Due Date: Thu, Feb 18, 2010 copy of the
report in class and submit code online (the 7th week)
|
- Bayesian learning
- 1.1. [Based on a real experience] UltraClear 2009W is a
best selling LCD monitor model from the company Kell. It uses the
top-quality IPS LCD panels -- the same technology used in the
iPad. Due to the bad economy, in an act to reduce the cost, Kell
decides to switch most of its UltraClear 2009W monitors over to
cheaper but lower-quality PVA panels. As a result, only 10% of
UltraClear 2009W monitors now use IPS panels. Consumers are definitely
not happy. They want the IPS panels. However, the difference between
the two types of panels are too subtle for the eyes to
tell. Fortunately, there are some other clues. We now know that 80% of
the IPS version are made in Mexico and only 10% of the PVA version are
made in Mexico. So, if you see in store a UltraClear 2009W made in
Mexico, what is the probability that it uses a IPS panel?
Another clue is the product serial number. We know that 99%
of the IPS version have serial numbers ending with letter "L" and only
1% of the PVA version have such serial numbers. Suppose the same
monitor that you see in the store (made in Mexico) has a serial number
"IERY2009123457L", what is the probability that it uses a IPS panel?
Assume that the serial number and the country of origin are
independent of each other given the panel type.
- 1.2. Consider the following Bayesian network:
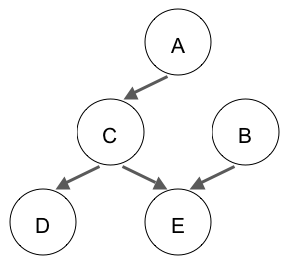
- Is A independent of B?
- Is D independent of E?
- Is D independent of A given C?
- Is A independent of B given E?
- Is D independent of E given C?
Justify your answers.
- 1.3. Consider a Bayesian network with four Boolean nodes
A, B, C, and D, where A is the parent of B, and B is the
parent of C and D. Suppose you have a training set composed of
the following examples in the form (A,B,C,D), with "?"
indicating a missing value: (0,1,1,1), (1,1,0,0), (1,0,0,0),
(1,0,1,1), (1,?,0,1). Show the first iteration of EM algorithm
(initial parameters, E-step, M-step), assuming the parameters
are initialized ignoring missing values.
- Neural networks
- 2.1. Mitchell problem 4.8.
- 2.2. Mitchell problem 4.10.
- Spam filtering.
- The dataset we will be using is a subset of 2005 TREC
Public Spam Corpus. You can download it
here. It contains a training set and a test set. Both
files use the same format: each line represents the
space-delimited properties of an email, with the first one
being the email ID, the second one being whether it is a spam
or ham (non-spam), and the rest are words and their occurence
numbers in this email. In preprocessing, I removed non-word
characters, and conducted feature selection similar to what
Mehran Sahami did in
his original
paper using Naive Bayes to classify spams, though with
larger cut-offs since our corpus is larger.
- Implement both the multinomial naive Bayes algorithm and
the perceptron algorithm to classify spam. Use your algorithm
to learn from the training set and report accuracy on the test
set. You may program in C, C++, Java or Matlab. If you'd like
to use another language, ask TA first.
- Try various smoothing parameters for the Naive Bayes
learner and different learning rates for perceptron. Which
parameters work best? How many iterations does it take for
perceptron learning to converge? Which algorithm performs
better? Which one learns faster?
- (Extra credit 10%) Our feature selection makes learning
much easier, but it also throws out useful information. For
example, exclamation mark (!) often occurs in spams. Even the
format of email sender matters: in the case when an email
address appears in the address book, a typical email client
will replace it with the contact name, which means that the
email is unlikely to be a spam (unless, of course, you are a
friend of the spammer :-). Sahami's paper talked about a few
such features he had used in his classifier. For extra credit,
you can play with
the original
files and come up with useful features that improve your
classifier. Here are the lists of the
files used in train/test.
-
Turn in the following:
- Your code for Problem 3. Submit your
files here. The
due date is 12 noon, Feb 18, 2010. Your code should
contain appropriate comments to facilitate understanding.
- A report with your answers to the homework problems. For
problem 3, as usual, you should describe in high-level how your
code works, what is the accuracy of your results; if your accuracy
is low, analyze the errors and explain what you think might be the
cause and what changes can be made for improvement.
Good luck, and have fun!
|