The Kernel
UNIX-like systems have a kernel, which contains device drivers, file
systems, networking stacks, memory managment, and CPU scheduling
code. The kernel also provides support for user-level processes, the
purpose of which is to run an arbitrary program.
Processes
A process is a single, active, invocation of a program. There are
usually dozens of processes on a UNIX machine, each with a specific
purpose. For example, login(1) is responsible for
authenticating users (by checking a username/password combination) and
starting a shell. A single kernel may be running several different
processes with the same program (e.g. we are all running
emacs(1) on spinlock).
What data makes up a process?
A process consists of all the state needed to run a UNIX program. Some
of this state is stored in the CPU registers and the allocated
memory. The kernel also maintains a Process Control Block (PCB)
for each process (Linux calls this a task_struct; it's
defined in sched.h).
The PCB contains all the internal state that the kernel uses to
provide the process abstraction, including a list of open files, the
user ID that the process is running as, and scheduling information.
The PCB is not directly accessible to user programs. We might draw
this all as:
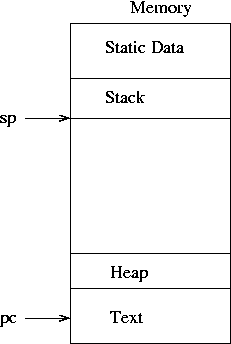

The text segment is the UNIX term for the program's code in
machine language. Note that, while I've included arrows for the SP
(stack pointer) and PC (program counter) on the memory drawing, the SP
and PC are actually stored in CPU registers.
How does a process get created?
Any process can create a new process by making a request to the
kernel. For example, I might request that my shell [1] create a new mail(1) process by
typing the text 'mail\n' at a prompt. The shell translates this
command into a series of system calls, which, as we'll see, winds up
creating a new process running the mail program. (The kernel
creates init(8), the first process, at boot. The kernel never
spontaneously creates any other processes.)
Under UNIX, two main system calls are used by the shell to execute my
command: first, the shell clones itself using the fork(2)
syscall; then, this clone replaces itself with the mail program using
the exec(3) syscall. Kind of strange, but it turns out to be
quite useful.
fork(2)
The function of fork(2) is to create an almost exact
duplicate of the process that calls it. So, if we had the above
diagram before the process invoked the fork syscall, then the diagram
afterward would look like:

Most fields of the PCB are copied from the original to the newly
created PCB; they are starred and shown in blue above (we'll call the new process the
child and the old the parent from now on). The parent's
memory is also copied [2]. Note that the
PC of both processes is exactly the same.
Eventually, the kernel will get around to running these two processes.
(Which one first? That's undefined; either could run first.) When this
happens, the process (be it child or parent) will continue from it's
saved PC. Since the process just executed the fork syscall,
the PC will point to whatever instruction is immediatly following it.
Readers may have noticed a problem at this point. The processes are
both exactly the same. When the kernel runs one, it'll do some stuff
(whatever the instructions after the fork tell it to
do). Then, when the other one runs, it'll do...the exact same
thing. That's not too useful.
To get around this, the processes differ in a very slight but
important way. The return value of the fork syscall will be 0 in the
child process, and will be greater than 0 in the parent. We can use
this to have the parent take one code-path while sending the (almost
identical) child down a different path.
To summarize, immediatly after executing a fork:
- There are 2 processes that are exactly the same, except for the
differences described in the fork(2) man page.
- Both processes are at the same line of code (the line immediatly
after the fork).
- In the child process, the return value of the fork is 0.
- In the parent process, the return value of the fork is
greater than 0.
exec(3)
So we now have two copies of the shell. But they are still both
running the shell program; we want the child to run the
mail(1) program. The child uses another syscall,
exec(3), to replace itself with the mail
program. exec does not create a new process; it just changes
the program file that an existing process is running.
exec first wipes out the memory state of the calling
process. It then goes to the filesystem to find the program file
requested. exec copies this file into the program's memory
and initializes register state, including the PC.
exec doesn't alter most of the other fields in the PCB - this
is important, because it means the process calling exec(3)
(the child copy of the shell, in this case) can set things up if it
wants to, for example changing the open files or other user ID[3].
At this point we've still got two processes, but now one (the parent)
is the shell, and the other (the child) is mail(1). The
kernel will run both of them, making sure each gets a bit of
processing time. It is likely the case that the shell wants to wait
for the mail (child) process to finish before doing anything
else; it can tell the kernel this using the wait(2) syscall.
Footnotes
[1] The shell is itself a process. What
process created it? That depends on how I'm logged in. If I'm at the
console (that is, sitting at the machine itself) then the
login(1) process creates a shell for me after I supply a
valid username/password (the login(1) man page contains a
nice description of this procedure). If I'm logged in remotely -- say
using ssh(1) -- a similar process would happen, but the
sshd(8) (the server process that accepts ssh connections from
remote clients) would create the shell for me after I connected and
authenticated. What program is launched when either login(1)
or sshd(8) needs to make a new shell is determined by the
user's entry in the /etc/passwd file (take a look - the last
entry on each line is the user's shell).
[2] Most modern systems do not actually
copy all the memory when fork is called. Instead, they play a little
trick to be lazy (remember, lazy is always good). They have the
mapping functions for both the child and parent process point to the
same memory until such time as one of them makes a change. Only when a
change is made does the system copy the memory.
[3] The PCB is private to the kernel,
so the shell couldn't actually directly set the values. It can,
however, use a variety of syscalls to alter them in controlled ways.