for (String word : count.keySet()) {
// process word
}
We would read this as, "for each String word that is in count.keySet()..."
To process the word, we simply print it out along with its count. How do we
get its count? By calling the get method of the map:
for (String word : count.keySet()) {
System.out.println(count.get(word) + "\t" + word);
}
I didn't try to print all of the words in Moby Dick because it would
have produced too much output. Instead, I had it show me the counts of words
in the program itself. Obviously for large files we want some mechanism to
limit the output. On the calendar I will put a version that includes some
extra code that asks for a minimum frequency to use. We ran that on Moby
Dick and saw this list of words that occur at least 500 times:
What is the name of the text file? moby.txt
Minimum number of occurrences for printing? 500
4571 a
1354 all
587 an
6182 and
563 are
1701 as
1289 at
973 be
1691 but
1133 by
1522 for
1067 from
754 had
741 have
1686 he
552 him
2459 his
1746 i
3992 in
512 into
1555 is
1754 it
562 like
578 my
1073 not
506 now
6408 of
933 on
775 one
675 or
882 so
599 some
2729 that
14092 the
602 their
506 there
627 they
1239 this
4448 to
551 upon
1567 was
644 were
500 whale
552 when
547 which
1672 with
774 you
One final point I made about the Map interface is that you can associate
just about anything with just about anything. In the word counting program, we
associated strings with integers. You could also associate strings with
strings. One thing you can't do is to have multiple associations in a single
map. For example, if you decide to associate strings with strings, then any
given string can be associated with just a single string. But there's no
reason that you can't have the second value be structured in some way. You can
associate strings with arrays or strings with Lists.Then I mentioned that I wanted to explore a sample program that will constitute a medium hint for the programming assignment. We will begin looking at the program in this lecture and finish it up in the next lecture.
The sample program involves keeping track of friendships. You could think of it as keeping track of Facebook friends. One of the first questions that comes up is how do we represent friendships? For example, are friendships bidirectional? If person A is friends with person B, does that mean that person B is friends with person A? For our purposes, we will assume the answer is yes. If we were trying to represent something like "is attracted to", then we'd come to a different conclusion, but for friends, just like on Facebook and other social networking sites, friendship goes both ways.
I said that a good way to visualize friendships is to draw a graph in which each person is represented with a node (an oval) and each friendship is represented by an edge connecting two nodes (a line drawn between two ovals). I am using a program called Graphviz, which is an open-source graph viewer.. For example, here is a sample friendship graph:
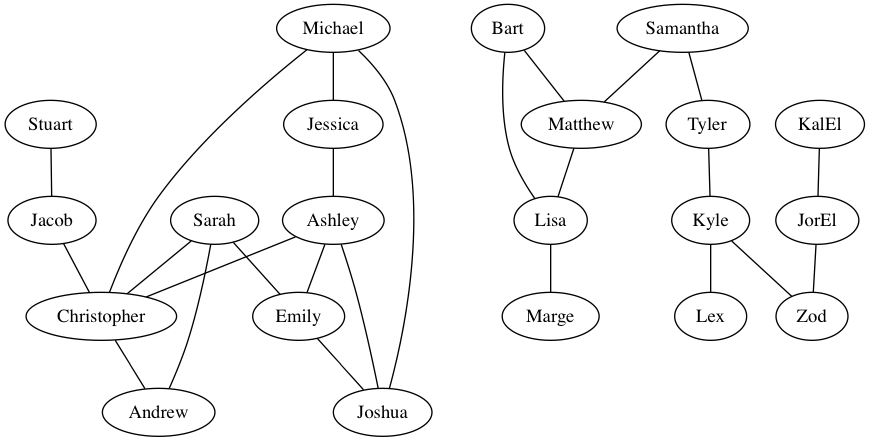
This information is stored in a file with lines that list pairs of friendships, as in:
graph {
Ashley -- Christopher
Ashley -- Emily
Ashley -- Joshua
Bart -- Lisa
Bart -- Matthew
Christopher -- Andrew
Emily -- Joshua
Jacob -- Christopher
Jessica -- Ashley
JorEl -- Zod
KalEl -- JorEl
Kyle -- Lex
Kyle -- Zod
Lisa -- Marge
Matthew -- Lisa
Michael -- Christopher
Michael -- Joshua
Michael -- Jessica
Samantha -- Matthew
Samantha -- Tyler
Sarah -- Andrew
Sarah -- Christopher
Sarah -- Emily
Tyler -- Kyle
Stuart -- Jacob
}
Then I demonstrated what the Friends program is supposed to do. It is supposed
to use this data to find how far one person is from another. So starting with
a given person, it finds that person's friends, then the friends of those
friends, then the friends of the friends of the friends, and so on. It reports
how far it has to go to find a connection and if it runs out of people, it
simply reports that the connection couldn't be found.For example, here is a sample execution using our data file for finding the connection between Ashley and Stuart:
Welcome to the cse143 friend finder.
starting name? Ashley
target name? Stuart
Starting with Ashley
1 away: [Christopher, Emily, Jessica, Joshua]
2 away: [Andrew, Jacob, Michael, Sarah]
3 away: [Stuart]
found at a distance of 3
It finds that Ashley has four direct friends (Christopher, Emily, Jessica, and
Joshua). Those friends have four friends (Andrew, Jacob, Michael, Sarah).
Those four friends have a friend named Stuart. So the program reports that it
found Stuart 3 away from Ashley.Here is a sample execution where the connection is not found, asking for a connection between Stuart and Bart:
Welcome to the cse143 friend finder.
starting name? Stuart
target name? Bart
Starting with Stuart
1 away: [Jacob]
2 away: [Christopher]
3 away: [Andrew, Ashley, Michael, Sarah]
4 away: [Emily, Jessica, Joshua]
5 away: []
not found
The program goes two levels farther than it did before, finding that it runs
out of people when it gets 5 away from Stuart. At that point it knows that
there is no connection between Stuart and Bart.We looked at one more example that involved a fairly long chain:
Welcome to the cse143 friend finder.
starting name? Bart
target name? JorEl
Starting with Bart
1 away: [Lisa, Matthew]
2 away: [Marge, Samantha]
3 away: [Tyler]
4 away: [Kyle]
5 away: [Lex, Zod]
6 away: [JorEl]
found at a distance of 6
I asked people what kind of structure would be useful for keeping track of this
kind of data and someone said a map. But what kind of map? Someone suggested
that it would be good to keep track of the neighbors for each person. The
neighbors are the friends. For example, Ashley's friends are Christopher,
Emily, Jessica, and Joshua.If we want a structure that keeps track of these kind of friendships, then we want to use names as keys into the structure. We ask the structure, "Who are the friends of Samantha?" or "Who are the friends of Ashley?". So a name, a String, will be used as the key. But what should it return? If we map a String to a String, then we can store only one friendship. We want to be able to return more than one friendship. Someone suggested that we want to use a set. That is exactly right.
The idea is that we want to have a map that converts a String into a Set of String values. Given the name of a person, we can get a Set with the names of that person's friends. For our sample file:
"Andrew" => maps to => [Christopher, Sarah]
"Ashley" => maps to => [Christopher, Emily, Jessica, Joshua]
"Bart" => maps to => [Lisa, Matthew]
"Christopher" => maps to => [Andrew, Ashley, Jacob, Michael, Sarah]
"Emily" => maps to => [Ashley, Joshua, Sarah]
"Jacob" => maps to => [Christopher, Stuart]
"Jessica" => maps to => [Ashley, Michael]
"JorEl" => maps to => [KalEl, Zod]
"Joshua" => maps to => [Ashley, Emily, Michael]
"KalEl" => maps to => [JorEl]
"Kyle" => maps to => [Lex, Tyler, Zod]
"Lex" => maps to => [Kyle]
"Lisa" => maps to => [Bart, Marge, Matthew]
"Marge" => maps to => [Lisa]
"Matthew" => maps to => [Bart, Lisa, Samantha]
"Michael" => maps to => [Christopher, Jessica, Joshua]
"Samantha" => maps to => [Matthew, Tyler]
"Sarah" => maps to => [Andrew, Christopher, Emily]
"Stuart" => maps to => [Jacob]
"Tyler" => maps to => [Kyle, Samantha]
"Zod" => maps to => [JorEl, Kyle]
Our first challenge, then, is to write code to construct such a structure. If
it maps a String to a Set<String>, then it would be of this type:
Map<String, Set<String>>
To construct one, we have to ask for a new TreeMap of this type:
Map<String, Set<String>> friends = new TreeMap<String, Set<String>>();
That is a rather complex line of code, but the main complexity comes from what
we are putting inside the "<" and ">" characters.To fill up this structure, we need to process the input file. Remember that the input file has lines that have two names separated by a "--", as in:
Ashley -- Christopher
I showed the following code to read lines of input and find the ones that
contain names:
while (input.hasNextLine()) {
String line = input.nextLine();
if (line.contains("--")) {
Scanner lineData = new Scanner(line);
String name1 = lineData.next();
lineData.next(); // this skips the "--" token
String name2 = lineData.next();
// process name1 and name2
}
}
This was not the interesting part of the code because we saw file processing in
cse142. The interesting part is to think of how to process the two names. How
do we update our friends map given a new friendship? Friendships are
bidirectional, so we have to be careful to add the friendship in both
directions. If there is an Ashley--Christopher friendship, then we have to
make sure that Ashley's set of friends includes Christopher and we have
to make sure that Christopher's set of friends includes Ashley.I mentioned that this is a good place to introduce an extra method because we're going to do the same thing twice. So we replaced the comment above with the following two lines of code:
addTo(friends, name1, name2);
addTo(friends, name2, name1);
So then we turned to the task of writing the addTo method. It takes the map
and the two names as parameters, so it looks like this:
public static void addTo(Map<String, Set<String>> friends, String name1,
String name2) {
...
}
So far in our code we have constructed one object--the map. I asked the class
what the map's size is and the answer is 0. We constructed the map, but never
added anything to it.Then we thought about the first call to addTo when name1 is "Ashley" and name2 is "Christopher". Someone pointed out that we need a set to keep track of Ashley's friends, so we wrote this line of code:
Set<String> theFriends = new TreeSet<String>();
The first thing we need to do is to set up the association in the map between
Ashley's name and this set:
friends.put(name1, theFriends);
Now the map has a size of 1. The set still has a size of 0. That's because we
never added anything to the set. We'll get there. The following diagram
indicates where we are now:
friends ==> {"Ashley" ==> []}
The map has one entry that keeps track of the fact that the name "Ashley" is
associated with an empty set. We don't want that set to be empty. We want to
add "Christopher" to that set, so we included this line of code:
theFriends.add(name2);
That leaves us in this situation:
friends ==> {"Ashley" ==> ["Christoper"]}
Putting the lines of code together, we have:
Set<String> theFriends = new TreeSet<String>();
friends.put(name1, theFriends);
theFriends.add(name2);
We have added one entry to the map for Ashley and recorded her friend
Christopher. Then we make a second call on addTo with the names reversed. We
end up creating another set. We told the map to associate Christopher's name
with this new set. And we told the set to remember that Ashley is one of
Christopher's friends. That leaves us in this state:
friends ==> {"Ashley" ==> ["Christoper"],
"Christopher" ==> ["Ashley"]}
Think about what happens next. The input file has the pairing "Ashley" and
"Emma". Suppose we execute the exact same three lines of code again. The
first thing we would do is to create a brand new set for keeping track of
Ashley's friends. But we already have a set for keeping track of Ashley's
friends. Only that set knows that Christopher is one of Ashley's friends. If
we make a brand new set, we'll only know about the new friendship.The question is how to get back to the original set. The answer is to talk to the map to ask for its entry for Ashley. We can store this information in a variable by saying:
Set<String> theFriends = friends.get(name1);
We now want the set to also remember that Emma is a friend of Ashley. So we
say:
theFriends.add(name2);
This leaves us with the following situation:
friends ==> {"Ashley" ==> ["Christoper", "Emma"],
"Christopher" ==> ["Ashley"]}
That completes what we want to do for this call on addTo. Then we call addTo
again with the names reversed. That means that name1 is "Emma". The map has
no entry for Emma, so we go back to executing the three lines of code we had
before. We construct yet another set to keep track of Emma's friends. Then we
tell the map to associate "Emma" with this set. And then we tell the newly
constructed set to add "Ashley" to the set. That leaves us in this state:
friends ==> {"Ashley" ==> ["Christoper", "Emma"],
"Christopher" ==> ["Ashley"],
"Emma" ==> ["Ashley"]}
We still have just one object keeping track of all of this data. Our map is
filling that role. But inside the map, it keeps references to the three sets
we constructed. One set is keeping track of Ashley's friends and now has two
entries. A second set records the fact that Christopher has a friend named
Ashley. And the third set records the fact that Emma has a friend named
Ashley.To figure out when to execute the three lines of code versus when to execute the two lines of code we can use an if/else just as we did in the word counting program to choose between the two cases by checking whether the map already contains name1 as a key:
if (!friends.containsKey(name1)) {
Set<String> theFriends = new TreeSet<String>();
friends.put(name1, theFriends);
theFriends.add(name2);
} else {
Set<String> theFriends = friends.get(name1);
theFriends.add(name2);
}
In the next lecture we will discuss how this can be simplified, but for now,
this is a reasonable way to write the code.This completes the task of constructing the friends map. A simple way to see what is in the map is to print it in main:
Map<String, Set<String>> friends = readFile(input);
System.out.println(friends);
The output is hard to read, but if you look closely, you'll see that it is
correctly capturing all of the friendship relationships:
{Andrew=[Christopher, Sarah], Ashley=[Christopher, Emily, Jessica,
Joshua], Bart=[Lisa, Matthew], Christopher=[Andrew, Ashley, Jacob,
Michael, Sarah], Emily=[Ashley, Joshua, Sarah], Jacob=[Christopher,
Stuart], Jessica=[Ashley, Michael], JorEl=[KalEl, Zod], Joshua=[Ashley,
Emily, Michael], KalEl=[JorEl], Kyle=[Lex, Tyler, Zod], Lex=[Kyle],
Lisa=[Bart, Marge, Matthew], Marge=[Lisa], Matthew=[Bart, Lisa,
Samantha], Michael=[Christopher, Jessica, Joshua], Samantha=[Matthew,
Tyler], Sarah=[Andrew, Christopher, Emily], Stuart=[Jacob],
Tyler=[Kyle, Samantha], Zod=[JorEl, Kyle]}
I included a version of this part of the code on the calendar. We will
complete this program in the next lecture.
Stuart Reges Last modified: Wed Oct 25 16:41:58 PDT 2023