade it.
Use the tag name hw5-final for this assignment. Note: The regular gradle validate
task attempts to run the tests for an assignment. Since your tests are expected to fail for this assignment, you
should use the
the grade task: hw-graph:validateGraphDesign to verify your code on attu.
Your TA should be able to find the following in the your repository:
hw-graph/src/main/java/graph/answers-hw5.txthw-graph/src/main/java/graph/*.java- [Java classes for your graph design]hw-graph/src/test/resources/testScripts/*.testhw-graph/src/test/resources/testScripts/*.expectedhw-graph/src/test/java/graph/junitTests/*.java- [Other JUnit test classes you create]
Note: The answers-hw6.txt file will be used for next week's assignment — you can
leave it blank for the purposes of this assignment.
Q & A
Q: Does the graph ADT have to support an edge connecting a node to itself?
A: Yes. It's common for graphs to have these kind of nodes, so your ADT should allow them.
Q: Does the graph ADT have to support multiple edges between the same nodes with the same edge labels?
A: No, you can choose if you'd like to support this as part of your design.