Web Programming Step by Step
Lecture 11
Form Validation
References: PHP.net, webcheatsheet.com, roscripts, PHPro
Except where otherwise noted, the contents of this presentation are Copyright 2010 Marty Stepp and Jessica Miller.


A form that submits to itself
<form action="" method="post"> ... </form>
-
a form can submit its data back to itself by setting the
actionto the page's own URL (or blank) -
benefits
- fewer pages/files (don't need a separate file for the code to process the form data)
- can more easily re-display the form if there are any errors
Processing a self-submitted form
if ($_SERVER["REQUEST_METHOD"] == "GET") {
# normal GET request; display self-submitting form
?>
<form action="" method="post">...</form>
<?php
} elseif ($_SERVER["REQUEST_METHOD"] == "POST") {
# POST request; user is submitting form back to here; process it
$var1 = $_REQUEST["param1"];
...
}
- a page with a self-submitting form can process both GET and POST requests
- look at the global
$_SERVERarray to see which request you're handling - handle a GET by showing the form; handle a POST by processing the submitted form data
What is form validation?
- validation: ensuring that form's values are correct
- some types of validation:
- preventing blank values (email address)
- ensuring the type of values
- integer, real number, currency, phone number, Social Security number, postal address, email address, date, credit card number, ...
- ensuring the format and range of values (ZIP code must be a 5-digit integer)
- ensuring that values fit together (user types email twice, and the two must match)
A real form that uses validation
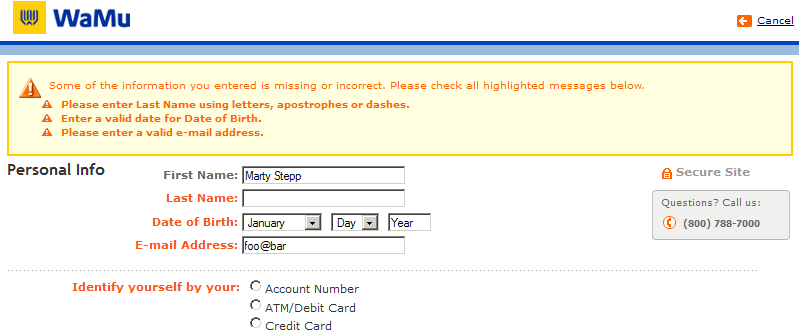
Client vs. server-side validation
Validation can be performed:
- client-side (before the form is submitted)
- can lead to a better user experience, but not secure (why not?)
- server-side (in PHP code, after the form is submitted)
- needed for truly secure validation, but slower
- both
- best mix of convenience and security, but requires most effort to program
An example form to be validated
<form action="http://foo.com/foo.php" method="get"> <div> City: <input name="city" /> <br /> State: <input name="state" size="2" maxlength="2" /> <br /> ZIP: <input name="zip" size="5" maxlength="5" /> <br /> <input type="submit" /> </div> </form>
- Let's validate this form's data on the server...
Basic server-side validation code
$city = $_REQUEST["city"];
$state = $_REQUEST["state"];
$zip = $_REQUEST["zip"];
if (!$city || strlen($state) != 2 || strlen($zip) != 5) {
print "Error, invalid city/state/zip submitted.";
}
- basic idea: examine parameter values, and if they are bad, show an error message and abort. But:
- How do you test for integers vs. real numbers vs. strings?
- How do you test for a valid credit card number?
- How do you test that a person's name has a middle initial?
- (How do you test whether a given string matches a particular complex format?)
Regular expressions
/^[a-zA-Z_\-]+@(([a-zA-Z_\-])+\.)+[a-zA-Z]{2,4}$/
- regular expression ("regex"): a description of a pattern of text
- can test whether a string matches the expression's pattern
- can use a regex to search/replace characters in a string
- regular expressions are extremely powerful but tough to read
(the above regular expression matches email addresses) - regular expressions occur in many places:
- Java:
Scanner,String'ssplitmethod (CSE 143 sentence generator) - supported by PHP, JavaScript, and other languages
- many text editors (TextPad) allow regexes in search/replace
- Java:
Regular expressions in PHP (PDF)
- regex syntax: strings that begin and end with
/, such as"/[AEIOU]+/"
| function | description |
|---|---|
preg_match(regex, string)
|
returns TRUE if string matches regex
|
preg_replace(regex, replacement, string)
|
returns a new string with all substrings that match regex replaced by replacement |
preg_split(regex, string)
|
returns an array of strings from given string broken apart using given regex as delimiter (like explode but more powerful)
|
PHP form validation w/ regexes
$state = $_REQUEST["state"];
if (!preg_match("/^[A-Z]{2}$/", $state)) {
print "Error, invalid state submitted.";
}
preg_matchand regexes help you to validate parameters- sites often don't want to give a descriptive error message here (why?)
Basic regular expressions
/abc/
- in PHP, regexes are strings that begin and end with
/ - the simplest regexes simply match a particular substring
- the above regular expression matches any string containing
"abc":-
YES:
"abc","abcdef","defabc",".=.abc.=.", ... -
NO:
"fedcba","ab c","PHP", ...
-
YES:
Wildcards: .
- A dot
.matches any character except a\nline break/.oo.y/matches"Doocy","goofy","LooNy", ...
- A trailing
iat the end of a regex (after the closing/) signifies a case-insensitive match-
/mart/imatches"Marty Stepp","smart fellow","WALMART", ...
-
Special characters: |, (), \
|means OR/abc|def|g/matches"abc","def", or"g"- There's no AND symbol. Why not?
()are for grouping/(Homer|Marge) Simpson/matches"Homer Simpson"or"Marge Simpson"
\starts an escape sequence- many characters must be escaped to match them literally:
/ \ $ . [ ] ( ) ^ * + ? /<br \/>/matches lines containing<br />tags
- many characters must be escaped to match them literally:
Quantifiers: *, +, ?
*means 0 or more occurrences/abc*/matches"ab","abc","abcc","abccc", .../a(bc)*/matches"a","abc","abcbc","abcbcbc", .../a.*a/matches"aa","aba","a8qa","a!?xyz__9a", ...
+means 1 or more occurrences/a(bc)+/matches"abc","abcbc","abcbcbc", .../Goo+gle/matches"Google","Gooogle","Goooogle", ...
?means 0 or 1 occurrences/a(bc)?/matches"a"or"abc"
More quantifiers: {min,max}
{min,max}means between min and max occurrences (inclusive)/a(bc){2,4}/matches"abcbc","abcbcbc", or"abcbcbcbc"
- min or max may be omitted to specify any number
{2,}means 2 or more{,6}means up to 6{3}means exactly 3
Anchors: ^ and $
^represents the beginning of the string or line;
$represents the end-
/Jess/matches all strings that containJess;
/^Jess/matches all strings that start withJess;
/Jess$/matches all strings that end withJess;
/^Jess$/matches the exact string"Jess"only -
/^Mart.*Stepp$/matches"MartStepp","Marty Stepp","Martin D Stepp", ...
but NOT"Marty Stepp stinks"or"I H8 Martin Stepp"
-
-
(on the other slides, when we say,
/PATTERN/matches"text", we really mean that it matches any string that contains that text)
Character sets: []
-
[]group characters into a character set; will match any single character from the set/[bcd]art/matches strings containing"bart","cart", and"dart"- equivalent to
/(b|c|d)art/but shorter
- inside
[], many of the modifier keys act as normal characters/what[!*?]*/matches"what","what!","what?**!","what??!", ...
- What regular expression matches DNA (strings of A, C, G, or T)?
/[ACGT]+/
Character ranges: [start-end]
- inside a character set, specify a range of characters with
-/[a-z]/matches any lowercase letter/[a-zA-Z0-9]/matches any lower- or uppercase letter or digit
- an initial
^inside a character set negates it/[^abcd]/matches any character other than a, b, c, or d
- inside a character set,
-must be escaped to be matched/[+\-]?[0-9]+/matches an optional+or-, followed by at least one digit
- What regular expression matches letter grades such as A, B+, or D- ?
/[ABCDF][+\-]?/
Escape sequences
- special escape sequence character sets:
-
\dmatches any digit (same as[0-9]);\Dany non-digit ([^0-9]) -
\wmatches anyword character
(same as[a-zA-Z_0-9]);\Wany non-word char -
\smatches any whitespace character ( ,\t,\n, etc.);\Sany non-whitespace
-
- What regular expression matches dollar amounts of at least $100.00 ?
/\$\d{3,}\.\d{2}/
Regular expression PHP example
# replace vowels with stars $str = "the quick brown fox"; $str = preg_replace("/[aeiou]/", "*", $str); # "th* q**ck br*wn f*x" # break apart into words $words = preg_split("/[ ]+/", $str); # ("th*", "q**ck", "br*wn", "f*x") # capitalize words that had 2+ consecutive vowels for ($i = 0; $i < count($words); $i++) { if (preg_match("/\\*{2,}/", $words[$i])) { $words[$i] = strtoupper($words[$i]); } } # ("th*", "Q**CK", "br*wn", "f*x")
- notice how
\must be escaped to\\