The content for this lesson is adapted from material by Hunter Schafer.
Objectives¶
In addition to fairness, another key research area in data science is the notion of privacy when it comes to data. How do we define privacy, and then how do we ensure privacy?
Setting up¶
Since this is not a coding lesson, there is no notebook to follow along with. For an offline copy of this lesson, feel free to print out this page!
Anonymity¶
What responsibility do data scientists have in managing user data? As users, we share our data with services (digital or otherwise) in the hope that it contributes to a better experience for ourselves or society at large. For example, your health records are typically shared with doctors so that they can provide more personalized care especially between different doctors. Other times, you may participate in health research to help scientists investigate population health trends or test new treatments that could save lives.
Medical data is crucial in helping doctors and scientists make decisions. But medical data can also be very private information. In the United States, personally-identifying health information is protected under HIPAA. Healthcare providers must ensure data about individuals remains private so as to avoid violating individual privacy.
There’s a trade-off between the amount of detail in data and the privacy of individuals’ represented by the data. How can we ensure privacy while still applying medical data to inform public health? How can we publish data but make it anonymous by removing personally-identifying information? It turns out that just removing names and IDs is often not enough to protect the identity of individuals with unique records.
“Anonymous” Data¶
In the 1990s, an organization in Massachusetts decided to publish a dataset of hospital visits to help researchers study health trends. To avoid leaking potentially sensitive data, they removed information that uniquely identified individuals such as their name, address, and social security numbers. However, they felt like they should still include broad demographic data like sex, date of birth, and zip code to help researchers.
They did this believing that that broad demographic data posed little risk to an individual’s privacy. But it turns out that this approach does not protect privacy! The Ethical Algorithm describes the story of Latanya Sweeney, a now-professor at Harvard:
Latanya Sweeney, who was a PhD student at MIT at the time, was skeptical. To make her point, she set out to find William Weld’s [the governer of Massachusetts] medical records from the “anonymous” data release. She spent $20 to purchase the voter rolls for the city of Cambridge, Massachusetts, where she knew that the governor lived. This dataset contained (among other things) the name, address, zip code, birthdate, and sex of every Cambridge voter—including William Weld’s. Once she had this information, the rest was easy. As it turned out, only six people in Cambridge shared the governor’s birthday. Of these six, three were men. And of these three, only one lived in the governor’s zip code. So the “anonymized” record corresponding to William Weld’s combination of birthdate, sex, and zip code was unique: Sweeney had identified the governor’s medical records. She sent them to his office.
The combination of many general details makes it possible to narrow down from a large group of hundreds of thousands to just an individual. In later research, Sweeney estimated that 87% of the US population can be uniquely identified using only (1) date of birth, (2) sex, and (3) zip code.
Can we fix this by removing those three columns? Well…
- It wasn’t obvious at first that date of birth, sex, and zip code would violate privacy, so how can you ensure that any columns you end up including don’t ultimately lead to the same mistake again?
- Demographic data is useful to researchers when it comes to identifying health trends, particularly for identifying subgroups that are most affected by trends. Removing demographic detail makes it difficult for the data to be useful to scientists.
Food for thought: How can we ensure individual privacy while still publishing demographic information?
k-anonymity¶
Sweeney defines the concept of k-anonymity as a property that ensures at least some coarse level of privacy for an individual. A dataset is k-anonymous if any combination of “insensitive” attributes (e.g. sex, date of birth, zip code) appearing in the dataset match at least k individuals in the dataset.
There are generally two strategies for making a dataset k-anonymous:
- Remove insensitive attributes to provide fewer ways to identify individuals
- “Fuzzing” the data to make it a little less precise at identifying individuals. One example is showing an age-range rather than an exact age.
For example, you can see an example of a 2-anonymous dataset in the image below (taken from The Ethical Algorithm). This dataset is 2-anonymous because it narrows down the possible entries for an individual down to 2 rows for any insensitive data you might know about them. So for example, if you know someone named Linda is a 56-year-old female, you can only narrow down the dataset to two rows that could potentially belong to her (hence, 2-anonymous). The possible rows are italicized.
| Name | Age | Gender | Zip Code | Smoker | Diagnosis |
|---|---|---|---|---|---|
| * | 60-70 | male | 191** | Y | Heart disease |
| * | 60-70 | female | 191** | N | Arthritis |
| * | 60-70 | male | 191** | Y | Lung cancer |
| * | 60-70 | female | 191** | N | Crohn’s disease |
| * | 60-70 | male | 191** | Y | Lung cancer |
| * | 50-60 | female | 191** | N | HIV |
| * | 50-60 | male | 191** | Y | Lyme disease |
| * | 50-60 | male | 191** | Y | Seasonal allergies |
| * | 50-60 | female | 191** | Y | Ulcerative colitis |
One nice thing about this definition is it allows you some sense of control over the trade-off between privacy and utility. To ensure more privacy, you can make k larger for stronger anonymity: with k = 100 then any combination of insensitive attributes would only be able to narrow down to 100 people. However, as k grows larger, then we progressively lose more and more individual detail.
Limits of k-anonymity¶
Sweeney’s work of defining the property of k-anonymity was a huge step in defining a notion of privacy, but it turns out to be a rather weak notion that doesn’t give us robust guarantees about the future.
k-anonymity does not compose across datasets. Given two datasets that are individually k-anonymous, there is no guarantee that I can’t link them together to learn about an individual. The intuition for this is while each dataset guarantees you can only narrow down to k people for each dataset. However, the definition doesn’t take into account that you can potentially narrow down those two sets of k people to fewer people if you can find out commonalities between them.
k-anonymity doesn’t necessarily protect an individual from potential harms. While it’s great that k-anonymity limits the exact amount of information someone can infer about a person, it still can potentially be used against someone. For example, if you know Jose is a 63-year-old male, you know that in this dataset shown above that he either has Heart Disease or Lung Cancer. While you can’t say for certain which he has, you know he might be one of those rows. Insurance companies could use this information to deny coverage to Jose given their pre-existing conditions.
To understand how we can make some stronger privacy guarantees, we have to explore a slightly more complex and more recent notion of privacy that is employed in many real-world systems today.
US Census¶
Before trying to more formally define this more complex notion of privacy and how to achieve it, let’s watch the Minute Physics example of how privacy is applied in practice.
Here’s a summary of the talking points:
- The goal of differential privacy is to prevent the leak of confidential information about an individual. Instead of trying to anonymize individual data records, here we are publishing statistics about demographics.
- The question is whether potential linkage of different datasets can reveal private information about an individual. Given multiple datasets, differential privacy is a probabilistic definition that attempts to make the probability of a single unambiguous option for the data unlikely.
- One way of achieving this guarantee in privacy is jittering the data to provide some uncertainty in the published values. This jittering can ensure privacy (if done carefully) at the loss of accuracy—we’re intentionally adding noise to the data.
- The mathematically rigorous definition of differential privacy is expressed as ε-privacy. This notion of privacy is composable: if we publish two separate ε-private statistics, we can still guarantee 2ε-privacy. This is commonly phrased as having a fixed privacy budget for controlling the privacy of the published statistics.
Defining Privacy¶
What does it mean for a system to ensure the privacy of an individual? A slightly ambitious definition might say that a data analysis protects the privacy of the individuals if there are no risks at all for the people whose data is involved in the analysis.
In other words, this lofty goal says you can never come under harm (however we choose to define harm) by having your data present in the analysis. If we meet that definition, then we would say our analysis protects the privacy of the individuals in the analysis.
This definition is ideal, but often too ambitious in practice. To see why, let’s explore the following thought experiment outlined in The Ethical Algorithm:
Imagine a man named Roger—a physician working in London in 1950 who is also a cigarette smoker. This is before the British Doctors Study, which provided convincing statistical proof linking tobacco smoking to increased risk for lung cancer. In 1951, Richard Doll and Austin Bradford Hill wrote to all registered physicians in the United Kingdom and asked them to participate in a survey about their physical health and smoking habits. Two-thirds of the doctors participated. Although the study would follow them for decades, by 1956 Doll and Hill had already published strong evidence linking smoking to lung cancer. Anyone who was following this work and knows Roger would now increase her estimate of Roger’s risk for lung cancer simply because she knows both that he is a smoker and now a relevant fact about the world: that smokers are at increased risk for lung cancer. This inference might lead to real harm for Roger. For example, in the United States, it might cause him to have to pay higher health insurance premiums—a precisely quantifiable cost.
In this scenario, in which Roger comes to harm as the direct result of a data analysis, should we conclude that his privacy was violated by the British Doctors Study? Consider that the above story plays out in exactly the same way even if Roger was among the third of British physicians who declined to participate in the survey and provide their data. The effect of smoking on lung cancer is real and can be discovered with or without any particular individual’s private data. In other words, the harm that befell Roger was not because of something that someone identified about his data per se but rather because of a general fact about the world that was revealed by the study. If we were to call this a privacy violation, then it would not be possible to conduct any kind of data analysis while respecting privacy—or, indeed, to conduct science, or even observe the world around us. This is because any fact or correlation we observe to hold in the world at large may change our beliefs about an individual if we can observe one of the variables involved in the correlation.
It seems very difficult to actually ensure truly harmless privacy. Researchers could never run this study and say it respects privacy since it’s learning a true, but negative correlation about the world. On the other hand, in this scenario, it wasn’t the case that Roger’s participation in the study changed the outcome. Roger was just one data point out of many. The underlying trend discovered was something true about the world, not something dependent on Roger specifically. This concept of Roger’s individual participation not actually mattering in big picture outcome is the key idea behind differential privacy.
Differential Privacy¶
Differential privacy says the results of a study shouldn’t rely too much on the participation of any one individual. Think about two parallel universes, one where Roger participates in the study and one where Roger does not participate. If the results of the study are similar with and without Roger’s participation, we can say that Roger’s privacy is not violated. If Roger is the data point A in the diagram below, are the outcomes of both parallel universes are similar?
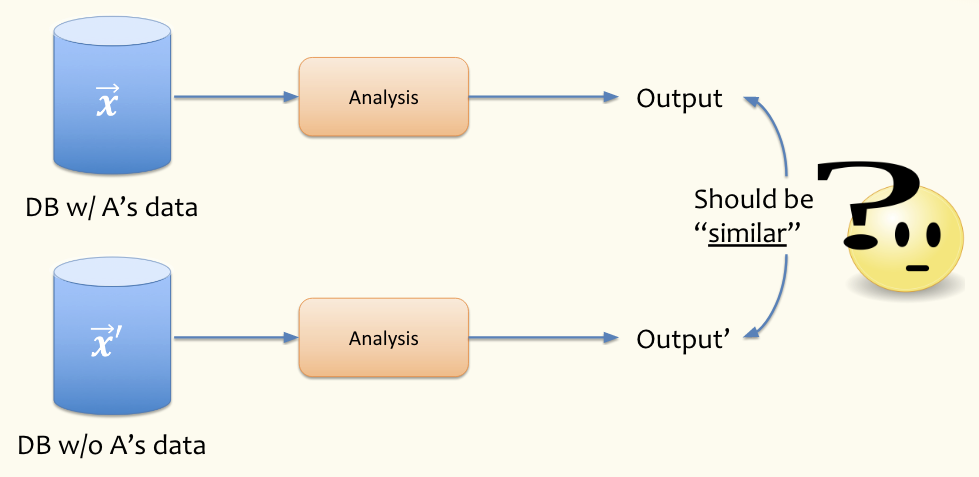
We can’t require that the output of the analysis is exactly the same since that would imply that the inclusion of people’s data doesn’t contribute any information about the analysis. Our hope is not that the outputs are identical but that they’re similar in both parallel universes with or without a particular individual’s data.
The word “differential” in “differential privacy” represents the two universes that do or don’t contain your data. A system is differentially private if the results in these two universes are similar. Differential privacy is not a “yes” or “no” question. Instead, we can fine-tune how much privacy we want.
A system can be described as -differentially private, where controls how similar we want the results.
- If we choose to be small (near 0), that means we will require that the results of the analysis must be very similar, thus enforcing a stricter notion of privacy. If , then the analysis with and without your data is exactly the same; the analysis must be independent of any person’s data!
- If we choose a larger , then more differences are allowed in the output of the analysis with and without your data, thus enabling a weaker notion of privacy.
- Informally, is the measure of the “unprivacy” budget for our system. Larger values of mean less privacy.
Optional mathematical formalism
If you’re curious how this requirement for ε-differential privacy is actually written mathematically, we write the definition out below. We can’t go into all the math behind this (e.g., what the probability is defined over), but it’s a starting point if you want to learn more!
Let be a database of individuals’ data. Let be an alternative reality version of the dataset where a single person’s data was removed. Let be some mechanism that does a computation on the database (e.g., compute an average). In otherwords, is a function that takes a database and returns the result of some computation on that database .
A mechanism is -differentially private if for all subsets , and for all databases , that differ at exactly one entry, . Note from this definition, you can see the behavior we described earlier that requires the probability of some outcome to be very similar while a larger allows the results of the two databases to vary more.
Limits of Differential Privacy¶
While differential privacy is quite strong, it is not able to guarantee the “no harm” goal that we originally tried to set up. That goal of “no harm” is too strict to feasibly meet (see our thought experiment with studying smoking and lung cancer). What differential privacy does guarantee in this scenario is that Roger’s participation or lack thereof do not impact the ultimate results of the study. It turns out this is equivalent to the condition that you can’t tell if Roger’s data was used in the result of the study. So differential privacy can protect anyone from knowing if Rodger participated in the study, but it can’t prevent the learning of some general truth about the world (smoking is linked to cancer).
We also pointed out that differential privacy is with respect to the potential removal of a single person. It says nothing about the privacy of groups of people. There are many differentially private systems used in industry to this day, from Google to Apple to Strava (fitness tracking). Many systems they use can guarantee differential privacy which means you can’t know if some individual was present in the data or not. However, this can still lead to some complications when considering groups.
Take Strava, a fitness tracking app, for example. One type of analysis that this app does is looking at heat maps of the world to find popular running locations. The system they use to analyze data is differentially private, so it’s not possible to get information about a single person’s route. It turns out that analyses like this work well in large US cities where many people have Strava devices, but things get more complicated if you look at data coming from technologically developing regions in the Global South, or from war-torn regions like Syria or Afghanistan (many people in these areas don’t have Fitbits or use Strava).
One exception to that though, is that US military personnel do operate in those regions and may be more likely to use such a device. So looking at the Strava data, you can see (in aggregate) running paths like in Afghanistan’s Helmand Province actually correspond to military bases, not all of which are supposed to be known publicly! This was a potential security hazard that was pointed out in 2018, which you can read more about at this Guardian article.
This is not a fault of differential privacy. Differential privacy (as we have defined it) is all about protecting the information of an individual in an analysis. The system is working as intended since you wouldn’t be able to look at their analysis and find information about a particular soldier in the data. But differential privacy makes no claims about how people behave in groups and doesn’t have a notion of group privacy built-in. There are extensions to differential privacy to allow for protecting groups of people, but the simple approaches people use so far work for very small groups of people, not entire platoons of soldiers.
Jittering¶
In the video about the Census, they described the process of jittering published statistics to ensure differential privacy. The act of “jittering” the data is adding some amount of random noise to the published statistics, to add uncertainty in the world about the true value.
The amount of jittering directly informs the level of differential privacy. Take the example of the Census, which is publishing demographic statistics about the US population. If the true average age of the US population is 38.1 years and we want to ensure ε-differential privacy, how much jittering do we need to introduce? We want the jittering to add a random positive or negative value to hide the true 38.1 average age, but how do we select the random number in order to ensure ε-differential privacy?
The Laplace distribution is exactly the jittering we need. The general formula for this distribution is
The graph below shows this distribution for various settings of ε. Note that it looks a lot like a normal distribution (most likely near the middle), but is a bit pointer in the center and its tails are thinner.
- The purple dotted line shows the distribution of random numbers for jittering at ε = 2.
- The blue solid line shows the distribution of random numbers for jittering at ε = 1.
- The red dashed line shows the distribution of random numbers for jittering at ε = 0.5.

Remember that ε represents the measure of “unprivacy”, so the higher the ε the more information each individual contributes to the analysis. The distribution is symmetric around 0, so it’s equally likely to randomly select a positive number as it is to select a negative number. The higher the value of ε (e.g. ε = 2 with the purple dotted line), the more likely that the random number will be closer to 0 than farther away from 0. These two facts taken together help us make sense of the charts: the taller the peak of the distribution, the more likely that the final average age after jittering will be close to the true average age.
Food for thought: How does this relate to the concept of probability distributions that we explored in Lesson 14?
Randomized Response¶
When discussing notions of privacy, we haven’t yet the issue of trust. Who do we trust to take our data and ensure it is differentially private? We might trust the Census Bureau to safeguard our data and follow the procedure they set up to ensure differential privacy. (Census takers are sworn for life to protect information that may identify individuals.) Would we trust Facebook to make sure privacy is guaranteed in our data if they promised some notion of differential privacy? What about OpenAI or Anthropic?
Implicit in discussions of privacy are discussions of trust. To use a differentially private mechanism like jittering, we have to trust the data gatherer and statistics publisher to not do wrong with our data. What if we don’t trust this party with our data? Is it possible to have another mechanism to ensure differential privacy such that we don’t have to trust some central data aggregator?
Randomized response is a mechanism for ensuring differential privacy in the absence of a trusted aggregator. Rather than jitter the statistic after collecting everyone’s private data, randomized response jitters individual data before sending it to the aggregator.
To understand the mechanism, let’s consider the task of polling the population about an embarrassing topic. Suppose I wanted to find out what percentage of people have cheated on their spouse. To conduct a poll, I would call up a random sample of the population, ask them if they have cheated on their spouse, and record the yes/no answers to get an estimate of the overall population. But people might not trust us to answer truthfully since the risk of revelation can have real impacts on their life. The incentive to tell the truth is low, and the incentive to lie is high. If we were to actually run this polling experiment, we would probably report that near 0% of respondents have cheated on their spouse due to a response bias.
A randomized response approach to this problem has each individual follow these steps when responding:
- Flip a coin (don’t tell us how it landed).
- If the coin flip is a Heads, tell us the truth on whether or not you cheated (e.g., if you have cheated, report “Yes”).
- If the coin flip is a Tails, flip the coin again.
- If the second flip comes up Heads, report “Yes”
- If the second flip comes up Tails, report “No”
If they never tell the data aggregator the outcome of the first coin flip, there is no way to tell if they are answering honestly or randomly. Even if we had a data leak from the collected data (e.g., a hacker stole all the data), every individual in the dataset has plausible deniability that their response was from the random coin flips instead of the truth!
Response Statistics¶
This system protects individual privacy, but how does it enable data analysis? The individual responds truthfully ¾ of the time. Half the time, they tell us the truth, and half of the remaining time they give us a random answer that might line up with the truth by chance, leaving only ¼ of the time where they actually lie. Suppose ⅓ of the population has cheated on their spouse. What would we expect the result of a poll to look like if that’s the case?
We would expect ⅓ of the people we called to actually have cheated on their spouse. We said earlier that each time someone responds truthfully ¾ of the time, so we would expect of the people we call to truthfully report yes if they had cheated.
But truthful cheaters are not the only places that we get “Yes” counts from. We would expect ⅔ of the people we called to not have cheated. Since we said they tell the truth ¾ of the time, that means they would randomly tell us “Yes” ¼ of the time even though that is not truthful to them not cheating. So we would expect ” of the population to report “Yes” even though they haven’t cheated.
In total, we expect of the population to report “Yes” but we don’t know if they are from the truthful group or they just said “Yes” by chance even though they didn’t cheat. We can then use this information and apply the logic backwards to go from $5/12$ to the true statistic of —assuming that we sampled enough people.
Case Studies¶
Tracking for Safety?¶
Take a read through the provided links:
- O’Sullivan, 2020. “How the cell phones of spring breakers who flouted coronavirus warnings were tracked”
- Tweet from Tectonix, one of the companies involved in making the map in the article
- Another follow-up tweet from Tectonix
The first is a CNN article from 2020 (note, at the onset of the COVID-19 pandemic, when quarantining was fairly ubiquitous and there were no vaccines available) discussing the use of phone apps to track the potential spread of COVID-19. The two tweets are also posted here verbatim:
Want to see the true potential impact of ignoring social distancing? Through a partnership with @xmodesocial, we analyzed secondary locations of anonymized mobile devices that were active at a single Ft. Lauderdale beach during spring break. This is where they went across the US: pic.twitter.com/3A3ePn9Vin
— Tectonix (@TectonixGEO) March 25, 2020
Some users pointed out concerns with this public posting of location data. They brought up questions of whether or not users consented to their data being used in this way, and if their privacy may have been violated by the posting of this analysis.
In a reply to a particular user who pointed out a concern about a potential violation of the user’s privacy (original tweet since deleted), Textronix replied:
Understand the concern, but every point of data we used here is completely anonymized and collected with user consent! We realize the implications of data collection at this scale, but used responsibly with privacy in mind, it can have massive positive effect!
— Tectonix (@TectonixGEO) March 26, 2020
This case study sets up an interesting tension between utility (i.e. public safety) and user’s privacy. On one hand, we want to have accurate information to inform policy-makers on the general behaviors of people so they can make better-informed policy decisions. But in some cases, this utility can come at the cost of someone’s personal privacy.
Food for thought:
- What did the users consent to? While the users might have consented to the collection of their data, the details of that consent are fairly important for us to consider whether using their data in a particular way is appropriate. Are the users aware of the scope of data they are actually giving away?
- The EU established the General Data Protection Regulation (GDPR) in 2016, and it is regarded as one of the strongest global privacy laws. While the full regulation is quite long, it’s worth skimming through. What protections are in place? Do you think the COVID-19 tracking map could have been created under the GDPR?
- Several more examples of location tracking are given in this older New York Times article. What examples stand out to you? Does the fact that this article came out around 7-8 years ago affect how you understand these examples?
“Rides of Glory”¶
In 2012, Uber (a ride-sharing company) wrote an engineering blog post outlining an analysis that one of their data scientists performed for fun titled “Rides of Glory.” They looked at user data for requesting rides on the app, along with the time the user ordered them to make maps of locations in San Francisco where “hookups” were more common. Many people reacted negatively to this blog post and argued that it was inappropriate for Uber to analyze their data in this way. The original blog post has been deleted by Uber, but you can read the archived version here.
We should emphasize a main point that the blog post didn’t leak any personal identifying information. Uber never revealed individually that person A hooked-up with person B since all the data was presented in aggregate (X people in this area of the city). This situation wasn’t a privacy violation in that respect since no one knew whose data was used.
However, this does bring up an essential question of consent. When users use applications, they usually consent to share some of their data with the application writer in that terms of service no one reads. You could argue that the user agreed to give up their data, so they have no right to complain about Uber using it in this type of analysis. However, it’s not clear to users that they consent to any possible use of their data for all time. Generally, people expect that companies respect the data that they provide and that companies use that data for the service they provided the information for (or used to improve the service overall).
- What consent was given by the user when the data was collected? What are the expectations around respecting privacy that are explicitly or implicitly communicated?
- Why might a user want their data to be private or used in specific applications? What might be social consequences for a person’s data to be used in this kind of analysis?
- This VentureBeat article discusses a different deleted Uber blog post in 2011 that connected Uber ride demand with neighborhood crime rates (note: the article uses the outdated term “prostitution” to refer to sex work). How does this relate to the premise and results of the “Rides of Glory” article?
⏸️ Pause and 🧠 Think¶
Take a moment to review the following concepts and reflect on your own understanding. A good temperature check for your understanding is asking yourself whether you might be able to explain these concepts to a friend outside of this class.
Here’s what we covered in this lesson:
- Anonymity
- k-anonymity
- Differential privacy
- Jittering
- Randomized response
- US Census example
Here are some other guiding exercises and questions to help you reflect on what you’ve seen so far:
- In your own words, write a few sentences summarizing what you learned in this lesson.
- What did you find challenging in this lesson? Come up with some questions you might ask your peers or the course staff to help you better understand that concept.
- What was familiar about what you saw in this lesson? How might you relate it to things you have learned before?
- Throughout the lesson, there were a few Food for thought questions. Try exploring one or more of them and see what you find.
In-Class¶
When you come to class, we will discuss the case studies in this lesson and work on completing the conceptual questions in today’s Canvas Quiz!
Canvas Quiz¶
All done with the lesson? Complete the Canvas Quiz linked here!