The content for this lesson is adapted from material by Hunter Schafer.
Objectives¶
In this lesson, let’s learn more about foundations for fairness and bias, and learn about current research in evaluating models for fairness. We will be focusing on an example of using various factors to predict admission to college. Scarcity, elitism, and social stratification are not desirable in the long term, but this example helps shed some light on the subtleties around how different people with different cultural backgrounds might define fairness in different ways. Much of this lesson draws from The Ethical Algorithm (Michael Kearns and Aaron Roth).
Setting up¶
Since this is not a coding lesson, there is no notebook to follow along with. For an offline copy of this lesson, feel free to print out this page!
Defining Fairness¶
What does it mean for an algorithm to be fair? There’s no one universal definition for fairness. Each definition is useful in different situations and reflect different social perspectives.
Group fairness is a definition of fairness that aims to avoid discrimination against subgroups. Subgroups can refer to characteristics such as race, sex, or ability but also concepts like religion, political identity, other government-protected classes, and the intersections of all these groups. A model should avoid discrimination based on membership in one of these protected groups to avoid unfair treatment.
Consider a world inhabited by people that belong to two subgroups: circles and squares. Circles make up a ⅔ majority of the population and squares a ⅓ minority of the population.

Let’s analyze a college admissions decision model that learns from historical admissions and student success data. This is clearly a very simplified abstraction of the world in order to show how things can go wrong in even simple cases. We can work with the simplified model for introducing concepts as long as we understand what has been abstracted away.
In real life, there are many more ways for things to go wrong. For example, student success as measured by course grades, graduation rates, or outcomes based on these factors will encode structural biases based on how course have been taught. Students with preparatory privilege will do better in courses that were designed with them in mind. Even the notion of student success may not be a desirable metric since it might optimize for the university’s bottom line rather than the students’ interest or the public’s interest.
Keeping in mind this already-unfair setup, let’s say the goal of the admissions process is to select students who will be successful based on past student success data in order to enroll future students who will also be successful. We have past applicant data and their student success records to train on. We’d like to predict for each student applying for the next incoming class whether to admit or deny using only their application data.
Let’s say we want to prevent discrimination against either circles or squares. One approach that we saw last time was to ignore the characteristic entirely or what we might call a “shape-blind” model. The idea is often thought that “it is impossible to discriminate if the model doesn’t even consider the characteristics.”
However, it’s still possible for models to infer certain characteristics based on subtle patterns from other features. It’s similar to how advertising might take in some search inputs and infer things about you based on those searches. By searching for a baby crib online, for example, a web advertising model might infer you’re likely to be expecting a child and target related advertisements for baby clothing and formula!
Shape-blind and other characteristic-blind approaches do not guarantee fairness since characteristics can be inferred from the other data. Instead, a common practice for defining fairness is on the outputs or decisions.
Statistical Parity¶
Statistical parity is a definition of group fairness that checks for equity in the predictions for each subgroup (and intersections of subgroups). For our running example of circle/square college admissions, statistical parity would check that the fraction of all squares admitted to college matches the fraction of all circles admitted to college. If we admit 30% of circles into our college, to meet statistical parity, we would expect to admit 30% of squares too.
But ensuring statistical parity introduces an ethical dilemma. Circles might be more likely to succeed compared to squares due to structural factors such as preparatory privilege, teaching methods, and grading methods. These differences in subgroup outcomes make it so that statistical parity can reduce accuracy on the dataset. In order to achieve statistical parity in this situation, we would deny admissions to circles at the cost of reducing overall model accuracy but understanding that the historical data does not reflect future outcomes.
If we believe that everyone can succeed given the time and support—recognizing the ways that the existing data reflect biases in higher education—random sampling might be the fairest option for college admissions. Some programs use a lottery for selecting students because they recognize that admissions is less about comparing students to identify some idealized “best students” and instead more of an issue of scarcity. In this situation, we might recommend against any kind of model and instead pursue public policy change. Not all problems need to be solved by applying technical solutions.
Equal Opportunity¶
Statistical parity does not take into account subgroup outcomes, only subgroup decisions. In contrast, equal opportunity is a definition of group fairness that checks for equity in the false-negative rates for each subgroup (and intersection of subgroups). The goal of equal opportunity is to ensure no subgroup is unfairly rejected with respect to the historical data.
A false negative refers to a single occurrence where the model predicted a negative result for a data point labeled positive. For our running example of circle/square college admissions, a false negative occurs when a student in the historical data was labeled admit but predicted as deny. The false-negative rate is the fraction of examples predicted negative but assigned a positive true label. If our dataset consisted of 5 true admits (ignoring all historical denials) and our model predicted 2 out of the 5 as deny, the false-negative rate is 0.4.
Both statistical parity and equal opportunity are definitions of group fairness. They help spot potential discrimination between subgroups but say nothing about fairness when it comes to discussing individuals within those groups, which we’ll discuss later.
Predictive Equality¶
Lastly, predictive equality is a definition of group fairness that checks for equity in the false-positive rates for each subgroup (and intersection of subgroups). A false positive refers to a single occurrence where the model predicted a positive result for a data point labeled negative. In our college admissions example, a false positive occurs when the model predicts admit for a student for which the historical data labels deny.
Food for thought: When might you use predictive equality rather than equal opportunity? Consider what false positives and false negatives mean in different contexts.
Fairness vs Accuracy¶
In our discussion of statistical parity, we alluded to a trade-off between an accurate model and a fair model. In order to achieve statistical parity, or group fairness, we might need to intentionally make errors in order to correct for structural biases present in the historical data.
Suppose we want to compare a holistic admissions process to one that is determined entirely by students’ standardized test scores. If the historical data from holistic admissions represent the true labels, let’s analyze the fairness of a simplified admissions classifier that only uses standardized test scores. The goal of this analysis is to consider whether using only standardized test scores for admissions is fair across subgroups compared to the ideal holistic admissions. (As we mentioned previously, holistic admissions may not be fair either!)
Each student is positioned on a numberline according to standardized test score (“SAT Score”), labeled + or - for the holistic admissions decision, and their belonging to either Circle (C) or Square [S] subgroups.
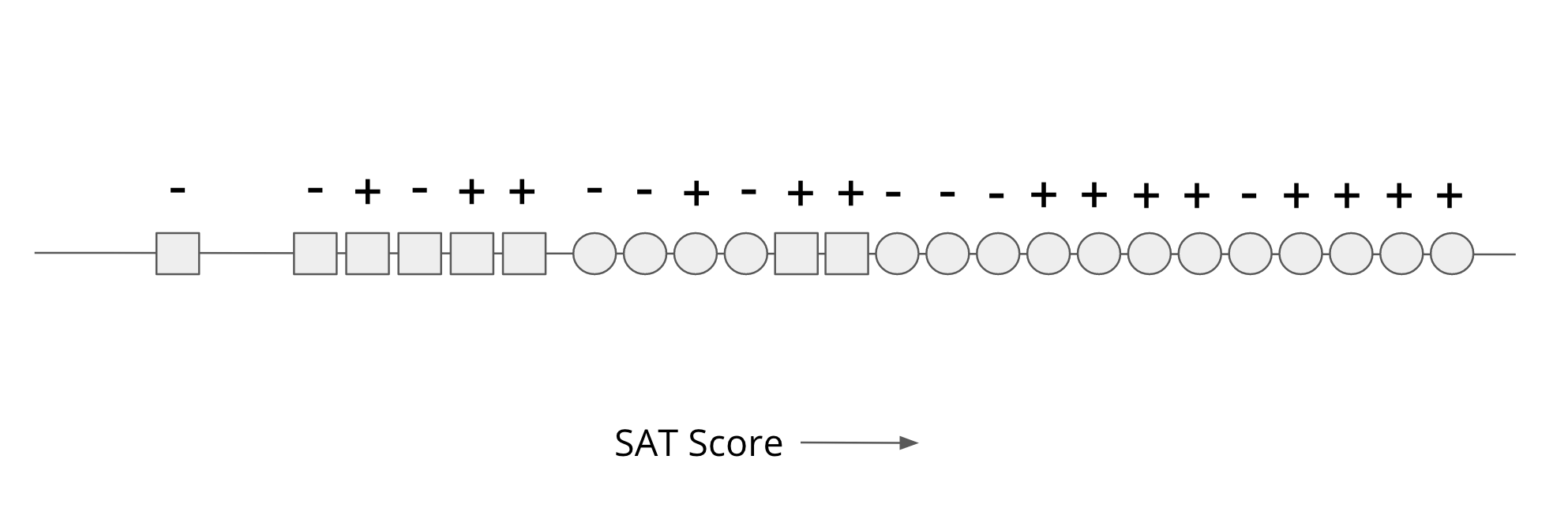
Note that a ⅔ majority of applicants are circles and ⅓ minority of applicants are squares as in our example before. Even though the number of applicants per subgroup are different, the holistic admissions data seems to have achieved some statistical parity: 9/16 circles were admitted compared to ⅝ squares. In this dataset, circles tend to have higher SAT scores than squares. (As in real life, SAT scores are biased toward certain kinds of knowledge and ways of demonstrating that knowledge.)
Our simplified admissions model is shape-blind: it only takes the SAT score as input and outputs an admit decision if the student is above a certain threshold. To maximize the accuracy of this model (reduce the number of incorrect admissions decisions), we can set the threshold value as shown below and get 17/24 correct predictions: 8 correct + positive predictions and 9 correct - negative predictions.

This “optimal” threshold is the most accurate model in terms of predictions and true labels. But if you consider our group fairness definitions, this model seems blatantly unfair. For example, this model does poorly on equal opportunity (equity of false-negative rates).
- Out of 9 successful circles, the model denied 1 of them for a false negative rate of 1/9 (11%).
- Out of 5 successful squares, the model denied all 5 of them for a false negative rate of 1 (100%).
According to equal opportunity, this model is unfair to squares since it falsely rejected successful squares at a much higher rate than the holistic admissions process that we’re using as a baseline.

A “more fair” model might move the SAT score threshold down, reducing the overall accuracy by accepting more undeserving (according to holistic admissions) circles but also finally accepting some squares.
- Out of 9 successful circles, the model denied 1 of them for a false negative rate of 1/9.
- Out of 5 successful squares, the model denied 3 of them for a false negative rate of ⅗.
The more fair model is less accurate but improves on the metric of equal opportunity.
The tension between fairness and accuracy arises from the fact that our definition of accuracy is tied to the data, which are often biased in terms of group fairness especially when the subgroup sizes are not the same. Optimizing models for accuracy will tend toward models that are more accurate for circles rather than squares because circles are overrepresented in the data.
Is there any way that we can design models that do better in both accuracy and equal opportunity? One issue is that SAT scores are themselves biased. We might try to correct this by defining one threshold for circles and another threshold for squares. This explicitly encodes shape into our model so that it can be used to determine which threshold to apply. But in the real world, such as in Washington state, there is legislation preventing the use of such models: “the state shall not discriminate against, or grant preferential treatment to any individual or group on the basis of race, sex, color, ethnicity, or national origin” (Initiative 200). These laws are important to prevent explicit discrimination but they can also prevent efforts to correct for implicit discrimination through the data used in models. Without the ability to treat subgroups separately, we will run into this trade-off between fairness and accuracy as long as there exist differences between subgroups in the historical data.
Food for thought: Which threshold do you agree with? What are the consequences of choosing either threshold?
Pareto Frontier¶
We know that models often trade-off between accuracy and (un)fairness. How do we know which model could be best for our particular problem? You could imagine looking at every possible threshold, each one operating at a different trade-off between accuracy and fairness. Picking the exact model you want ends up as an ethical dilemma. Setting aside the ethical dilemma of choosing a specific model for a moment, are some models quantitatively better than others?
The plot below visualizes trade-offs between accuracy and fairness across every possible model. The x-axis of the graph is error (1 - accuracy) while the y-axis is a measure of unfairness (higher values are less fair using some definition of group fairness). Each point in the graph represents a fully-trained model with a particular threshold (not shown). The position of each point indicates its error and unfairness compared to other models. In short, this plot shows the space of every possible model, their accuracy, and their fairness.
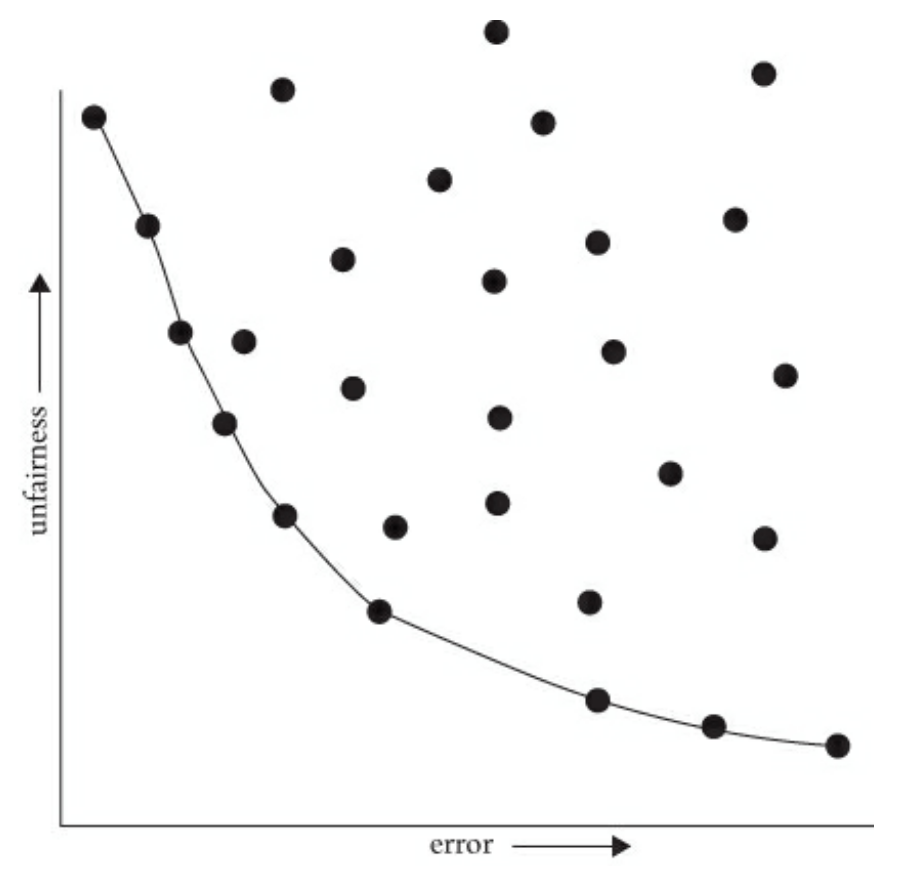
Although, in general, there is a trade-off between accuracy and fairness, some models are clearly worse in both.
- The models in the top-right quadrant exhibit both high error and high unfairness.
- The models in the bottom-right quadrant exhibit high error but low unfairness.
- The models in the top-left quadrant exhibit low error but high unfairness.
- The models in the bottom-left quadrant exhibit low error and low unfairness.
The Pareto frontier refers to the models that are optimal according to some combination of trade-offs, in this case error and unfairness. In the plot, the curve connects the points for all the models on the Pareto frontier. All points off this curve can be improved in either fairness, accuracy, or both without any loss in the other dimensions. Informally, we can say that the “best” models lie on the Pareto frontier.
The Pareto frontier does not indicate which trade-off you should choose along its curve. It just represents the set of “best” choices. The relative importance of fairness and accuracy depends on the context you are working in and it cannot make that judgment for you. In some sense, it’s just a more quantitative way of reasoning about the trade-offs, but humans are still responsible for resolving the ethical dilemma themselves.
It might feel weird to define a quantitative measure for this trade-off between fairness and accuracy. It might not feel right to treat fairness like a number along a curve that we just hand-pick! Aaron Roth and Michael Kearns describe this uncomfortable experience quite well, so let’s hear what they have to say:
While the idea of considering cold, quantitative trade-offs between accuracy and fairness might make you uncomfortable, the point is that there is simply no escaping the Pareto frontier. Machine learning engineers and policymakers alike can be ignorant of it or refuse to look at it. But once we pick a decision-making model (which might in fact be a human decision-maker), there are only two possibilities. Either that model is not on the Pareto frontier, in which case it’s a “bad” model (since it could be improved in at least one measure without harm in the other), or it is on the frontier, in which case it implicitly commits to a numerical weighting of the relative importance of error and unfairness. Thinking about fairness in less quantitative ways does nothing to change these realities—it only obscures them.
Making the trade-off between accuracy and fairness quantitative does not remove the importance of human judgment, policy, and ethics—it simply focuses them where they are most crucial and useful, which is in deciding exactly which model on the Pareto frontier is best (in addition to choosing the notion of fairness in the first place, and which group or groups merit protection under it, both of which we discuss shortly). Such decisions should be informed by many factors that cannot be made quantitative, including what the societal goal of protecting a particular group is and what is at stake. Most of us would agree that while both racial bias in the ads users are shown online and racial bias in lending decisions are undesirable, the potential harms to individuals in the latter far exceed those in the former. So in choosing a point on the Pareto frontier for a lending algorithm, we might prefer to err strongly on the side of fairness—for example, insisting that the false rejection rate across different racial groups be very nearly equal, even at the cost of reducing bank profits. We’ll make more mistakes this way—both false rejections of creditworthy applicants and loans granted to parties who will default—but those mistakes will not be disproportionately concentrated in any one racial group.
Ultimately, this reminds us of the fact that these problems in our models cannot be solved algorithmically. While we’ve tried to formalize some mathematical description for group fairness, which one you use is a statement of values and a decidedly a social question. Far too often, technologists reach towards algorithmic or technical solutions to problems, but it’s very crucial that humans (both the modeler, the modelled, and others) stay in the loop enforcing what shared values we want to encode and automate through our programming.
Food for thought: What are your takeaways from Kearns and Roth?
Worldviews¶
Our goal in this lesson was to provide some foundations for thinking about the relationships between people, data, and models by asking questions like, “What does it mean for an algorithm to be fair?” But, as we’ve seen, different mechanisms for fairness require different assumptions about the relationship between society and our models of it. Our attempts to define fairness and create fair algorithms or models is reflects and encodes our worldviews.
Read the article, The (Im)possibility of Fairness: Different Value Systems Require Different Mechanisms For Fair Decision Making, as follows:
First, read carefully the Key Insights in the box at the top of the article (pasted here).
- The world is structurally biased and makes structurally biased data. Observation is a process. When we create data, we choose what to look for.
- Every automated system encodes a value judgment. Accepting training data as given implies structural bias does not appear in the data and that replicating the data as given would be just.
- Different value judgments can require satisfying contradicting fairness properties each leading to different societal outcomes.
- Researchers and practitioners must document data collection processes, worldviews, and value assumptions.
- Value decisions must come from domain experts and affected populations; data scientists should listen to them in order to build in values that lead to justice.
Second, skim the TL;DR (too long; didn’t read) boxes on Spaces: Construct vs. Observed and Features vs. Decisions as well as Features and Non-Discrimination. Re-read the paragraphs to get context as needed.
- Constructs are the idealized features and decisions we wish we could use for decision-making. Observed features and decisions are the measurable features and outcomes that are actually used to make decisions. These may be different, and it is important to be explicit about the distinction.
- Individual fairness is the goal of giving similar individuals similar decisions.
- Non-discrimination is the goal of giving similar groups on the whole similar decisions.
Third, read carefully the section on Worldviews and Assumptions as well as Consequences. These are the key takeaways for us.
- Any attempt to design fair decision-making is forced to make assumptions about the observational process and/or construct space. There are two main such assumptions:
- Work that uses the observed data directly is making a “What you see is what you get” (WYSIWYG) assumptions; and,
- Work that attempts to guarantee statistical parity and other group fairness notions as a measure is making a “We’re all equal” (WAE) assumption.
- Under a WYSIWYG assumption, individual fairness can be guaranteed.
- Under a WAE assumption, non-discrimination can be guaranteed.
- Fairness-aware algorithms cannot guarantee fairness or non-discrimination under both the WYSIWYG and structural bias worldviews. Choice in algorithms must be tied to an explicit choice in worldview.
Finally, review the Discussion and Conclusion pasted here.
Our main claim in this work is that discussions about fairness algorithms and measures should make explicit the implicit assumptions about the world being modeled. The focus by traditional data science techniques on the observed feature and decision spaces obscures these important axiomatic issues. The default assumption in these traditional data science and machine learning domains is the WYSIWYG assumption; the data is taken as given and fully representative of the implicit construct spaces. In this work, we highlight that this WYSIWYG assumption should be made purposefully and explicitly.
When considering fairness-aware algorithms applied to a specific domain, all assumptions are not equally reasonable. There is extensive social science literature demonstrating the existence of structural bias in criminal justice, education, and other fairness-critical domains. In these domains, it is not reasonable to make the WYSIWYG assumption. Data science practitioners must work with domain experts and those impacted by resulting decisions to understand what assumptions are reasonable in a given context before developing and deploying fair mechanisms; without this work, incorrect assumptions could lead to unfair mechanisms.
Additionally, our framework suggests ways in which the current discussion of fairness measures is misleading. First, group and individual notions of fairness reflect fundamentally different underlying goals and are not mechanisms toward the same outcome. Second, group notions of fairness differ based on their implicit axiomatic assumptions: mathematical incompatibilities should be viewed as a formal statement of this more philosophical difference. And finally, and perhaps most importantly, comparing definitions of fairness is incomplete without also discussing the deployed interventions: it is the combination of measure and algorithm that describes a fully specified worldview in which the system operates.
Food for thought: How would you define the terms construct space, observed space, and decision space? How do they relate to one another?
Case Studies¶
COMPAS¶
In this case study, let’s read Larson et al.’s 2016 article, “How We Analyzed the COMPAS Recidivism Algorithm.” Here is some more context.
Several years ago, a company named Northpointe made a machine learning system to help judges decide how to rule on parole. The name of this system was the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS). The idea of the model was to try to predict how likely it would be for someone leaving jail to recommit a crime. Committing a crime after serving time in prison is called recidivism. Their model was trying to predict someone’s risk of recidivating after they leave jail from the answers to a quiz they filled out. The questionnaire asked questions about their identity, where they lived, what their job was, etc.
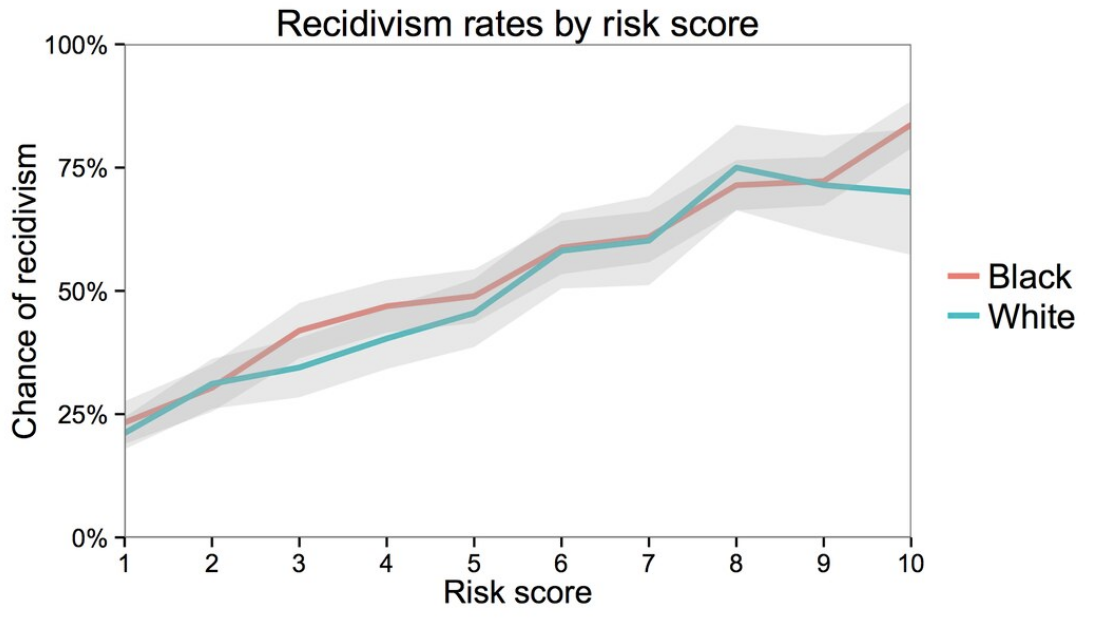
ProPublica (a non-profit newsroom) analyzed the results of COMPAS scores and concluded that the system was biased against people of color. In particular, they found that the system was more likely to predict a higher recidivism risk for black people than white people. Northpointe countered ProPublica’s findings by claiming that their scores were accurate in the sense that if they predicted a score of 9 for anyone (regardless of race), there was a 90% chance they would recidivate.
So the question then is: Which one of these groups is right, and is it ethical to use this system to determine who gets parole? Surprisingly, it turns out that both ProPublica and Northpointe’s arguments are backed up by the data.
Northpointe’s argument is backed up by the following graph. The x-axis shows the predicted risk score (scaled from 1-10, where a higher is more likely to recidivate). The y-axis shows the actual recidivism rate for those people after they did leave jail. The fact that these lines are close to the line demonstrates Northpointe’s point. So of the people that they predict a risk score of 0.8, about 80% of the time they recidivate. Additionally, when separated as accuracies for black and white people, you see that the lines are mostly the same (the gray region is a confidence interval to capture uncertainty in the estimate).
ProPublica’s point is backed up by the following chart. This chart separates the data into black/white people and then within those groups breaks the people up into low and medium/high risk and shows the count of each group. The risk group comes from whether or not COMPAS predicted a small, medium, or high score. The coloring shows which of the people in each group did re-offend and those that didn’t. ProPublica claims that the percentage of people shaded dark blue (those that ultimately did not re-offend) in each race, a more substantial proportion of black people get labeled as medium/high risk. The conclusion from this claim is that if you would genuinely not recidivate, the system is more likely to give you a higher risk if you’re black. They use this as justification to say this model exhibits racist behavior and that judges shouldn’t use it.

The first thing to ask is, where does this bias come from? Surprisingly, it turns out that race isn’t even a question that Northpoint asked on the questionnaire. This means that the model doesn’t even have race as an input. This doesn’t stop the model though, because it’s able to do many correlations to “discover” someone’s race using other features (like their home address, income level, name, etc.). These features can be correlated with race, so the model is not truly “color-blind.”
In many cases, models that show biased behavior tend to not do so intentionally on the part of the programmer. Unfortunately, the data we give these models is biased because our society has biases around every corner. Regardless of using a machine learning model or not, your treatment by the criminal justice system is, unfortunately, impacted by your race. If we use data from this biased system, the data itself will obviously be biased. The model can then pick up on these biases and reflects them in their decisions. Just as a simple example, the relative incarceration rate for people of color is much higher than white people. The model picks up on this correlation and then uses it for future judgments, without taking into account the historical or societal causes for that difference.
Food for thought:
- One idea to counter-act systemic racism into models like COMPAS is to explicitly code race into the model, and then make some mechanism to force the model to be fair concerning race. However, in many places, this is illegal to do in the first place! How would you respond to this idea?
- Consider the false positives and false negatives in this scenario. What are the risks associated with each, and what would you use to guide your idea of fairness in this case study?
- Loomis v. Wisconsin was a 2017 court case that challenged the state of Wisconsin’s use of COMPAS to sentence a man named Eric Loomis to six years in prison. Read this statement from the Harvard Law Review and reflect on the judges’ decision. Why did the court accept the result from COMPAS? What are the criticisms made of this decision?
Predicting Criminality¶
For this case study, we’ll read Bergstrom and West’s 2017 article “Criminal machine learning”. Here are the takeaways:
Physiognomy is the idea that a person’s character or tendencies can be read or determined from their physical appearances, particularly around the head and face. (This is deeply intertwined with the broader concept of scientific racism, which is a historical pattern of using “empirical” data to justify racial discrimination and hierarchies.) The paper that Bergstrom and West are criticizing attempts to revive the idea that there is any theory of “criminal” facial features at all, and further that the distinguishing algorithm is free from human bias because it is automated.
A machine learning algorithm is only as reliable as the data it is trained on. If the training data contains systematic differences unrelated to what the algorithm is supposed to detect, the algorithm will learn those differences instead. Further, Wu and Zhang confounded facial features like bone structure and proportions with facial expressions, which are temporary muscular configurations. Using convictions as a proxy for criminality also introducecs another layer of bias. Setting aside that convictions do not have a one-to-one mapping with whether a person committed a crime, facial features may correlate with jury decisions to convict over actually committing crimes.
Data scientists use models to not only make predictions but also to justify some phenomena (e.g., an interpretable machine learning model). While this is a useful endeavor, it can have some downfalls. This is why it’s so important to explore alternative hypotheses (maybe simpler ones) that are also likely to explain the phenomena. It would be best if you took the time to reflect on your explanation to check for any implicit biases present (e.g., confirmation bias). While it’s hard to spot implicit biases, taking time to critically reflect can help catch them.
It’s incredibly important to start any data analysis project by asking who will use its results. Is it possible for someone to use this model to the detriment of others’ health, safety, or privacy? In the case of predicting criminality, there are some pretty scary possibilities of people in power abusing a tool like this to algorithmically enforce historic biases.
In general, it can be a bit tricky to navigate discussions of risk and value: It’s probably the case that you could argue that anyone can use any tool to cause harm, but that doesn’t mean we should never make new tools. It can help to think about the negatives in contrast to the value a tool adds to the world (e.g., think about the negatives of not using that tools). If there is an excellent argument for value-added, then the calculus on risk-reward will be more difficult to navigate. It’s tricky to navigate since different people have different views on injury and value, but having that discussion in the first place is a critical first step.
Food for thought:
- How would you define the construct space, the observed space, and the decision space in this study?
- The original paper that Wu and Zhang published can be found at this link. What stands out to you about their study? How does reading the Bergstrom and West critique of the paper first affect your perception of it?
- Wu and Zhang published a response paper to the critiques of their original study. How would you summarize their response? What similarities or differences do you see in the points made in their response and the criticisms that Bergstrom and West wrote?
⏸️ Pause and 🧠 Think¶
Take a moment to review the following concepts and reflect on your own understanding. A good temperature check for your understanding is asking yourself whether you might be able to explain these concepts to a friend outside of this class.
Here’s what we covered in this lesson:
- Fairness
- Group fairness / statistical parity
- Equal opportunity
- Predictive Equality
- Pareto frontier
- Worldviews
- WYSIWYG
- WAE
Here are some other guiding exercises and questions to help you reflect on what you’ve seen so far:
- In your own words, write a few sentences summarizing what you learned in this lesson.
- What did you find challenging in this lesson? Come up with some questions you might ask your peers or the course staff to help you better understand that concept.
- What was familiar about what you saw in this lesson? How might you relate it to things you have learned before?
- Throughout the lesson, there were a few Food for thought questions. Try exploring one or more of them and see what you find.
In-Class¶
When you come to class, we will discuss the case studies in this lesson and work on completing the conceptual questions in today’s Canvas Quiz!
Canvas Quiz¶
All done with the lesson? Complete the Canvas Quiz linked here!