Due Date: Monday, May 19, 2008 in class and submit code online (the eighth week)
|
- Bayesian learning
- 1.1. Down syndrome is a genetic disorder caused by an extra chromosome in the DNA. In U.S., its incidence rate is estimated to be about one out of 733 births. AFP/free beta screen, a noninvasive prenatal screening, can detect about 80% of Down syndrome cases, but also returns positive in about 2.8% of healthy cases due to various reasons (e.g., normal variation in protein level). If a mother was told that her AFP test result is positive, what is the probability that her baby has Down syndrome?
Invasive tests such as amniocentesis take amniotic fluid and directly analyze the DNA, which are labor-intensive and carry a small risk of causing miscarriage, but it can detect over 99.8% of Down syndrome cases with a very low false positive rate (say, 0.1%). Amniocentesis is usually conducted when the AFP result is positive. Now suppose that the amniocentesis test result was also positive for the unfortunate mother above, what's the probability for Down syndrome? Assume that the two test results are independent of each other given the presence or absence of Down syndrome.
- 1.2. Consider the following Bayesian network:
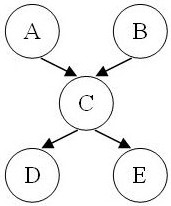
- Is A independent of B?
- Is D independent of E?
- Is D independent of A given C?
- Is A independent of B given C?
- Is D independent of E given C?
Justify your answers.
- 1.3. Consider a Bayesian network with four Boolean nodes A, B, C, and D, where A is the parent of B, and B is the parent of C and D. Suppose you have a training set composed of the following examples in the form (A,B,C,D), with "?" indicating a missing value: (0,1,1,1), (1,1,0,0), (1,0,0,0), (1,0,1,1), (1,?,0,1). Show the first iteration of EM algorithm (initial parameters, E-step, M-step), assuming the parameters are initialized ignoring missing values.
- Neural networks
- 2.1. Duda et al. Chapter 6, problem 4.
- 2.2. Mitchell problem 4.10.
- Spam filtering.
- The dataset we will be using is a subset of 2005 TREC Public Spam Corpus. You can download it here. It contains a training set and a test set. Both files use the same format: each line represents the space-delimited properties of an email, with the first one being the email ID, the second one being whether it is a spam or ham (non-spam), and the rest are words and their occurence numbers in this email. In preprocessing, I removed non-word characters, and conducted feature selection similar to what Mehran Sahami did in his original paper using Naive Bayes to classify spams, though with larger cut-offs since our corpus is larger.
- Implement both the multinomial naive Bayes algorithm and the perceptron algorithm to classify spam. Use your algorithm to learn from the training set and report accuracy on the test set. You may program in C, C++, Java or Matlab. If you'd like to use another language, ask Hoifung first.
- Try various smoothing parameters for the Naive Bayes learner and different learning rates for perceptron. Which parameters work best? How many iterations does it take for perceptron learning to converge? Which algorithm performs better? Which one learns faster?
- (Extra credit 10%) Our feature selection makes learning much easier, but it also throws out useful information. For example, exclamation mark (!) often occurs in spams. Even the format of email sender matters: in the case when an email address appears in the address book, a typical email client will replace it with the contact name, which means that the email is unlikely to be a spam (unless, of course, you are a friend of the spammer :-). Sahami's paper talked about a few such features he had used in his classifier. For extra credit, you can play with the original files and come up with useful features that improve your classifier. Here are the lists of the files used in train/test.
- For those who are interested in adversial classification, the emerging theme for spam detection, here is a nice KDD-04 paper from UW. Last year, NIPS (a very popular machine learning conference) hosted a workshop on adversial learning.
-
Turn in the following:
- Your code for Problem 3. Submit your files here. The due date is 12PM, May 19, 2008. Your code should contain appropriate comments to facilitate understanding.
- A report with your answers to the homework problems. For problem 3, as usual, you should describe in high-level how your code works, what is the accuracy of your results; if your accuracy is low, analyze the errors and explain what you think might be the cause and what changes can be made for improvement.
Good luck, and have fun!
|